
[Trimming] Qwen3
Collection
Collection of trimmed Alibaba's Qwen3 decoder models. The models are sorted alphabetically. • 332 items • Updated
docker model run hf.co/alphaedge-ai/Qwen3-1.7B-tha-16384This model is a 27.33% smaller version of Qwen/Qwen3-1.7B optimized for Thai language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
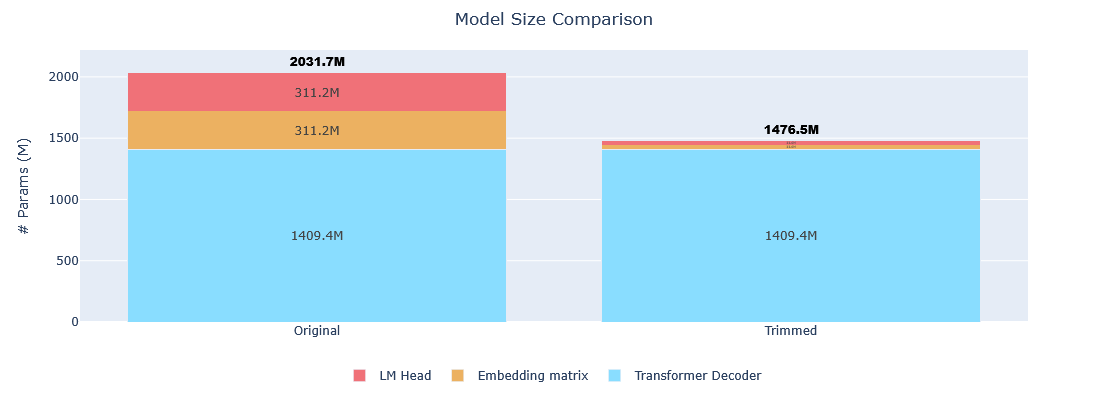
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 151,936 tokens | 16,384 tokens | 89.22% |
| Model size | 2,031,739,904 params | 1,476,518,912 params | 27.33% |
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "alphaedge-ai/Qwen3-1.7B-tha-16384"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Your prompt in Thai."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 32767 (</think>)
index = len(output_ids) - output_ids[::-1].index(32767)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("
")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("
")
print("thinking content:", thinking_content)
print("content:", content)
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Install from pip and serve model
# Install vLLM from pip: pip install vllm# Start the vLLM server: vllm serve "alphaedge-ai/Qwen3-1.7B-tha-16384"# Call the server using curl (OpenAI-compatible API): curl -X POST "http://localhost:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "alphaedge-ai/Qwen3-1.7B-tha-16384", "messages": [ { "role": "user", "content": "What is the capital of France?" } ] }'