
MiniMax Sparse Attention
Paper • 2606.13392 • Published • 78
# Load model directly
from transformers import AutoProcessor, AutoModelForMultimodalLM
processor = AutoProcessor.from_pretrained("MiniMaxAI/MiniMax-M3", trust_remote_code=True)
model = AutoModelForMultimodalLM.from_pretrained("MiniMaxAI/MiniMax-M3", trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
},
]
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(processor.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
MiniMax-M3 is a native multimodal model with 1M context. It has ~428B parameters and ~23B activated parameters.
Highlights:

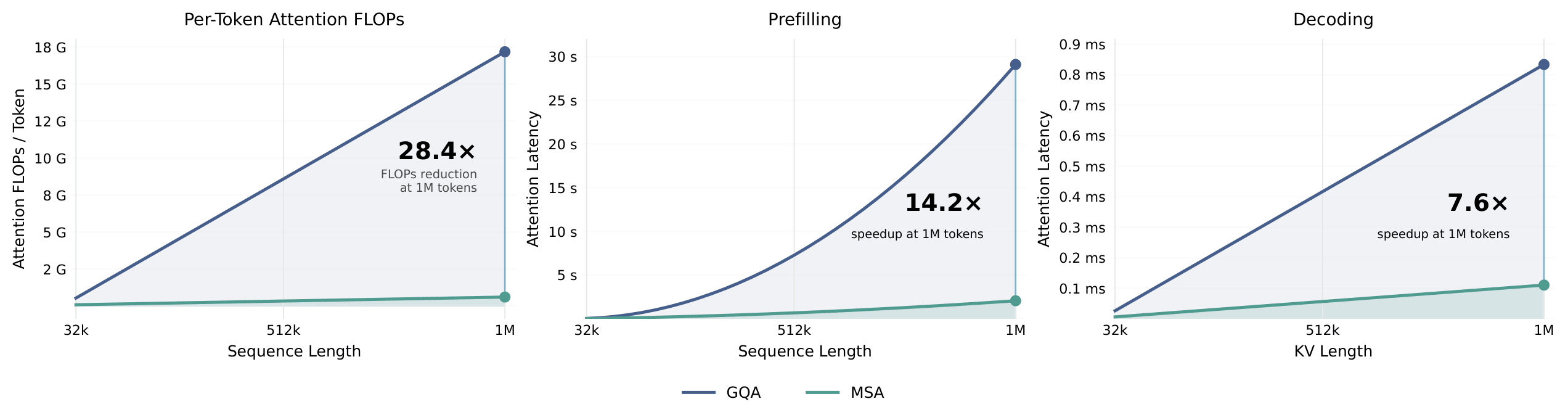
M3 is powered by MiniMax Sparse Attention (MSA), a high-performance sparse attention operator designed for million-token contexts. Compared with GQA, MSA dramatically reduces the attention compute and memory footprint while preserving model quality.
📄 Read the technical report: arXiv:2606.13392 · Hugging Face Papers
M3 supports two reasoning modes:
Download the model:
hf download MiniMaxAI/MiniMax-M3 --local-dir MiniMax-M3
We recommend the following inference frameworks (listed alphabetically) to serve the model:
SGLang - see SGLang cookbook.
vLLM - see vLLM recipes.
Transformers - see Transformers docs.
We recommend the following parameters for best performance: temperature=1.0, top_p=0.95, top_k=40.
Contact us at model@minimax.io.
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("image-text-to-text", model="MiniMaxAI/MiniMax-M3", trust_remote_code=True) messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"}, {"type": "text", "text": "What animal is on the candy?"} ] }, ] pipe(text=messages)