
Speculator Models
Collection
19 items • Updated • 22
This is a speculator model designed for use with Qwen/Qwen3-32B, based on the EAGLE-3 speculative decoding algorithm.
It was trained using the speculators library on a combination of the Aeala/ShareGPT_Vicuna_unfiltered and the train_sft split of HuggingFaceH4/ultrachat_200k datasets.
This model should be used with the Qwen/Qwen3-32B chat template, specifically through the /chat/completions endpoint.
vllm serve Qwen/Qwen3-32B \
-tp 2 \
--speculative-config '{
"model": "RedHatAI/Qwen3-32B-speculator.eagle3",
"num_speculative_tokens": 3,
"method": "eagle3"
}'
| Use Case | Dataset | Number of Samples |
|---|---|---|
| Coding | HumanEval | 168 |
| Math Reasoning | gsm8k | 80 |
| Text Summarization | CNN/Daily Mail | 80 |
| Use Case | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 |
|---|---|---|---|---|---|---|---|
| Coding | 1.67 | 2.06 | 2.29 | 2.39 | 2.47 | 2.50 | 2.53 |
| Math Reasoning | 1.73 | 2.21 | 2.49 | 2.69 | 2.80 | 2.83 | 3.08 |
| Text Summarization | 1.62 | 1.95 | 2.15 | 2.23 | 2.27 | 2.32 | 2.33 |
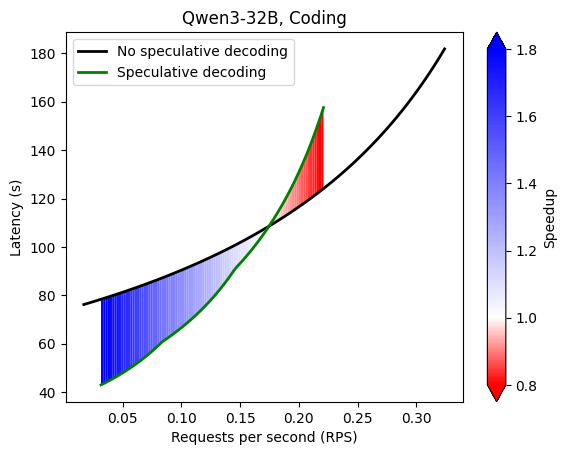
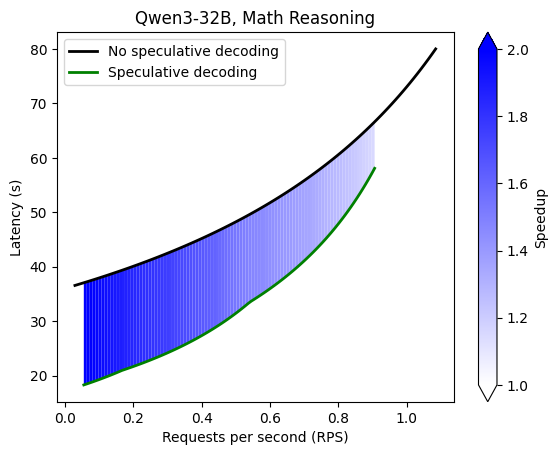
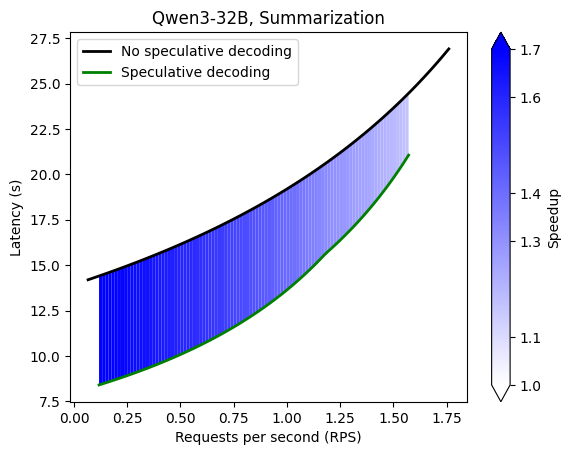
Command
GUIDELLM__PREFERRED_ROUTE="chat_completions" \
guidellm benchmark \
--target "http://localhost:8000/v1" \
--data "RedHatAI/speculator_benchmarks" \
--data-args '{"data_files": "HumanEval.jsonl"}' \
--rate-type sweep \
--max-seconds 600 \
--output-path "Qwen3-32B-HumanEval.json" \
--backend-args '{"extra_body": {"chat_completions": {"temperature":0.6, "top_p":0.95, "top_k":20}}}'
GuideLLM interface changed, so for compatibility with the latest version (v0.6.0), please use the following command:
GUIDELLM__PREFERRED_ROUTE="chat_completions" \
guidellm benchmark \
--target "http://localhost:8000/v1" \
--data "RedHatAI/speculator_benchmarks" \
--data-args '{"data_files": "HumanEval.jsonl"}' \
--profile sweep \
--max-seconds 1800 \
--output-path "my_output.json" \
--backend-args '{"extras": {"body": {"temperature":0.6, "top_p":0.95, "top_k":20}}}'