Hugging Face
Models
Datasets
Spaces
Buckets
new
Docs
Enterprise
Pricing
Website
Tasks
HuggingChat
Collections
Languages
Organizations
Community
Blog
Posts
Daily Papers
Learn
Discord
Forum
GitHub
Solutions
Team & Enterprise
Hugging Face PRO
Enterprise Support
Inference Providers
Inference Endpoints
Storage Buckets
Log In
Sign Up
kyaky
/
Qwen3.6-35B-A3B-NVFP4
like
1
Text Generation
Safetensors
qwen3_5_moe
nvfp4
fp4
llm-compressor
compressed-tensors
vllm
Mixture of Experts
quantized
conversational
8-bit precision
License:
apache-2.0
Model card
Files
Files and versions
xet
Community
Copy to bucket
new
main
Qwen3.6-35B-A3B-NVFP4
/
benchmark.png
kyaky
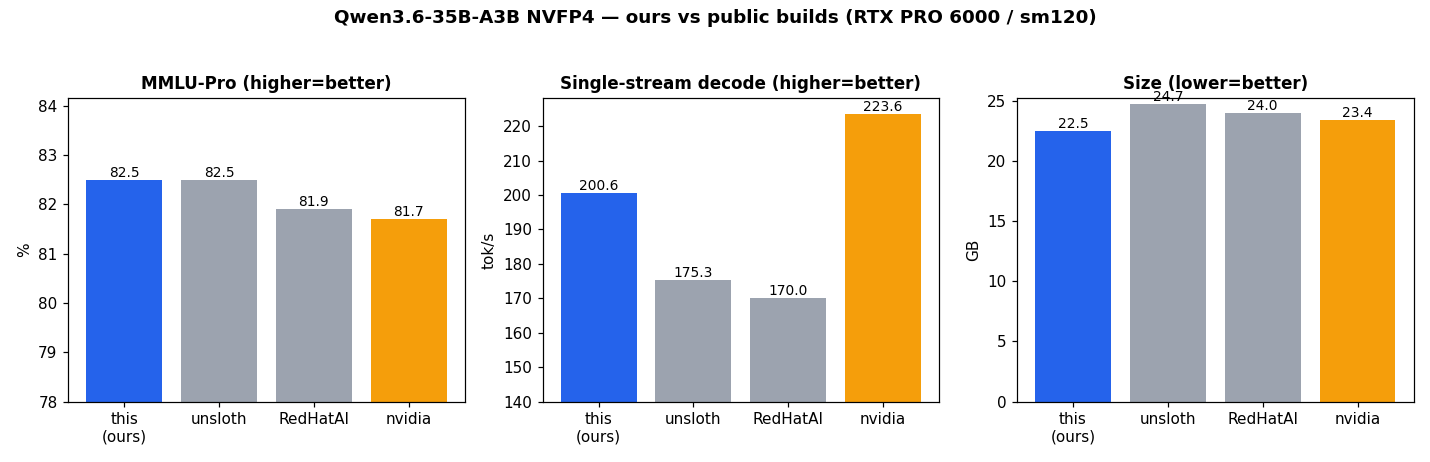
NVFP4 self-quant (llm-compressor): FP8 attn/GDN + NVFP4-W4A16 experts; beats redhat/unsloth on quality+speed+size
894cdfa
verified
4 days ago
Download
Download with hf CLI
Copy download link
History
Contribute
Delete
54.5 kB

{kind=link}
{kind=link}
{kind=link}
{kind=link}