

metadata
language:
- en
- de
- fr
- es
- it
- pt
license: apache-2.0
library_name: sauerkrautlm-colpali
tags:
- document-retrieval
- vision-language-model
- multi-vector
- colpali
- late-interaction
- visual-retrieval
- qwen3-vl
- mteb
- vidore
base_model: Qwen/Qwen3-VL-2B
pipeline_tag: image-text-to-text
datasets:
- vidore/colpali_train_set
- openbmb/VisRAG-Ret-Train-In-domain-data
- llamaindex/vdr-multilingual-train
metrics:
- ndcg_at_5
SauerkrautLM-ColQwen3-2b-v0.1

🥇 Best 128-dim Model in Medium (1-3B) Category | +1.01 over ColQwen2
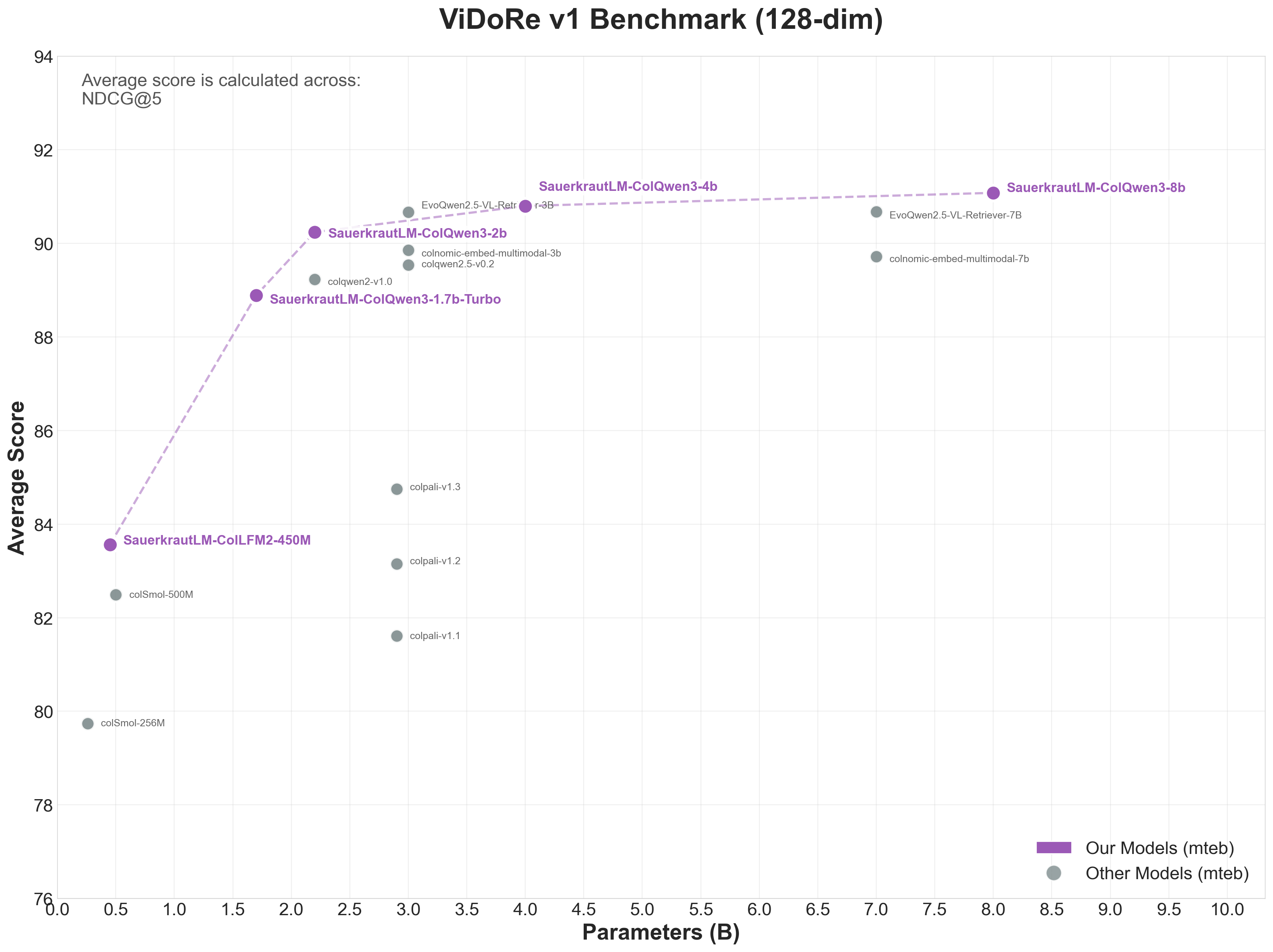
SauerkrautLM-ColQwen3-2b-v0.1 achieves 90.24 NDCG@5 on ViDoRe v1, making it the #1 in the Medium (1-3B) category among 128-dim models - a significant +1.01 improvement over the baseline ColQwen2-v1.0.
🎯 Why Visual Document Retrieval?
Traditional OCR-based retrieval loses layout, tables, and visual context. Our visual approach:
- ✅ No OCR errors - Direct visual understanding
- ✅ Layout-aware - Understands tables, forms, charts
- ✅ End-to-end - Single model, no pipeline complexity
🏆 Key Achievements
| Benchmark | Score | Rank (128-dim) |
|---|---|---|
| ViDoRe v1 | 90.24 | #5 |
| MTEB v1+v2 | 81.02 | #6 |
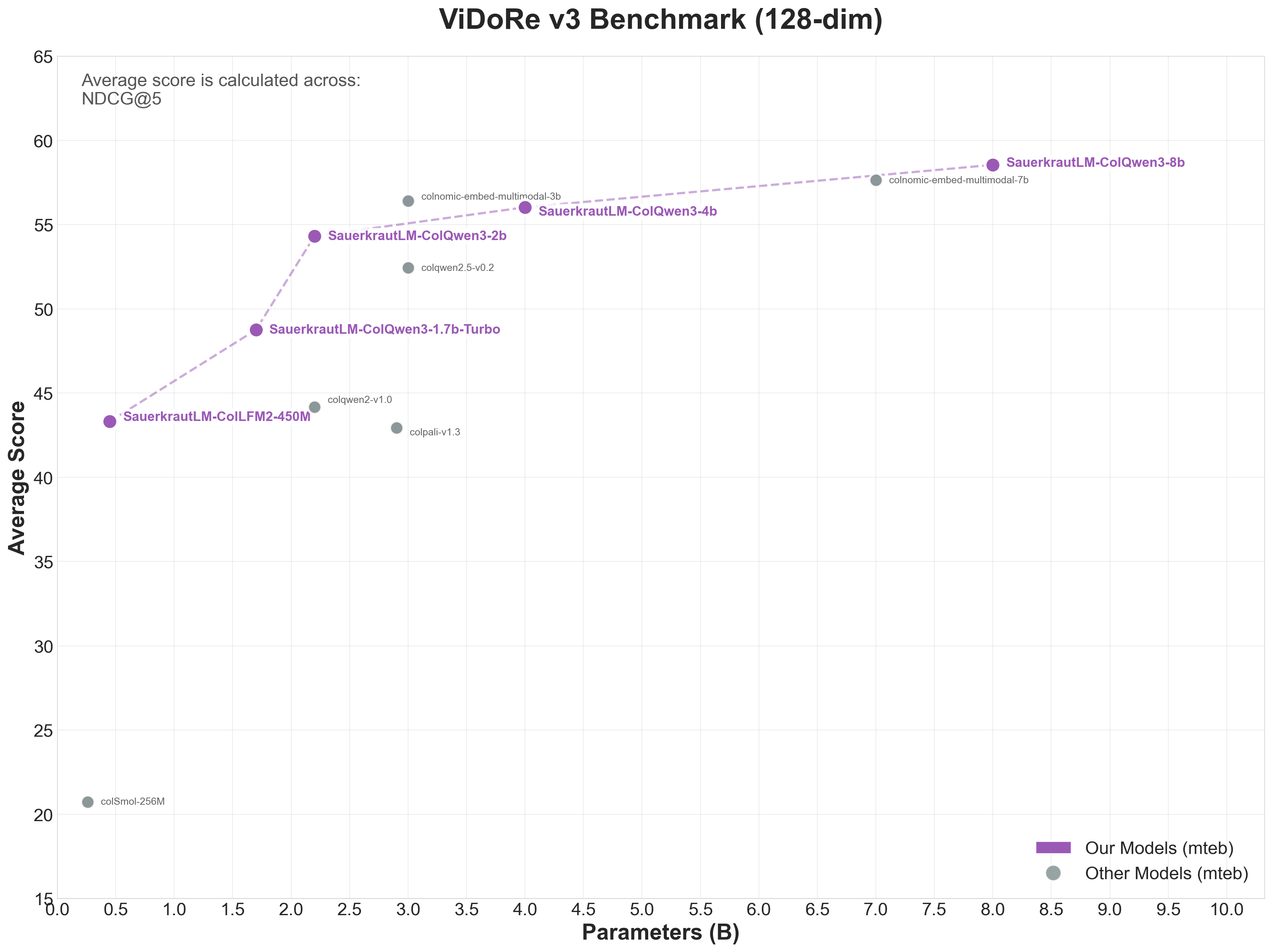
| ViDoRe v3 | 54.32 | #5 |
Medium Category Comparison (1-3B, 128-dim)
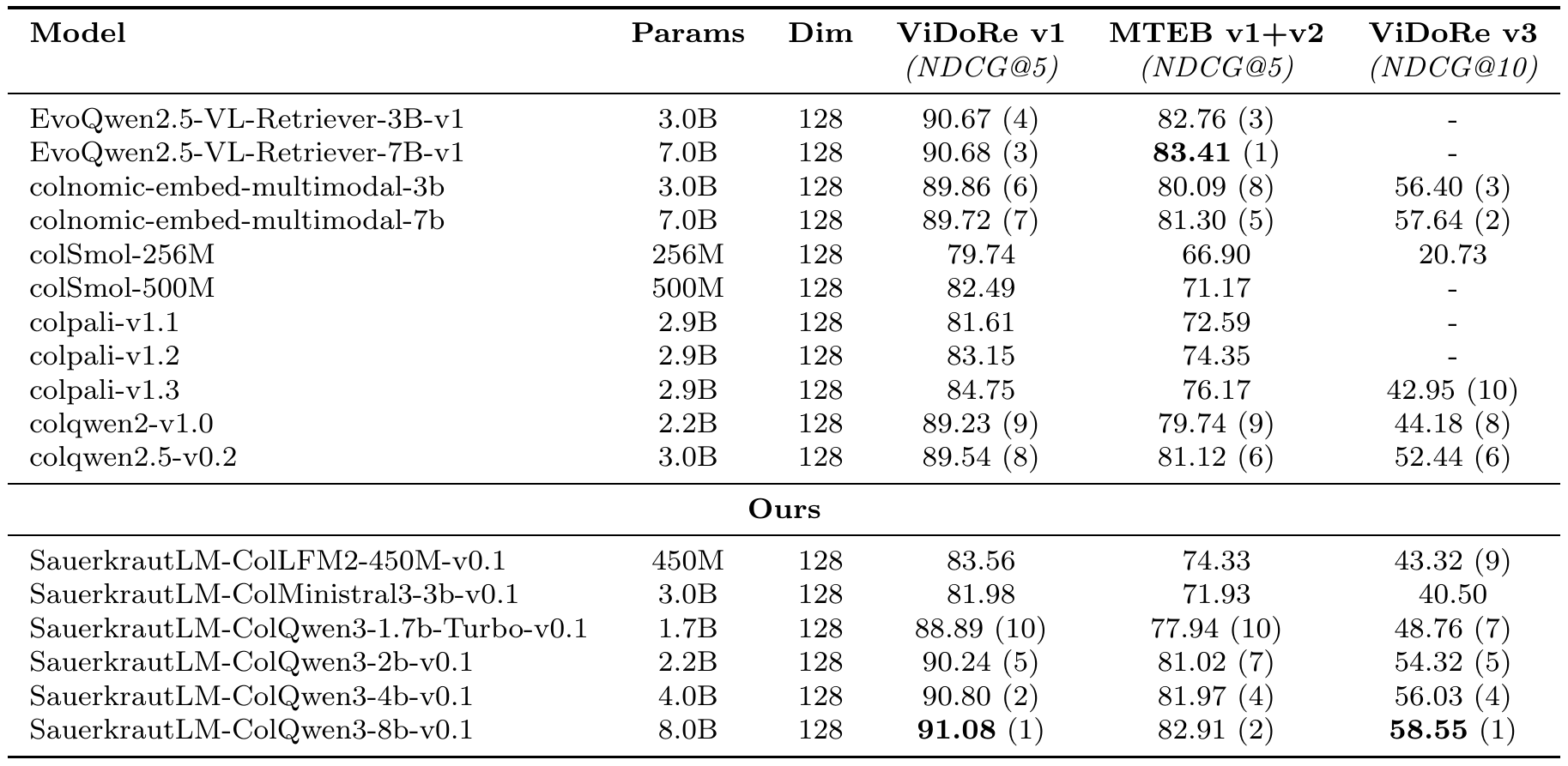
| Model | Params | Dim | ViDoRe v1 | MTEB v1+v2 | ViDoRe v3 |
|---|---|---|---|---|---|
| SauerkrautLM-ColQwen3-2b-v0.1 ⭐ | 2.2B | 128 | 90.24 | 81.02 | 54.32 |
| colqwen2-v1.0 | 2.2B | 128 | 89.23 | 79.74 | 44.18 |
| SauerkrautLM-ColQwen3-1.7b-Turbo-v0.1 | 1.7B | 128 | 88.89 | 77.94 | 48.76 |
#1 in Medium category on all three benchmarks!
Detailed Benchmark Results
📊 ViDoRe v1 (NDCG@5) - Click to expand
| Task | Score |
|---|---|
| ArxivQA | 91.24 |
| DocVQA | 65.06 |
| InfoVQA | 93.14 |
| ShiftProject | 88.74 |
| SyntheticDocQA-AI | 99.63 |
| SyntheticDocQA-Energy | 96.91 |
| SyntheticDocQA-Gov | 96.08 |
| SyntheticDocQA-Health | 99.26 |
| TabFQuAD | 90.32 |
| TATDQA | 82.06 |
| Average | 90.24 |
📊 MTEB v1+v2 (NDCG@5) - Click to expand
ViDoRe v1 Tasks:
| Task | Score |
|---|---|
| ArxivQA | 91.24 |
| DocVQA | 65.06 |
| InfoVQA | 93.14 |
| ShiftProject | 88.74 |
| SyntheticDocQA-AI | 99.63 |
| SyntheticDocQA-Energy | 96.91 |
| SyntheticDocQA-Gov | 96.08 |
| SyntheticDocQA-Health | 99.26 |
| TabFQuAD | 90.32 |
| TATDQA | 82.06 |
ViDoRe v2 Tasks (Multilingual):
| Task | Score |
|---|---|
| ViDoRe-v2-2BioMed | 58.62 |
| ViDoRe-v2-2Econ | 54.64 |
| ViDoRe-v2-2ESG-HL | 68.13 |
| ViDoRe-v2-2ESG | 50.40 |
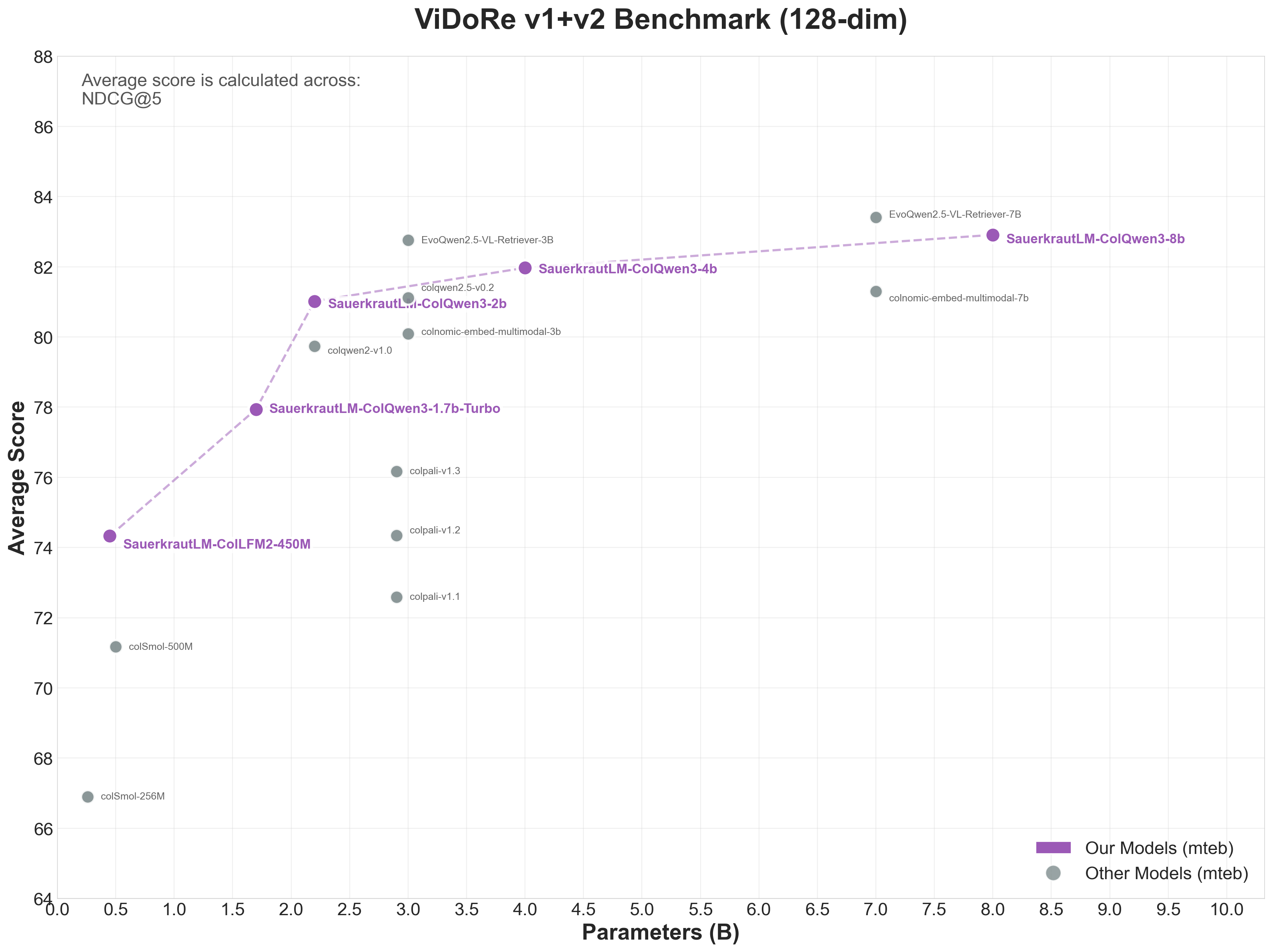
| Combined Average | 81.02 |
📊 ViDoRe v3 (NDCG@10) - Click to expand
| Task | Score |
|---|---|
| ViDoRe-v3-CS | 73.70 |
| ViDoRe-v3-Energy | 61.21 |
| ViDoRe-v3-FinanceEn | 54.30 |
| ViDoRe-v3-FinanceFr | 40.18 |
| ViDoRe-v3-HR | 52.97 |
| ViDoRe-v3-Industry | 44.01 |
| ViDoRe-v3-Pharma | 60.64 |
| ViDoRe-v3-Physics | 47.57 |
| Average | 54.32 |
Improvement over Baseline
| Metric | ColQwen3-2b | ColQwen2-v1.0 | Improvement |
|---|---|---|---|
| ViDoRe v1 | 90.24 | 89.23 | +1.01 |
| MTEB v1+v2 | 81.02 | 79.74 | +1.28 |
| ViDoRe v3 | 54.32 | 44.18 | +10.14 |
📋 Summary Tables
128-dim Models Comparison
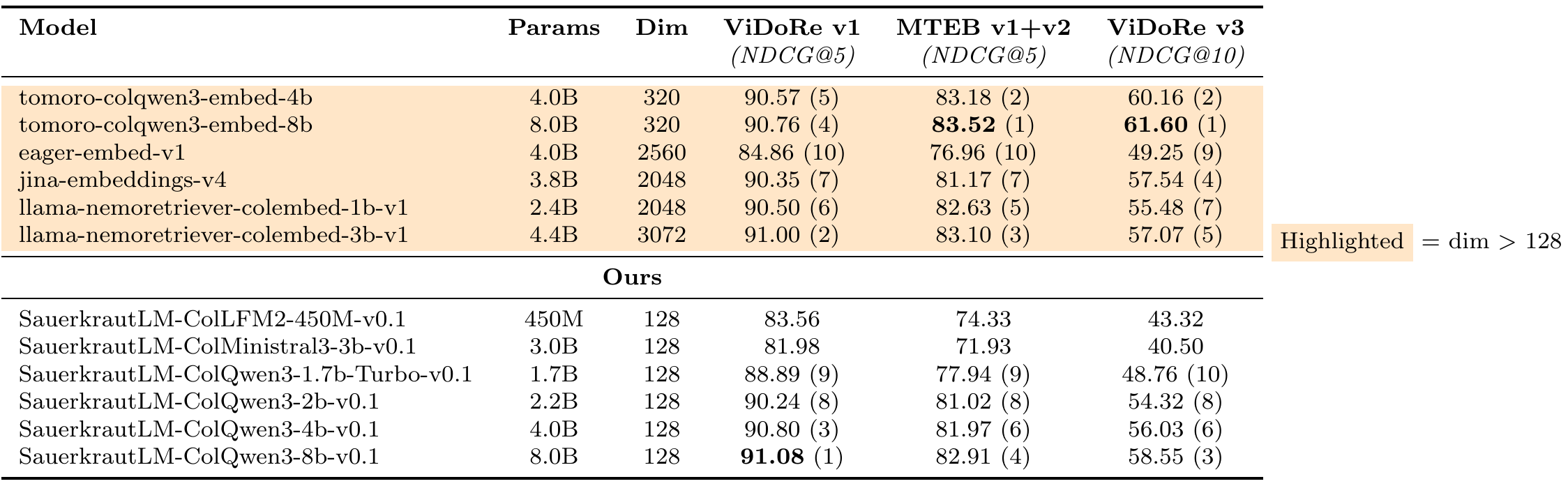
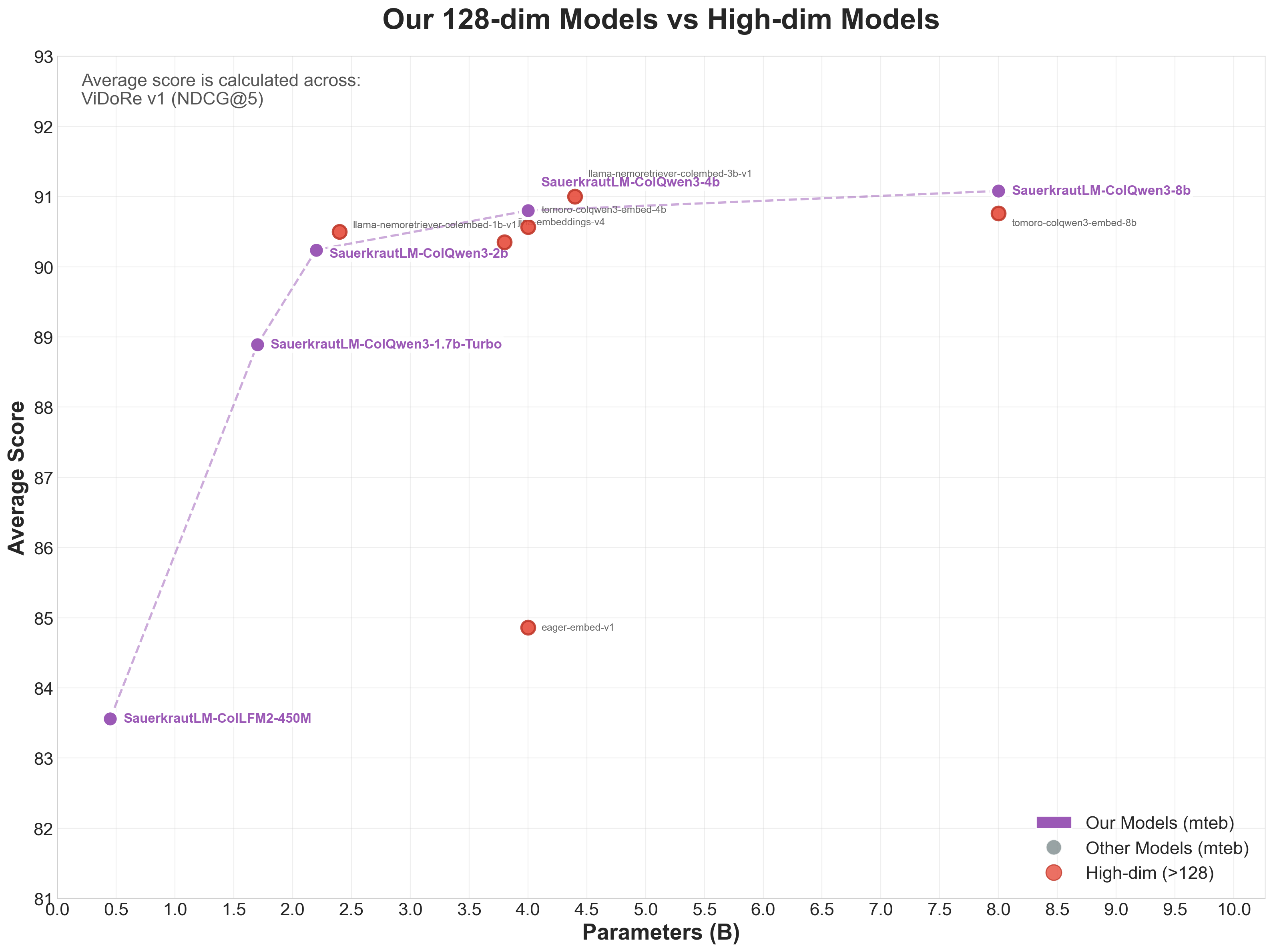
Comparison vs High-dim Models
✨ Key Features
- 🥇 #1 in Medium Category: Best 1-3B model among 128-dim models
- 📈 +1.01 over ColQwen2: Significant improvement over baseline
- 💾 Consumer GPU Ready: Only ~4.4GB VRAM
- ⚡ Compact Embeddings: 128-dimensional
- 🌍 Multilingual: 6 languages (EN, DE, FR, ES, IT, PT)
Model Details
| Property | Value |
|---|---|
| Base Model | Qwen/Qwen3-VL-2B |
| Parameters | 2.2B |
| Embedding Dimension | 128 |
| VRAM (bfloat16) | ~4.4 GB |
| Max Context Length | 262,144 tokens |
| License | Apache 2.0 |
Training
Hardware & Configuration
| Setting | Value |
|---|---|
| GPUs | 4x NVIDIA RTX 6000 Ada (48GB) |
| Effective Batch Size | 256 |
| Precision | bfloat16 |
Datasets
| Dataset | Type | Description |
|---|---|---|
| vidore/colpali_train_set | Public | ColPali training data |
| openbmb/VisRAG-Ret-Train-In-domain-data | Public | Visual RAG training data |
| llamaindex/vdr-multilingual-train | Public | Multilingual document retrieval |
| VAGO Multilingual Dataset 1 | In-house | Proprietary multilingual document-query pairs |
| VAGO Multilingual Dataset 2 | In-house | Proprietary multilingual document-query pairs |
Installation & Usage
⚠️ Important: Install our package first before loading the model:
pip install git+https://github.com/VAGOsolutions/sauerkrautlm-colpali
import torch
from PIL import Image
from sauerkrautlm_colpali.models import ColQwen3, ColQwen3Processor
model_name = "VAGOsolutions/SauerkrautLM-ColQwen3-2b-v0.1"
model = ColQwen3.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="cuda:0",
).eval()
processor = ColQwen3Processor.from_pretrained(model_name)
images = [Image.open("document.png")]
queries = ["What is the main topic?"]
batch_images = processor.process_images(images).to(model.device)
batch_queries = processor.process_queries(queries).to(model.device)
with torch.no_grad():
image_embeddings = model(**batch_images)
query_embeddings = model(**batch_queries)
scores = processor.score(query_embeddings, image_embeddings)
📊 Additional Benchmark Visualizations
MTEB v1+v2 Benchmark (128-dim Models)
ViDoRe v3 Benchmark (128-dim Models)
Our Models vs High-dim Models
Citation
@misc{sauerkrautlm-colpali-2025,
title={SauerkrautLM-ColPali: Multi-Vector Vision Retrieval Models},
author={David Golchinfar},
organization={VAGO Solutions},
year={2025},
url={https://github.com/VAGOsolutions/sauerkrautlm-colpali}
}
Contact
- VAGO Solutions: https://vago-solutions.ai
- GitHub: https://github.com/VAGOsolutions