
NVFP4 self-quant (llm-compressor): FP8 attn/GDN + NVFP4-W4A16 experts; beats redhat/unsloth on quality+speed+size
Browse files- .gitattributes +1 -0
- README.md +65 -0
- benchmark.png +0 -0
- chat_template.jinja +154 -0
- config.json +0 -0
- generation_config.json +13 -0
- model.safetensors +3 -0
- preprocessor_config.json +21 -0
- processor_config.json +60 -0
- recipe.yaml +60 -0
- tokenizer.json +3 -0
- tokenizer_config.json +32 -0
- video_preprocessor_config.json +21 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
base_model: Qwen/Qwen3.6-35B-A3B
|
| 4 |
+
base_model_relation: quantized
|
| 5 |
+
tags:
|
| 6 |
+
- nvfp4
|
| 7 |
+
- fp4
|
| 8 |
+
- llm-compressor
|
| 9 |
+
- compressed-tensors
|
| 10 |
+
- vllm
|
| 11 |
+
- moe
|
| 12 |
+
- qwen3_5_moe
|
| 13 |
+
language:
|
| 14 |
+
- en
|
| 15 |
+
pipeline_tag: text-generation
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# Qwen3.6-35B-A3B-NVFP4 (self-quantized, llm-compressor)
|
| 19 |
+
|
| 20 |
+
NVFP4 (4-bit) quantization of [Qwen/Qwen3.6-35B-A3B](https://huggingface.co/Qwen/Qwen3.6-35B-A3B), the hybrid
|
| 21 |
+
**Gated-DeltaNet + 256-expert MoE** model (35B total / 3B active, multimodal, thinking-by-default).
|
| 22 |
+
Produced in-house with **llm-compressor / compressed-tensors**, tuned for **NVIDIA Blackwell (sm120, RTX PRO 6000)**.
|
| 23 |
+
|
| 24 |
+
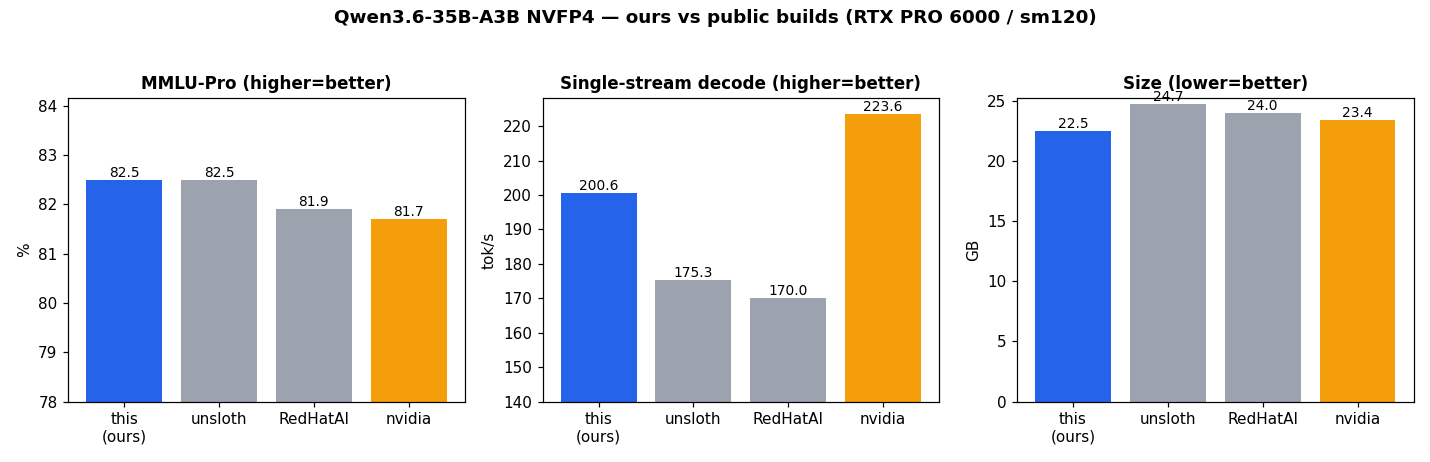
**22.5 GB** (≈3× smaller than the 67 GB BF16 base) — the **smallest** of the public NVFP4 builds, while matching or
|
| 25 |
+
beating them on quality and beating two of three on speed.
|
| 26 |
+
|
| 27 |
+
## Recipe (mixed-precision)
|
| 28 |
+
|
| 29 |
+
| Component | Precision |
|
| 30 |
+
|---|---|
|
| 31 |
+
| Routed experts (256/layer, fused) | **NVFP4 weight-only (W4A16)** group-16 |
|
| 32 |
+
| Self-attention q/k/v/o + GDN `in_proj_*`/`out_proj` + shared-expert | **FP8** (W8A8, block-128 weight / dynamic group-128 act) |
|
| 33 |
+
| Routers, `lm_head`, embeddings, conv1d/SSM, vision tower, MTP | **BF16** |
|
| 34 |
+
|
| 35 |
+
Why weight-only NVFP4 on experts: on sm120 the native FP4 MoE GEMM is unavailable, so all NVFP4 experts serve via the
|
| 36 |
+
**Marlin W4A16** path regardless — W4A16 therefore gives the same speed as W4A4 with less quantization error.
|
| 37 |
+
Calibrated with `moe_calibrate_all_experts=True` (every one of the 256 experts receives stats).
|
| 38 |
+
|
| 39 |
+
## Benchmarks (measured on RTX PRO 6000 / sm120, vLLM 0.23)
|
| 40 |
+
|
| 41 |
+
lm-eval (thinking-on, `max_gen_toks=8192`, flexible-extract); speed from engine `/metrics`, TP1 solo.
|
| 42 |
+
|
| 43 |
+
| Build | MMLU-Pro | GSM8K | single-stream tok/s | N16 tok/s | size |
|
| 44 |
+
|---|---|---|---|---|---|
|
| 45 |
+
| **this model (our self-quant)** | **0.825** | **0.920** | 200.6 | 1581 | **22.5 GB** |
|
| 46 |
+
| unsloth/…-NVFP4 | 0.825 | 0.890 | 175.3 | 1493 | 24.7 GB |
|
| 47 |
+
| RedHatAI/…-NVFP4 | 0.819 | 0.910 | 170.0 | 1422 | 24.0 GB |
|
| 48 |
+
| nvidia/…-NVFP4 | 0.817 | 0.910 | **223.6** | **1646** | 23.4 GB |
|
| 49 |
+
|
| 50 |
+

|
| 51 |
+
|
| 52 |
+
- **Pareto-dominates** RedHatAI & unsloth on quality, speed, *and* size.
|
| 53 |
+
- **Tied-best quality** (top GSM8K, tied-top MMLU-Pro); **smallest** build.
|
| 54 |
+
- nvidia keeps the single-stream/concurrent speed crown (it sits on the sm120 hardware optimum — FP8-attn + W4A16-experts via Marlin); this build matches its scheme and trails only on raw decode throughput.
|
| 55 |
+
|
| 56 |
+
## Serving (vLLM ≥ 0.23)
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
vllm serve <this-repo> --served-model-name qwen3.6-35b-a3b-nvfp4 \
|
| 60 |
+
--max-model-len 262144 --gpu-memory-utilization 0.90 \
|
| 61 |
+
--trust-remote-code --reasoning-parser qwen3 \
|
| 62 |
+
--enable-auto-tool-choice --tool-call-parser qwen3_xml
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
Quantized by `kyaky` with llm-compressor. Base model © Qwen, Apache-2.0.
|
benchmark.png
ADDED
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- set image_count = namespace(value=0) %}
|
| 2 |
+
{%- set video_count = namespace(value=0) %}
|
| 3 |
+
{%- macro render_content(content, do_vision_count, is_system_content=false) %}
|
| 4 |
+
{%- if content is string %}
|
| 5 |
+
{{- content }}
|
| 6 |
+
{%- elif content is iterable and content is not mapping %}
|
| 7 |
+
{%- for item in content %}
|
| 8 |
+
{%- if 'image' in item or 'image_url' in item or item.type == 'image' %}
|
| 9 |
+
{%- if is_system_content %}
|
| 10 |
+
{{- raise_exception('System message cannot contain images.') }}
|
| 11 |
+
{%- endif %}
|
| 12 |
+
{%- if do_vision_count %}
|
| 13 |
+
{%- set image_count.value = image_count.value + 1 %}
|
| 14 |
+
{%- endif %}
|
| 15 |
+
{%- if add_vision_id %}
|
| 16 |
+
{{- 'Picture ' ~ image_count.value ~ ': ' }}
|
| 17 |
+
{%- endif %}
|
| 18 |
+
{{- '<|vision_start|><|image_pad|><|vision_end|>' }}
|
| 19 |
+
{%- elif 'video' in item or item.type == 'video' %}
|
| 20 |
+
{%- if is_system_content %}
|
| 21 |
+
{{- raise_exception('System message cannot contain videos.') }}
|
| 22 |
+
{%- endif %}
|
| 23 |
+
{%- if do_vision_count %}
|
| 24 |
+
{%- set video_count.value = video_count.value + 1 %}
|
| 25 |
+
{%- endif %}
|
| 26 |
+
{%- if add_vision_id %}
|
| 27 |
+
{{- 'Video ' ~ video_count.value ~ ': ' }}
|
| 28 |
+
{%- endif %}
|
| 29 |
+
{{- '<|vision_start|><|video_pad|><|vision_end|>' }}
|
| 30 |
+
{%- elif 'text' in item %}
|
| 31 |
+
{{- item.text }}
|
| 32 |
+
{%- else %}
|
| 33 |
+
{{- raise_exception('Unexpected item type in content.') }}
|
| 34 |
+
{%- endif %}
|
| 35 |
+
{%- endfor %}
|
| 36 |
+
{%- elif content is none or content is undefined %}
|
| 37 |
+
{{- '' }}
|
| 38 |
+
{%- else %}
|
| 39 |
+
{{- raise_exception('Unexpected content type.') }}
|
| 40 |
+
{%- endif %}
|
| 41 |
+
{%- endmacro %}
|
| 42 |
+
{%- if not messages %}
|
| 43 |
+
{{- raise_exception('No messages provided.') }}
|
| 44 |
+
{%- endif %}
|
| 45 |
+
{%- if tools and tools is iterable and tools is not mapping %}
|
| 46 |
+
{{- '<|im_start|>system\n' }}
|
| 47 |
+
{{- "# Tools\n\nYou have access to the following functions:\n\n<tools>" }}
|
| 48 |
+
{%- for tool in tools %}
|
| 49 |
+
{{- "\n" }}
|
| 50 |
+
{{- tool | tojson }}
|
| 51 |
+
{%- endfor %}
|
| 52 |
+
{{- "\n</tools>" }}
|
| 53 |
+
{{- '\n\nIf you choose to call a function ONLY reply in the following format with NO suffix:\n\n<tool_call>\n<function=example_function_name>\n<parameter=example_parameter_1>\nvalue_1\n</parameter>\n<parameter=example_parameter_2>\nThis is the value for the second parameter\nthat can span\nmultiple lines\n</parameter>\n</function>\n</tool_call>\n\n<IMPORTANT>\nReminder:\n- Function calls MUST follow the specified format: an inner <function=...></function> block must be nested within <tool_call></tool_call> XML tags\n- Required parameters MUST be specified\n- You may provide optional reasoning for your function call in natural language BEFORE the function call, but NOT after\n- If there is no function call available, answer the question like normal with your current knowledge and do not tell the user about function calls\n</IMPORTANT>' }}
|
| 54 |
+
{%- if messages[0].role == 'system' %}
|
| 55 |
+
{%- set content = render_content(messages[0].content, false, true)|trim %}
|
| 56 |
+
{%- if content %}
|
| 57 |
+
{{- '\n\n' + content }}
|
| 58 |
+
{%- endif %}
|
| 59 |
+
{%- endif %}
|
| 60 |
+
{{- '<|im_end|>\n' }}
|
| 61 |
+
{%- else %}
|
| 62 |
+
{%- if messages[0].role == 'system' %}
|
| 63 |
+
{%- set content = render_content(messages[0].content, false, true)|trim %}
|
| 64 |
+
{{- '<|im_start|>system\n' + content + '<|im_end|>\n' }}
|
| 65 |
+
{%- endif %}
|
| 66 |
+
{%- endif %}
|
| 67 |
+
{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}
|
| 68 |
+
{%- for message in messages[::-1] %}
|
| 69 |
+
{%- set index = (messages|length - 1) - loop.index0 %}
|
| 70 |
+
{%- if ns.multi_step_tool and message.role == "user" %}
|
| 71 |
+
{%- set content = render_content(message.content, false)|trim %}
|
| 72 |
+
{%- if not(content.startswith('<tool_response>') and content.endswith('</tool_response>')) %}
|
| 73 |
+
{%- set ns.multi_step_tool = false %}
|
| 74 |
+
{%- set ns.last_query_index = index %}
|
| 75 |
+
{%- endif %}
|
| 76 |
+
{%- endif %}
|
| 77 |
+
{%- endfor %}
|
| 78 |
+
{%- if ns.multi_step_tool %}
|
| 79 |
+
{{- raise_exception('No user query found in messages.') }}
|
| 80 |
+
{%- endif %}
|
| 81 |
+
{%- for message in messages %}
|
| 82 |
+
{%- set content = render_content(message.content, true)|trim %}
|
| 83 |
+
{%- if message.role == "system" %}
|
| 84 |
+
{%- if not loop.first %}
|
| 85 |
+
{{- raise_exception('System message must be at the beginning.') }}
|
| 86 |
+
{%- endif %}
|
| 87 |
+
{%- elif message.role == "user" %}
|
| 88 |
+
{{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }}
|
| 89 |
+
{%- elif message.role == "assistant" %}
|
| 90 |
+
{%- set reasoning_content = '' %}
|
| 91 |
+
{%- if message.reasoning_content is string %}
|
| 92 |
+
{%- set reasoning_content = message.reasoning_content %}
|
| 93 |
+
{%- else %}
|
| 94 |
+
{%- if '</think>' in content %}
|
| 95 |
+
{%- set reasoning_content = content.split('</think>')[0].rstrip('\n').split('<think>')[-1].lstrip('\n') %}
|
| 96 |
+
{%- set content = content.split('</think>')[-1].lstrip('\n') %}
|
| 97 |
+
{%- endif %}
|
| 98 |
+
{%- endif %}
|
| 99 |
+
{%- set reasoning_content = reasoning_content|trim %}
|
| 100 |
+
{%- if (preserve_thinking is defined and preserve_thinking is true) or (loop.index0 > ns.last_query_index) %}
|
| 101 |
+
{{- '<|im_start|>' + message.role + '\n<think>\n' + reasoning_content + '\n</think>\n\n' + content }}
|
| 102 |
+
{%- else %}
|
| 103 |
+
{{- '<|im_start|>' + message.role + '\n' + content }}
|
| 104 |
+
{%- endif %}
|
| 105 |
+
{%- if message.tool_calls and message.tool_calls is iterable and message.tool_calls is not mapping %}
|
| 106 |
+
{%- for tool_call in message.tool_calls %}
|
| 107 |
+
{%- if tool_call.function is defined %}
|
| 108 |
+
{%- set tool_call = tool_call.function %}
|
| 109 |
+
{%- endif %}
|
| 110 |
+
{%- if loop.first %}
|
| 111 |
+
{%- if content|trim %}
|
| 112 |
+
{{- '\n\n<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 113 |
+
{%- else %}
|
| 114 |
+
{{- '<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 115 |
+
{%- endif %}
|
| 116 |
+
{%- else %}
|
| 117 |
+
{{- '\n<tool_call>\n<function=' + tool_call.name + '>\n' }}
|
| 118 |
+
{%- endif %}
|
| 119 |
+
{%- if tool_call.arguments is defined %}
|
| 120 |
+
{%- for args_name, args_value in tool_call.arguments|items %}
|
| 121 |
+
{{- '<parameter=' + args_name + '>\n' }}
|
| 122 |
+
{%- set args_value = args_value | string if args_value is string else args_value | tojson | safe %}
|
| 123 |
+
{{- args_value }}
|
| 124 |
+
{{- '\n</parameter>\n' }}
|
| 125 |
+
{%- endfor %}
|
| 126 |
+
{%- endif %}
|
| 127 |
+
{{- '</function>\n</tool_call>' }}
|
| 128 |
+
{%- endfor %}
|
| 129 |
+
{%- endif %}
|
| 130 |
+
{{- '<|im_end|>\n' }}
|
| 131 |
+
{%- elif message.role == "tool" %}
|
| 132 |
+
{%- if loop.previtem and loop.previtem.role != "tool" %}
|
| 133 |
+
{{- '<|im_start|>user' }}
|
| 134 |
+
{%- endif %}
|
| 135 |
+
{{- '\n<tool_response>\n' }}
|
| 136 |
+
{{- content }}
|
| 137 |
+
{{- '\n</tool_response>' }}
|
| 138 |
+
{%- if not loop.last and loop.nextitem.role != "tool" %}
|
| 139 |
+
{{- '<|im_end|>\n' }}
|
| 140 |
+
{%- elif loop.last %}
|
| 141 |
+
{{- '<|im_end|>\n' }}
|
| 142 |
+
{%- endif %}
|
| 143 |
+
{%- else %}
|
| 144 |
+
{{- raise_exception('Unexpected message role.') }}
|
| 145 |
+
{%- endif %}
|
| 146 |
+
{%- endfor %}
|
| 147 |
+
{%- if add_generation_prompt %}
|
| 148 |
+
{{- '<|im_start|>assistant\n' }}
|
| 149 |
+
{%- if enable_thinking is defined and enable_thinking is false %}
|
| 150 |
+
{{- '<think>\n\n</think>\n\n' }}
|
| 151 |
+
{%- else %}
|
| 152 |
+
{{- '<think>\n' }}
|
| 153 |
+
{%- endif %}
|
| 154 |
+
{%- endif %}
|
config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 248044,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
248046,
|
| 6 |
+
248044
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 248044,
|
| 9 |
+
"temperature": 1.0,
|
| 10 |
+
"top_k": 20,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "5.10.1"
|
| 13 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58d5f4d578092478b746ae99849b28166207fce38ec0380e840d502ba0cb5971
|
| 3 |
+
size 22517775624
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {
|
| 3 |
+
"longest_edge": 16777216,
|
| 4 |
+
"shortest_edge": 65536
|
| 5 |
+
},
|
| 6 |
+
"patch_size": 16,
|
| 7 |
+
"temporal_patch_size": 2,
|
| 8 |
+
"merge_size": 2,
|
| 9 |
+
"image_mean": [
|
| 10 |
+
0.5,
|
| 11 |
+
0.5,
|
| 12 |
+
0.5
|
| 13 |
+
],
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.5,
|
| 16 |
+
0.5,
|
| 17 |
+
0.5
|
| 18 |
+
],
|
| 19 |
+
"processor_class": "Qwen3VLProcessor",
|
| 20 |
+
"image_processor_type": "Qwen2VLImageProcessorFast"
|
| 21 |
+
}
|
processor_config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_processor": {
|
| 3 |
+
"do_convert_rgb": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_rescale": true,
|
| 6 |
+
"do_resize": true,
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.5,
|
| 9 |
+
0.5,
|
| 10 |
+
0.5
|
| 11 |
+
],
|
| 12 |
+
"image_processor_type": "Qwen2VLImageProcessor",
|
| 13 |
+
"image_std": [
|
| 14 |
+
0.5,
|
| 15 |
+
0.5,
|
| 16 |
+
0.5
|
| 17 |
+
],
|
| 18 |
+
"merge_size": 2,
|
| 19 |
+
"patch_size": 16,
|
| 20 |
+
"resample": 3,
|
| 21 |
+
"rescale_factor": 0.00392156862745098,
|
| 22 |
+
"size": {
|
| 23 |
+
"longest_edge": 16777216,
|
| 24 |
+
"shortest_edge": 65536
|
| 25 |
+
},
|
| 26 |
+
"temporal_patch_size": 2
|
| 27 |
+
},
|
| 28 |
+
"processor_class": "Qwen3VLProcessor",
|
| 29 |
+
"video_processor": {
|
| 30 |
+
"do_convert_rgb": true,
|
| 31 |
+
"do_normalize": true,
|
| 32 |
+
"do_rescale": true,
|
| 33 |
+
"do_resize": true,
|
| 34 |
+
"do_sample_frames": true,
|
| 35 |
+
"fps": 2,
|
| 36 |
+
"image_mean": [
|
| 37 |
+
0.5,
|
| 38 |
+
0.5,
|
| 39 |
+
0.5
|
| 40 |
+
],
|
| 41 |
+
"image_std": [
|
| 42 |
+
0.5,
|
| 43 |
+
0.5,
|
| 44 |
+
0.5
|
| 45 |
+
],
|
| 46 |
+
"max_frames": 768,
|
| 47 |
+
"merge_size": 2,
|
| 48 |
+
"min_frames": 4,
|
| 49 |
+
"patch_size": 16,
|
| 50 |
+
"resample": 3,
|
| 51 |
+
"rescale_factor": 0.00392156862745098,
|
| 52 |
+
"return_metadata": false,
|
| 53 |
+
"size": {
|
| 54 |
+
"longest_edge": 25165824,
|
| 55 |
+
"shortest_edge": 4096
|
| 56 |
+
},
|
| 57 |
+
"temporal_patch_size": 2,
|
| 58 |
+
"video_processor_type": "Qwen3VLVideoProcessor"
|
| 59 |
+
}
|
| 60 |
+
}
|
recipe.yaml
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
quant_stage:
|
| 2 |
+
quant_modifiers:
|
| 3 |
+
QuantizationModifier:
|
| 4 |
+
config_groups:
|
| 5 |
+
group_0:
|
| 6 |
+
targets: ['re:.*self_attn.q_proj.*', 're:.*self_attn.k_proj.*', 're:.*self_attn.v_proj.*',
|
| 7 |
+
're:.*self_attn.o_proj.*', 're:.*linear_attn.in_proj_qkv.*', 're:.*linear_attn.in_proj_z.*',
|
| 8 |
+
're:.*linear_attn.out_proj.*', 're:.*shared_expert.gate_proj.*', 're:.*shared_expert.up_proj.*',
|
| 9 |
+
're:.*shared_expert.down_proj.*']
|
| 10 |
+
weights:
|
| 11 |
+
num_bits: 8
|
| 12 |
+
type: float
|
| 13 |
+
symmetric: true
|
| 14 |
+
group_size: null
|
| 15 |
+
strategy: block
|
| 16 |
+
block_structure: [128, 128]
|
| 17 |
+
dynamic: false
|
| 18 |
+
actorder: null
|
| 19 |
+
scale_dtype: null
|
| 20 |
+
zp_dtype: null
|
| 21 |
+
observer: memoryless_minmax
|
| 22 |
+
observer_kwargs: {}
|
| 23 |
+
input_activations:
|
| 24 |
+
num_bits: 8
|
| 25 |
+
type: float
|
| 26 |
+
symmetric: true
|
| 27 |
+
group_size: 128
|
| 28 |
+
strategy: group
|
| 29 |
+
block_structure: null
|
| 30 |
+
dynamic: true
|
| 31 |
+
actorder: null
|
| 32 |
+
scale_dtype: null
|
| 33 |
+
zp_dtype: null
|
| 34 |
+
observer: null
|
| 35 |
+
observer_kwargs: {}
|
| 36 |
+
output_activations: null
|
| 37 |
+
format: null
|
| 38 |
+
group_1:
|
| 39 |
+
targets: ['re:.*mlp.experts.*gate_proj.*', 're:.*mlp.experts.*up_proj.*', 're:.*mlp.experts.*down_proj.*']
|
| 40 |
+
weights:
|
| 41 |
+
num_bits: 4
|
| 42 |
+
type: float
|
| 43 |
+
symmetric: true
|
| 44 |
+
group_size: 16
|
| 45 |
+
strategy: tensor_group
|
| 46 |
+
block_structure: null
|
| 47 |
+
dynamic: false
|
| 48 |
+
actorder: null
|
| 49 |
+
scale_dtype: torch.float8_e4m3fn
|
| 50 |
+
zp_dtype: null
|
| 51 |
+
observer: memoryless_minmax
|
| 52 |
+
observer_kwargs: {}
|
| 53 |
+
input_activations: null
|
| 54 |
+
output_activations: null
|
| 55 |
+
format: null
|
| 56 |
+
targets: [Linear]
|
| 57 |
+
ignore: ['re:.*lm_head', 're:.*embed_tokens', 're:visual.*', 're:model.visual.*', 're:.*mlp.gate$',
|
| 58 |
+
're:.*shared_expert_gate$', 're:.*linear_attn.in_proj_a', 're:.*linear_attn.in_proj_b',
|
| 59 |
+
're:.*linear_attn.conv1d', 're:^mtp\..*']
|
| 60 |
+
bypass_divisibility_checks: false
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f399b3cd12fa270d51457bb749fb30863521e8359b8a27059c71b6c2f7d6dd6c
|
| 3 |
+
size 19989424
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"audio_bos_token": "<|audio_start|>",
|
| 4 |
+
"audio_eos_token": "<|audio_end|>",
|
| 5 |
+
"audio_token": "<|audio_pad|>",
|
| 6 |
+
"backend": "tokenizers",
|
| 7 |
+
"bos_token": null,
|
| 8 |
+
"clean_up_tokenization_spaces": false,
|
| 9 |
+
"eos_token": "<|im_end|>",
|
| 10 |
+
"errors": "replace",
|
| 11 |
+
"image_token": "<|image_pad|>",
|
| 12 |
+
"is_local": true,
|
| 13 |
+
"local_files_only": true,
|
| 14 |
+
"model_max_length": 262144,
|
| 15 |
+
"model_specific_special_tokens": {
|
| 16 |
+
"audio_bos_token": "<|audio_start|>",
|
| 17 |
+
"audio_eos_token": "<|audio_end|>",
|
| 18 |
+
"audio_token": "<|audio_pad|>",
|
| 19 |
+
"image_token": "<|image_pad|>",
|
| 20 |
+
"video_token": "<|video_pad|>",
|
| 21 |
+
"vision_bos_token": "<|vision_start|>",
|
| 22 |
+
"vision_eos_token": "<|vision_end|>"
|
| 23 |
+
},
|
| 24 |
+
"pad_token": "<|endoftext|>",
|
| 25 |
+
"pretokenize_regex": "(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?[\\p{L}\\p{M}]+|\\p{N}| ?[^\\s\\p{L}\\p{M}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+",
|
| 26 |
+
"split_special_tokens": false,
|
| 27 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 28 |
+
"unk_token": null,
|
| 29 |
+
"video_token": "<|video_pad|>",
|
| 30 |
+
"vision_bos_token": "<|vision_start|>",
|
| 31 |
+
"vision_eos_token": "<|vision_end|>"
|
| 32 |
+
}
|
video_preprocessor_config.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {
|
| 3 |
+
"longest_edge": 25165824,
|
| 4 |
+
"shortest_edge": 4096
|
| 5 |
+
},
|
| 6 |
+
"patch_size": 16,
|
| 7 |
+
"temporal_patch_size": 2,
|
| 8 |
+
"merge_size": 2,
|
| 9 |
+
"image_mean": [
|
| 10 |
+
0.5,
|
| 11 |
+
0.5,
|
| 12 |
+
0.5
|
| 13 |
+
],
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.5,
|
| 16 |
+
0.5,
|
| 17 |
+
0.5
|
| 18 |
+
],
|
| 19 |
+
"processor_class": "Qwen3VLProcessor",
|
| 20 |
+
"video_processor_type": "Qwen3VLVideoProcessor"
|
| 21 |
+
}
|