
[Trimming] Gemma 3
Collection
Collection of trimmed Google's Gemma3 decoder models. The models are sorted alphabetically. • 486 items • Updated
This model is a 58.67% smaller version of google/gemma-3-270m-it optimized for Icelandic language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
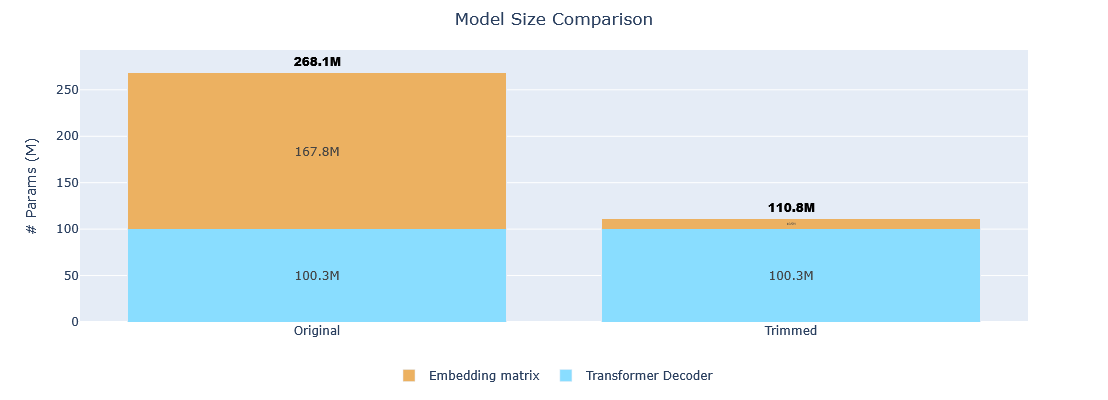
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 262,144 tokens | 16,384 tokens | 93.75% |
| Model size | 268,098,176 params | 110,811,776 params | 58.67% |
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "alphaedge-ai/gemma-3-270m-it-isl-16384"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Your prompt in Icelandic."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=256)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print(response)
@misc{gemmateam2025gemma3technicalreport,
title={Gemma 3 Technical Report},
author={Gemma Team},
year={2025},
eprint={2503.19786},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.19786},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
This model is derived from google/gemma-3-270m-it. Use of this model is governed by the Gemma Terms of Use. By using this model, you agree to the Gemma Terms of Use. This model is not affiliated with or endorsed by Google.