Libraries llama-cpp-python How to use Melvin56/Qwen3-4B-ik_GGUF with llama-cpp-python:
# !pip install llama-cpp-python
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="Melvin56/Qwen3-4B-ik_GGUF",
filename="qwen3-4b-0IQ4_K.gguf",
)
llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
) Notebooks Google Colab Kaggle Local Apps Settings llama.cpp How to use Melvin56/Qwen3-4B-ik_GGUF with llama.cpp:
Install (macOS, Linux) curl -LsSf https://llama.app/install.sh | sh
# Start a local OpenAI-compatible server with a web UI:
llama serve -hf Melvin56/Qwen3-4B-ik_GGUF:BF16
# Run inference directly in the terminal:
llama cli -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Install from WinGet (Windows) winget install llama.cpp
# Start a local OpenAI-compatible server with a web UI:
llama serve -hf Melvin56/Qwen3-4B-ik_GGUF:BF16
# Run inference directly in the terminal:
llama cli -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Use pre-built binary # Download pre-built binary from:
# https://github.com/ggerganov/llama.cpp/releases
# Start a local OpenAI-compatible server with a web UI:
./llama-server -hf Melvin56/Qwen3-4B-ik_GGUF:BF16
# Run inference directly in the terminal:
./llama-cli -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Build from source code git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build
cmake --build build -j --target llama-server llama-cli
# Start a local OpenAI-compatible server with a web UI:
./build/bin/llama-server -hf Melvin56/Qwen3-4B-ik_GGUF:BF16
# Run inference directly in the terminal:
./build/bin/llama-cli -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Use Docker docker model run hf.co/Melvin56/Qwen3-4B-ik_GGUF:BF16 LM Studio Jan vLLM How to use Melvin56/Qwen3-4B-ik_GGUF with vLLM:
Install from pip and serve model # Install vLLM from pip:
pip install vllm
# Start the vLLM server:
vllm serve "Melvin56/Qwen3-4B-ik_GGUF"
# Call the server using curl (OpenAI-compatible API):
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Melvin56/Qwen3-4B-ik_GGUF",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}' Use Docker docker model run hf.co/Melvin56/Qwen3-4B-ik_GGUF:BF16 Ollama How to use Melvin56/Qwen3-4B-ik_GGUF with Ollama:
ollama run hf.co/Melvin56/Qwen3-4B-ik_GGUF:BF16 Unsloth Studio How to use Melvin56/Qwen3-4B-ik_GGUF with Unsloth Studio:
Install Unsloth Studio (macOS, Linux, WSL) curl -fsSL https://unsloth.ai/install.sh | sh
# Run unsloth studio
unsloth studio -H 0.0.0.0 -p 8888
# Then open http://localhost:8888 in your browser
# Search for Melvin56/Qwen3-4B-ik_GGUF to start chatting Install Unsloth Studio (Windows) irm https://unsloth.ai/install.ps1 | iex
# Run unsloth studio
unsloth studio -H 0.0.0.0 -p 8888
# Then open http://localhost:8888 in your browser
# Search for Melvin56/Qwen3-4B-ik_GGUF to start chatting Using HuggingFace Spaces for Unsloth # No setup required
# Open https://huggingface.co/spaces/unsloth/studio in your browser
# Search for Melvin56/Qwen3-4B-ik_GGUF to start chatting Pi How to use Melvin56/Qwen3-4B-ik_GGUF with Pi:
Start the llama.cpp server # Install llama.cpp:
brew install llama.cpp
# Start a local OpenAI-compatible server:
llama serve -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Configure the model in Pi # Install Pi:
npm install -g @mariozechner/pi-coding-agent
# Add to ~/.pi/agent/models.json:
{
"providers": {
"llama-cpp": {
"baseUrl": "http://localhost:8080/v1",
"api": "openai-completions",
"apiKey": "none",
"models": [
{
"id": "Melvin56/Qwen3-4B-ik_GGUF:BF16"
}
]
}
}
} Run Pi # Start Pi in your project directory:
pi Hermes Agent new How to use Melvin56/Qwen3-4B-ik_GGUF with Hermes Agent:
Start the llama.cpp server # Install llama.cpp:
brew install llama.cpp
# Start a local OpenAI-compatible server:
llama serve -hf Melvin56/Qwen3-4B-ik_GGUF:BF16 Configure Hermes # Install Hermes:
curl -fsSL https://hermes-agent.nousresearch.com/install.sh | bash
hermes setup
# Point Hermes at the local server:
hermes config set model.provider custom
hermes config set model.base_url http://127.0.0.1:8080/v1
hermes config set model.default Melvin56/Qwen3-4B-ik_GGUF:BF16 Run Hermes hermes Atomic Chat new Docker Model Runner How to use Melvin56/Qwen3-4B-ik_GGUF with Docker Model Runner:
docker model run hf.co/Melvin56/Qwen3-4B-ik_GGUF:BF16 Lemonade How to use Melvin56/Qwen3-4B-ik_GGUF with Lemonade:
Pull the model # Download Lemonade from https://lemonade-server.ai/
lemonade pull Melvin56/Qwen3-4B-ik_GGUF:BF16 Run and chat with the model lemonade run user.Qwen3-4B-ik_GGUF-BF16 List all available models lemonade list 
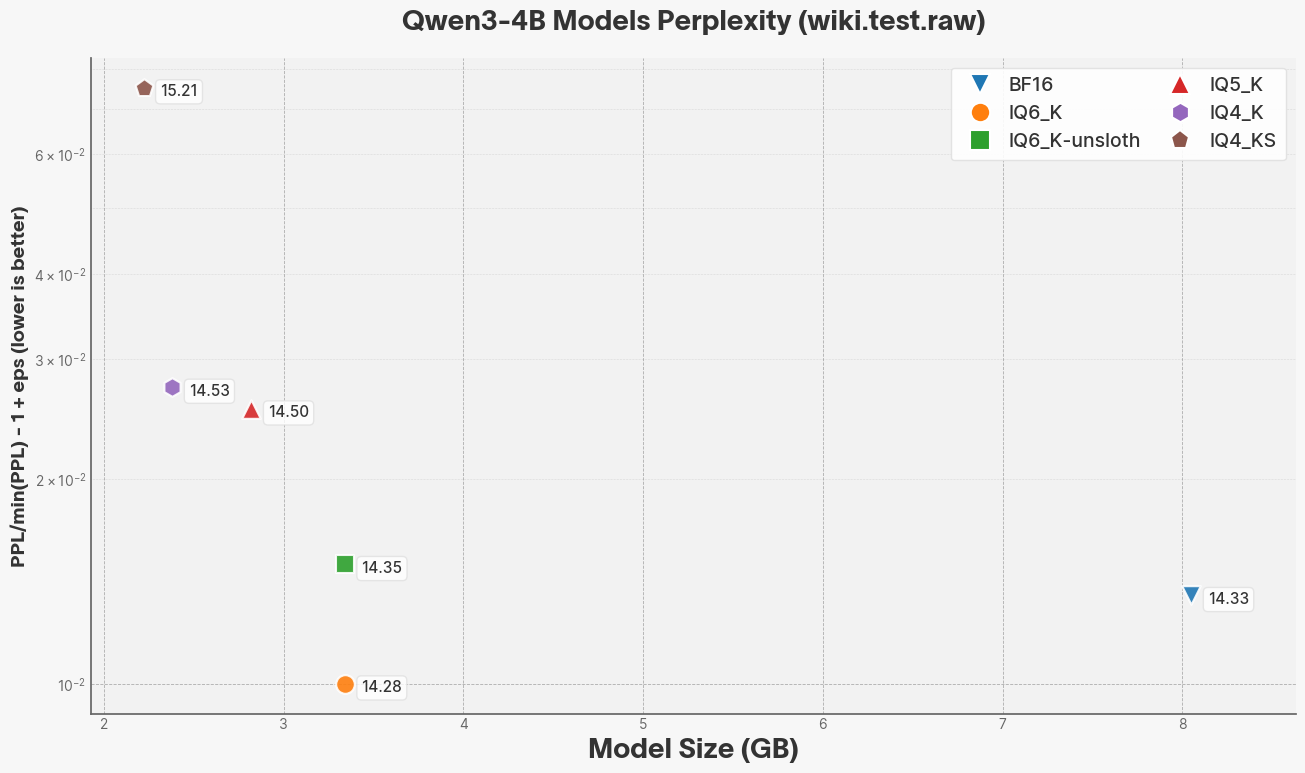
Install Unsloth Studio (macOS, Linux, WSL)
# Run unsloth studio unsloth studio -H 0.0.0.0 -p 8888 # Then open http://localhost:8888 in your browser # Search for Melvin56/Qwen3-4B-ik_GGUF to start chatting