
Text Generation Models
Collection
A collection of text generation models, in GGUF format. • 23 items • Updated
This model repository provides various quantisations of the following base model, in GGUF format.
For a full model description, please refer to the base model's card.
This model, and subsequent quantisations, have been converted directly from the author's base model unaltered.
After cloning the author's original base model repository, llama.cpp is used to convert the model to GGUF format, using --outtype=bf16 to preserve the original model's 16-bit fidelity.
Finally, for each subsequent quantisation level, llama.cpp's llama-quantize executable is called using the BF16 GGUF file as the source file.
The purpose of this repository is to provide unaltered quantisations of the author's base model. This section is designed to help the user visualise the difference in quantisation levels, in efforts to assist in model (quantisation) selection.
To aid a user in model/quantisation selection, the team has created the following statistics specifically for comparing the similarity scores across quantisation runs.
The dataset against which each run was conducted is composed of 175 question/answer pairs, divided amongst 7 topics, specifically designed to test a quantisation's processing ability. The test dataset was created by Mistral Large (via Le Chat) using prompts explicitly stating the requirement for the question/answer pairs to be designed for Mistral model quantisation testing.
The similarity scores used by these statistics were calculated as the cosine similarity between the embedding of the 'gold standard' answer provided in the dataset, and the embedding of the response from the quantised model. The embedding model used in these tests is the all-MiniLM-L6-v2 Q8_0.
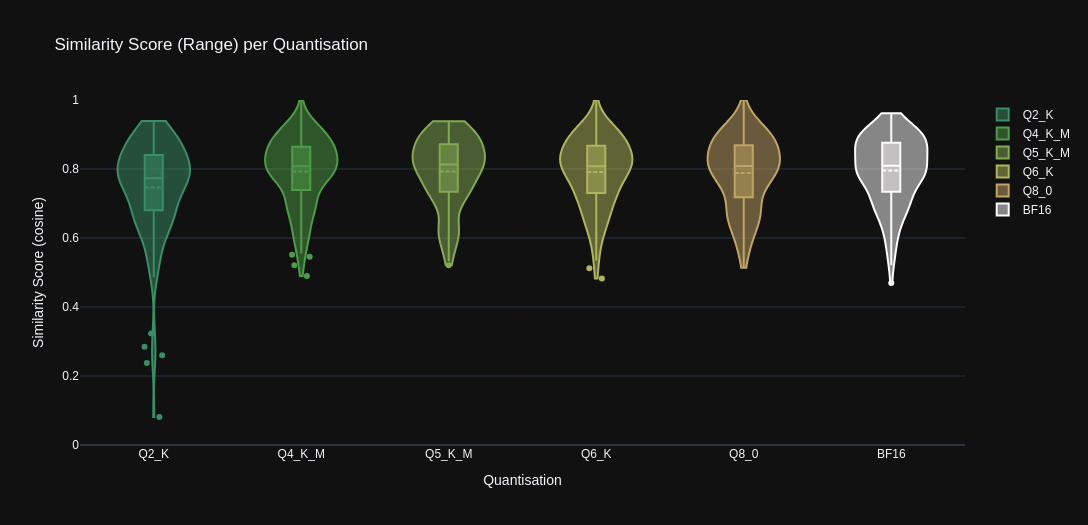
The range graph below illustrates how the range of similarity scores varies amongst the quantisation levels. Included in the range stats are the:
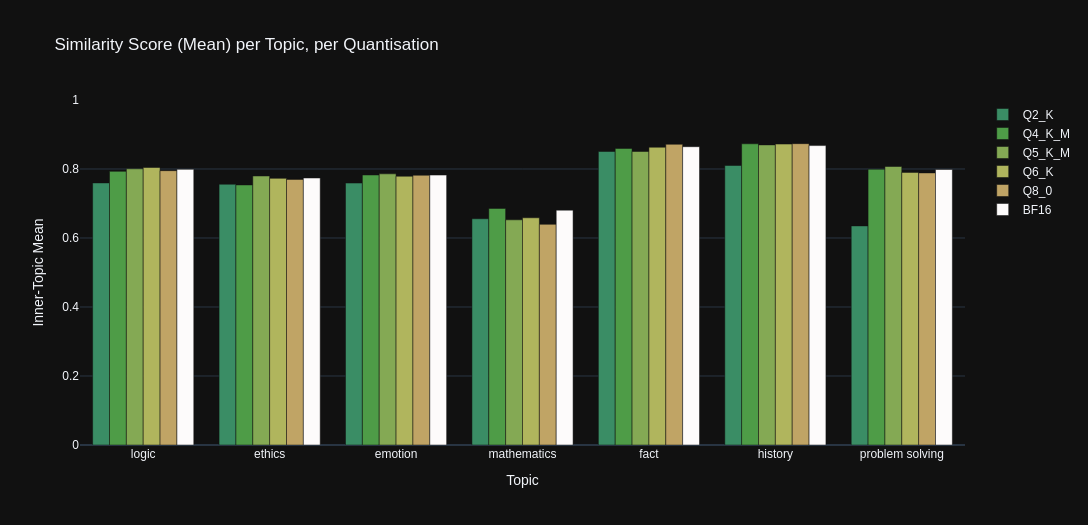
The mean graph below illustrates how the mean similarity scores (when grouped by 'topic') vary amongst the quantisation levels.
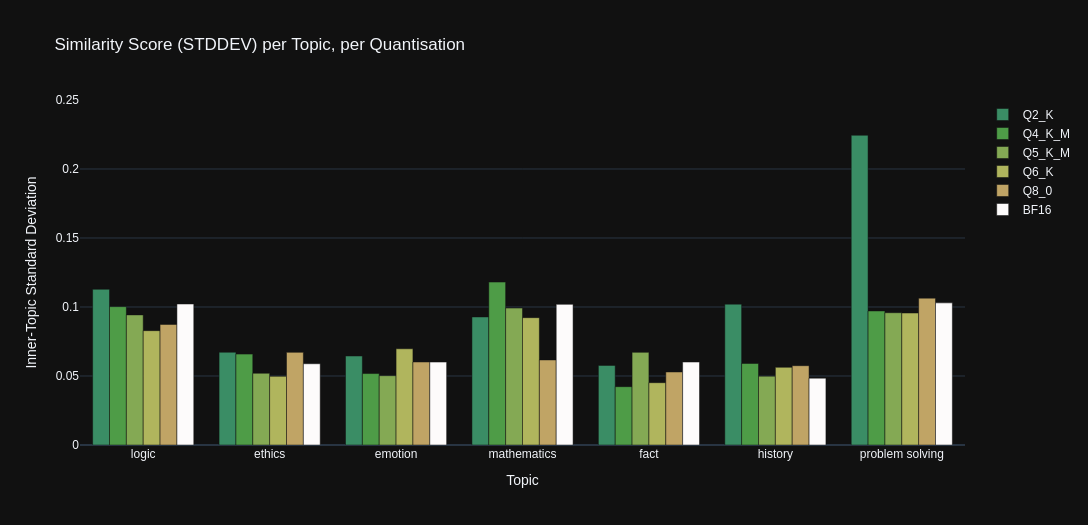
The standard deviation graph below illustrates the how spread of similarity scores vary amongst the quantisation levels, when grouped by the test dataset's 'topic' categories.
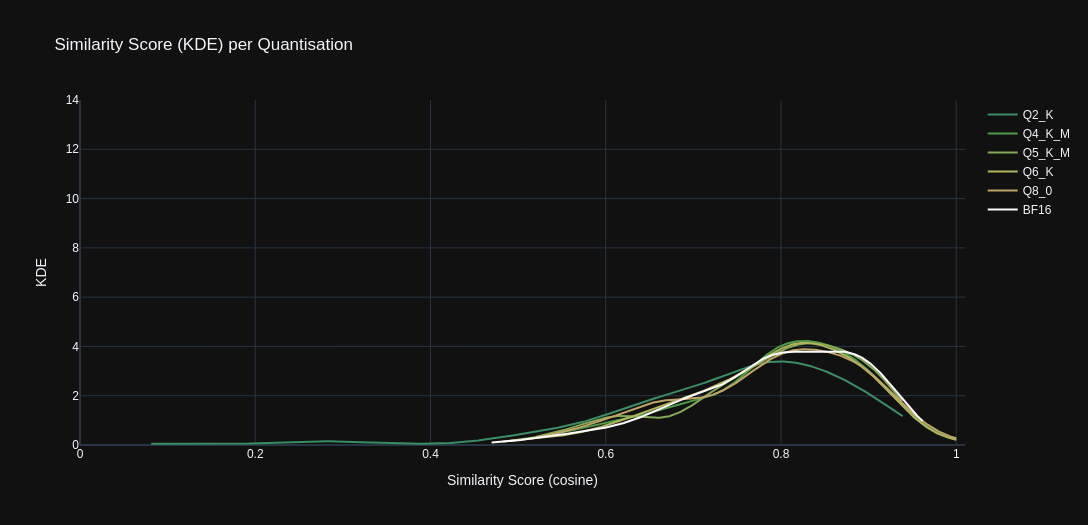
The KDE graph below illustrates the how distribution of similarity scores vary amongst the quantisation levels.
2-bit
4-bit
5-bit
6-bit
8-bit
16-bit
Base model
tiiuae/Falcon-H1-7B-Base