
Text Embedding Models
Collection
A collection of text embedding models, in GGUF format. • 4 items • Updated
This page provides various quantisations of the base model, in GGUF format.
For a full model description, please refer to the base model's card.
After cloning the author's original base model repository, llama.cpp is used to convert the model to a GGML compatible file, using f32 as the output type; preserving the original fidelity. The model is converted un-altered, unless otherwise stated.
Finally, for each respective quantisation level, llama.cpp's llama-quantize executable is called using the F32 GGUF file as the source file.
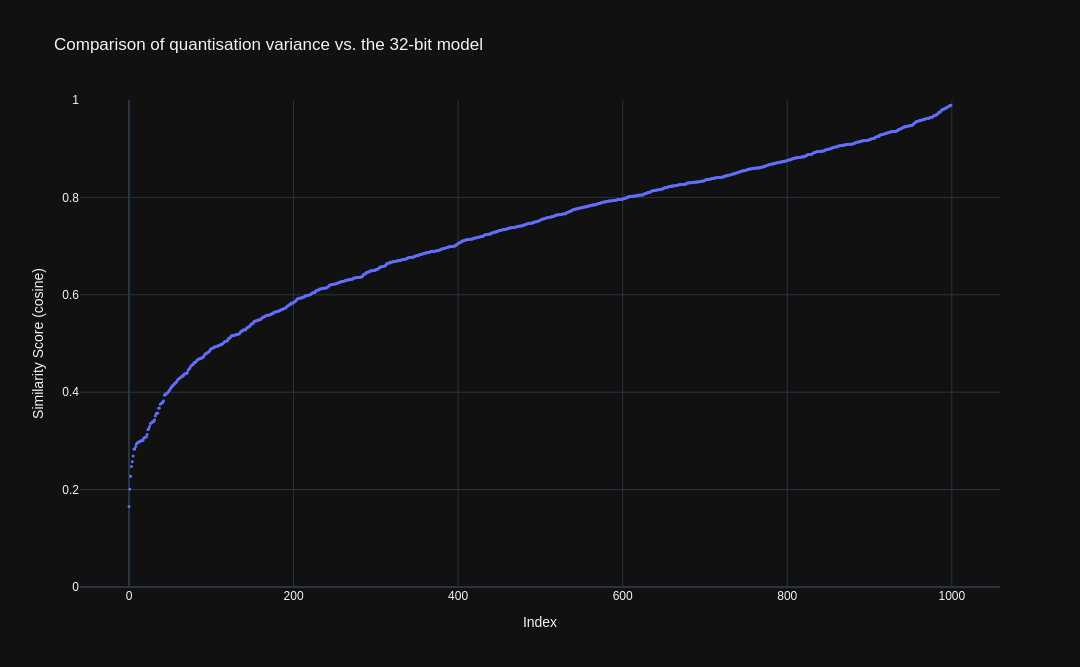
To help visualise the difference in model quantisation (i.e. level of retained fidelity), the image below shows the cosine similarity scores for each quantisation, baselined against the 32-bit base model. It can be observed that lower fidelity yields a wider scatter in scores, relative to the 32-bit model.
The underlying base dataset was sampled to 1000 records with a unbiased similarity score distribution. Using the various quantisation levels of this model, embeddings were created for sentence1 and sentence2. Finally, a cosine similarity score was calculated across the two embeddings, and plotted on the graph.
Note: This graph currently only features a single trend, which was created against the un-quantised 32-bit model. Although the quantised GGUF files are available, neither
sentence-transformersnorllama-cpp-pythonhave been updated to support thegemma-embeddingformat, so we can't use them (yet).As soon as support is available, we'll update this graph to display the fidelity for the quantisations.
2-bit
4-bit
5-bit
6-bit
8-bit
16-bit
32-bit
Base model
google/embeddinggemma-300m