
DASHQ
Collection
58 items • Updated • 1
# Load model directly
from transformers import AutoProcessor, AutoModelForMultimodalLM
processor = AutoProcessor.from_pretrained("jkim96/Qwen3.5-35B-A3B-DASHQ-INT4-g32")
model = AutoModelForMultimodalLM.from_pretrained("jkim96/Qwen3.5-35B-A3B-DASHQ-INT4-g32")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(processor.decode(outputs[0][inputs["input_ids"].shape[-1]:]))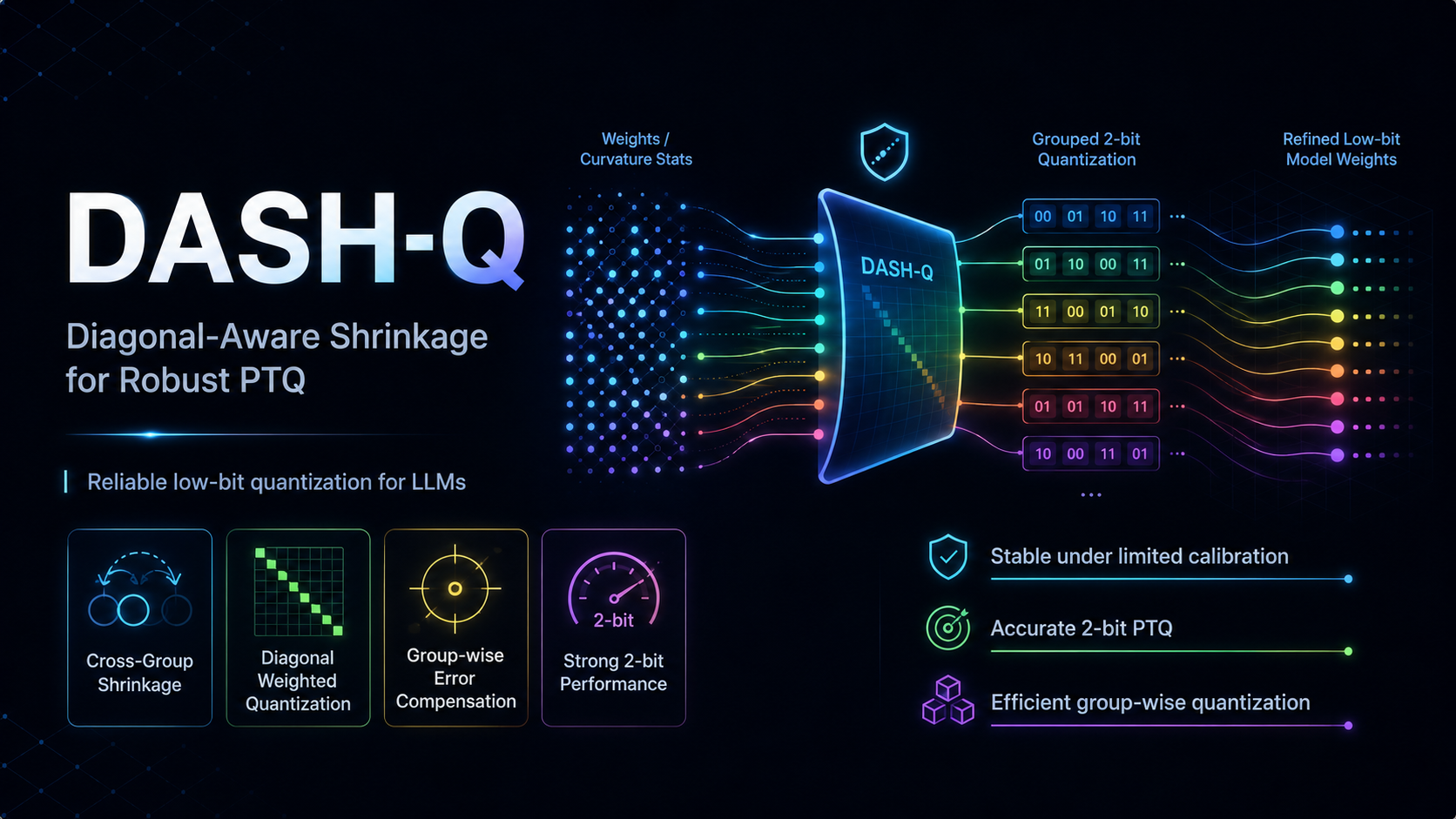
DASH-Q — Diagonal-Aware Shrinkage for Robust PTQ.
INT4· group size 32 · 23.9941 GB (from 71.9039 GB — 3.0x smaller)
DASH-Q checkpoints load with the lightweight DASH-Q runtime — linear layers are packed PackedQuantizedLinear modules, not plain Transformers weights.
pip install git+https://github.com/JaeminK/dashq.git
from dashq import load_quantized
model, tokenizer = load_quantized("jkim96/Qwen3.5-35B-A3B-DASHQ-INT4-g32", device_map="auto")
| Field | Value |
|---|---|
| Base model | Qwen/Qwen3.5-35B-A3B |
| Precision | INT4, group size 32 |
| Scale / zero dtype | float16 |
| Calibration | wikitext2, 128 samples x 2048 |
| Size | 23.9941 GB · original 71.9039 GB · 3.0x compression |
Full zero-shot / few-shot results for every DASH-Q checkpoint: github.com/JaeminK/dashq#benchmarks
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("image-text-to-text", model="jkim96/Qwen3.5-35B-A3B-DASHQ-INT4-g32") messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"}, {"type": "text", "text": "What animal is on the candy?"} ] }, ] pipe(text=messages)