Data-Juicer: A One-Stop Data Processing System for Large Language Models
Paper • 2309.02033 • Published • 4
Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
This is a reference LLM from Data-Juicer.
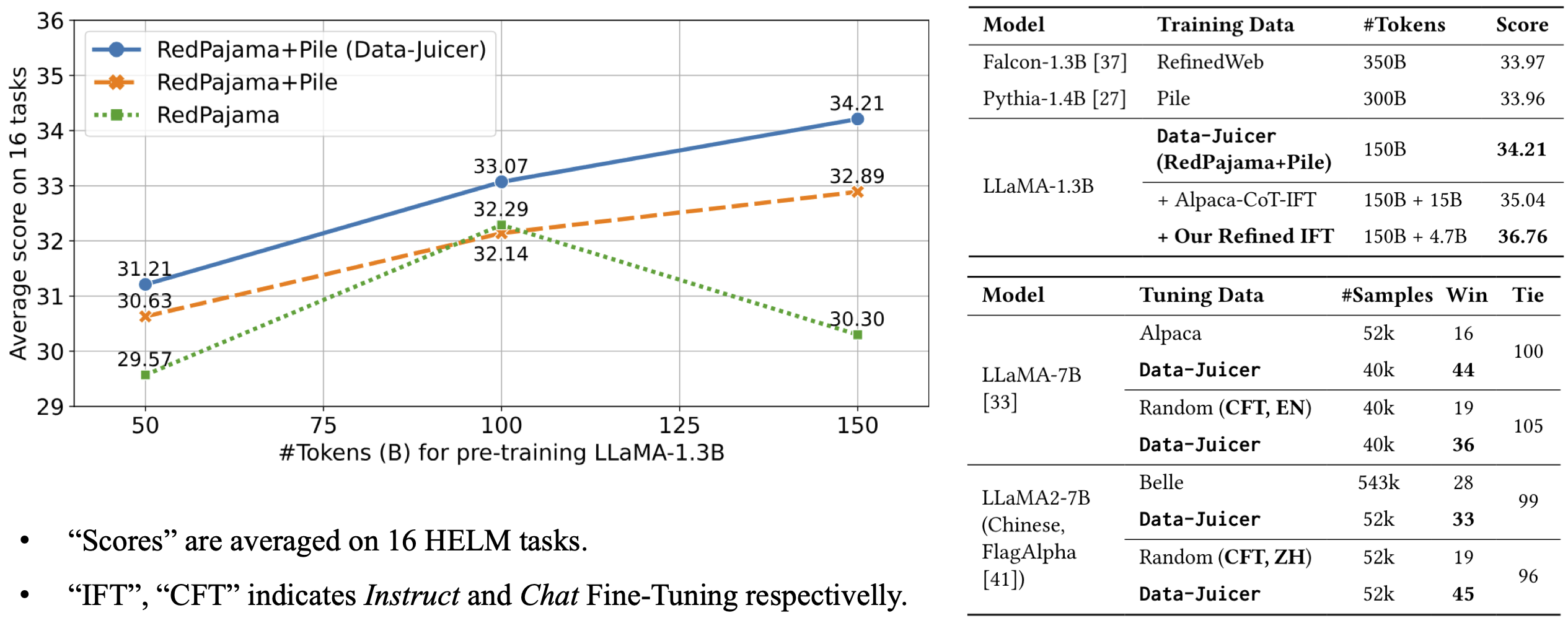
The model architecture is LLaMA-7B and we built it upon the pre-trained checkpoint. The model is fine-trained on 40k English chat samples of Data-Juicer's refined alpaca-CoT data. It beats LLaMA-7B fine-tuned on 52k Alpaca samples in GPT-4 evaluation.
For more details, please refer to our paper.