
output = llm(
"Once upon a time,",
max_tokens=512,
echo=True
)
print(output)FLAN-T5-XXL Fused Model
Guide (External Site): English | Japanese
Why Use FP32 Text Encoder? (External Site): English | Japanese
This repository hosts a fused version of the FLAN-T5-XXL model, created by combining the split files from Google's FLAN-T5-XXL repository. The files have been merged for convenience, making it easier to integrate into AI applications, including image generation workflows.


Base Model: blue_pencil-flux1_v0.0.1
Key Features
- Fused for Simplicity: Combines split model files into a single, ready-to-use format.
- Optimized Variants: Available in FP32, FP16, FP8, and quantized GGUF formats to balance accuracy and resource usage.
- Enhanced Prompt Accuracy: Outperforms the standard T5-XXL v1.1 in generating precise outputs for image generation tasks.
Model Variants
| Model | Size | SSIM Similarity | Recommended |
|---|---|---|---|
| FP32 | 19 GB | 100.0% | 🌟 |
| FP16 | 9.6 GB | 98.0% | ✅ |
| FP8 | 4.8 GB | 95.3% | 🔺 |
| Q8_0 | 5.1 GB | 97.6% | ✅ |
| Q6_K | 4.0 GB | 97.3% | 🔺 |
| Q5_K_M | 3.4 GB | 94.8% | |
| Q4_K_M | 2.9 GB | 96.4% |
Comparison Graph
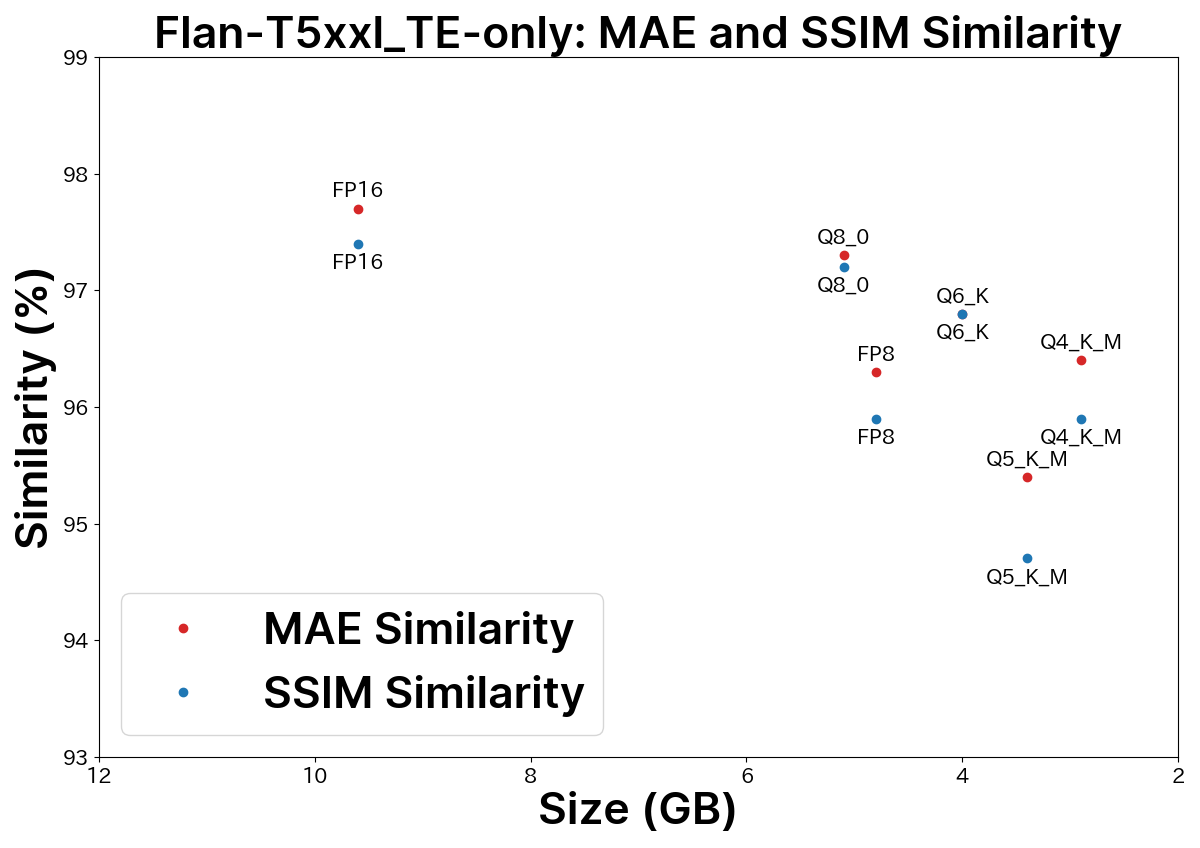
For a detailed comparison, refer to this blog post.
Usage Instructions
Place the downloaded model files in one of the following directories:
models/text_encodermodels/clipModels/CLIP
ComfyUI
When using Flux.1 in ComfyUI, load the text encoder with the DualCLIPLoader node.
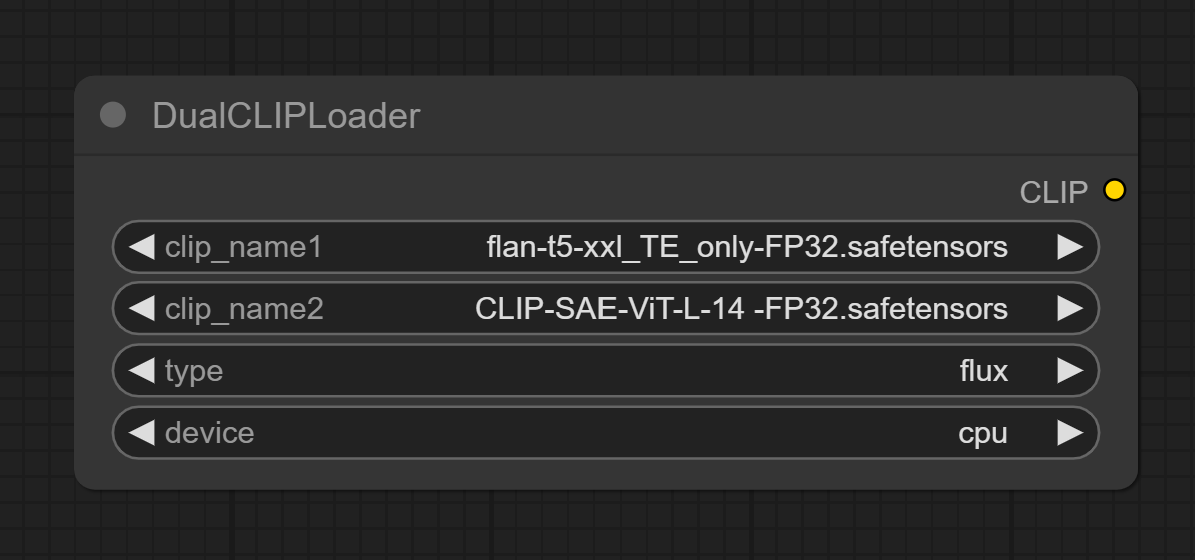
As of April 13, 2025, the default DualCLIPLoader node includes a device selection option, allowing you to choose where to load the model:
cuda→ VRAMcpu→ System RAM
Since Flux.1’s text encoder is large, setting the device to cpu and storing the model in system RAM often improves performance. Unless your system RAM is 16GB or less, keeping the model in system RAM is more effective than GGUF quantization. Thus, GGUF formats offer limited benefits in ComfyUI for most users due to sufficient RAM availability.
(More about ComfyUI settings.)
You can also use FP32 text encoders for optimal results by enabling the --fp32-text-enc argument at startup.
Stable Diffusion WebUI Forge
In Stable Diffusion WebUI Forge, select the FLAN-T5-XXL model instead of the default T5xxl_v1_1 text encoder.

To use the text encoder in FP32 format, launch Stable Diffusion WebUI Forge with the --clip-in-fp32 argument.
Comparison: FLAN-T5-XXL vs T5-XXL v1.1


These example images were generated using FLAN-T5-XXL and T5-XXL v1.1 models in Flux.1. FLAN-T5-XXL delivers more accurate responses to prompts.
Further Comparisons
License
- This model is distributed under the Apache 2.0 License.
- The uploader claims no ownership or rights over the model.
Update History
August 22, 2025
Add Why Use FP32 Text Encoder?
July 24, 2025
Re-upload of the GGUF model, reduction in model size, and correction of metadata.
July 6, 2025
Uploaded flan_t5_xxl_full_FP8 models.
April 20, 2025
Updated Stable Diffusion WebUI Forge FP32 launch argument.
April 15, 2025
Updated content to reflect ComfyUI updates.
March 20, 2025
Updated FLAN-T5-XXL model list and table.
- Downloads last month
- 958
3-bit
4-bit
5-bit
6-bit
8-bit
# !pip install llama-cpp-python from llama_cpp import Llama llm = Llama.from_pretrained( repo_id="easygoing0114/flan-t5-xxl-fused", filename="", )