

🌟 Gemma 4 - 31B x Claude Opus 4.6
Build Environment & Features:
- Fine-tuning Framework: Unsloth
- Reasoning Effort: High
- This model bridges the gap between Google's exceptional open-weights architecture and Claude 4.6's profound reasoning capabilities, leveraging cutting-edge fine-tuning environments.
💡 Model Introduction
Gemma 4 - 31B x Claude Opus 4.6 is a highly capable model fine-tuned on top of the powerful unsloth/gemma-4-31B-it architecture. The model's core directive is to absorb state-of-the-art reasoning distillation, primarily sourced from Claude-4.6 Opus interactions.
By utilizing datasets where the reasoning effort was explicitly set to High, this model excels in breaking down complex problems and delivering precise, nuanced solutions across a variety of demanding domains.
🗺️ Training Pipeline Overview
Base Model (unsloth/gemma-4-31B-it)
│
▼
Supervised Fine-Tuning (SFT) + High-Effort Reasoning Datasets
│
▼
Final Model (Gemma 4 - 31B x Claude Opus 4.6)
📋 Stage Details & Benchmarks
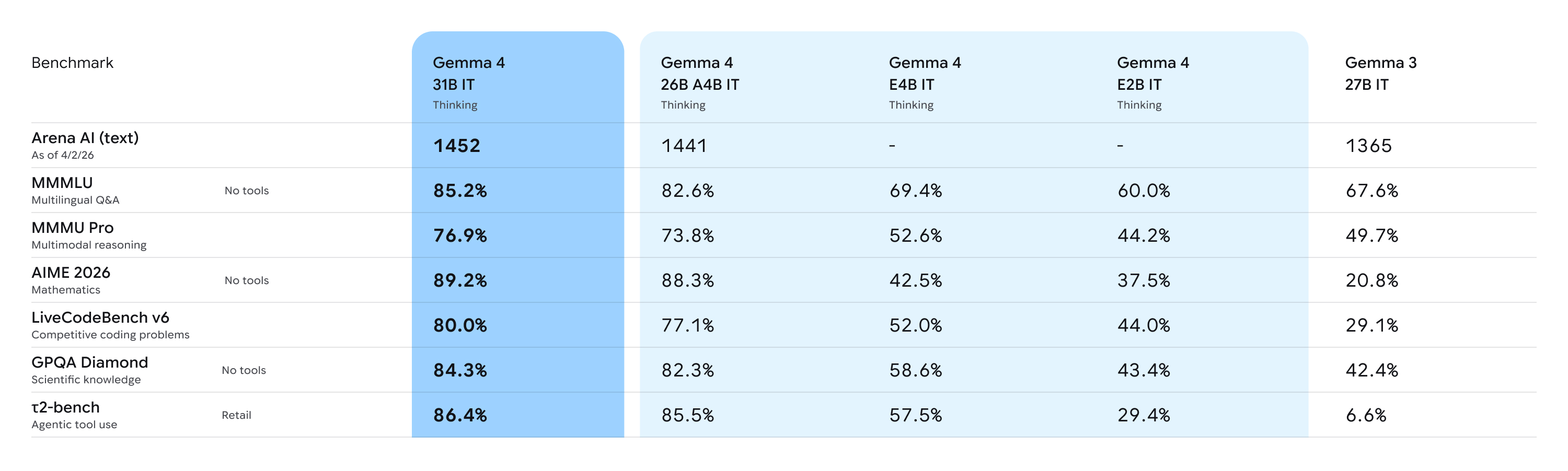
Performance vs Size:
Deep Dive Analysis: For more comprehensive insights regarding the base capabilities of the Gemma 4 architecture, please refer to this Analysis Document.
🔹 Supervised Fine-Tuning (Meeting Claude)
- Objective: To inject high-density reasoning logic and establish a strict format for complex problem-solving.
- Methodology: We utilized Unsloth for highly efficient memory and compute optimization during the fine-tuning process. The model was trained extensively on various reasoning trajectories from Claude Opus 4.6 to adopt a structured and efficient thinking pattern.
📚 All Datasets Used
The dataset consists of high-quality, high-effort reasoning distillation data:
| Dataset Name | Description / Purpose |
|---|---|
TeichAI/Claude-Opus-4.6-Reasoning-887x |
Core Claude 4.6 Opus reasoning trajectories. |
TeichAI/Claude-Sonnet-4.6-Reasoning-1100x |
Additional high-density reasoning instances from Claude 4.6 Sonnet. |
TeichAI/claude-4.5-opus-high-reasoning-250x |
Legacy high-intensity reasoning distillation. |
Crownelius/Opus-4.6-Reasoning-2100x-formatted |
Crownelius's extensively formatted Opus reasoning dataset for structural reinforcement. |
🌟 Core Skills & Capabilities
Thanks to its robust base model and high-effort reasoning distillation, this model is highly optimized for the following use cases:
- 💻 Coding: Advanced code generation, debugging, and software architecture planning.
- 🔬 Science: Deep scientific reasoning, hypothesis evaluation, and analytical problem-solving.
- 🔎 Deep Research: Navigating complex, multi-step research queries and synthesizing vast amounts of information.
- 🧠 General Purpose: Highly capable instruction-following for everyday tasks requiring high logical coherence.
🙏 Acknowledgements
- Google: For providing an exceptional open weights model. Read more about Gemma 4 on the Google Innovation Blog.
- Unsloth: For assembling ready-to-use, cutting-edge fine-tuning environments that make this work possible.
- Crownelius: For creating and sharing his awesome Opus reasoning dataset with the community.
📖 Citation
If you use this model in your research or projects, please cite:
@misc{teichai_gemma4_31b_opus_distilled,
title = {Gemma-4-31B-it-Claude-Opus-Distill},
author = {TeichAI},
year = {2026},
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/TeichAI/gemma-4-31B-it-Claude-Opus-Distill}}
}
- Downloads last month
- 101
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit