---
license: mit
library_name: transformers
pipeline_tag: text-generation
tags:
- dflash
- speculative-decoding
- diffusion
- efficiency
- flash-decoding
- qwen
- diffusion-language-model
---
# Qwen3-4B-DFlash-b16
[**Paper**](https://arxiv.org/abs/2602.06036) | [**GitHub**](https://github.com/z-lab/dflash) | [**Blog**](https://z-lab.ai/projects/dflash/)
**DFlash** is a novel speculative decoding method that utilizes a lightweight **block diffusion** model for drafting. It enables efficient, high-quality parallel drafting that pushes the limits of inference speed.
This model is the **drafter** component. It must be used in conjunction with the target model `Qwen/Qwen3-4B`.
## 🚀 Quick Start
### SGLang
#### Installation
```bash
uv pip install "git+https://github.com/sgl-project/sglang.git@refs/pull/20547/head#subdirectory=python"
```
#### Launch Server
```bash
# Optional: enable schedule overlapping (experimental, may not be stable)
# export SGLANG_ENABLE_SPEC_V2=1
# export SGLANG_ENABLE_DFLASH_SPEC_V2=1
# export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3-4B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3-4B-DFlash-b16 \
--tp-size 1 \
--dtype bfloat16 \
--attention-backend fa3 \
--mem-fraction-static 0.75 \
--trust-remote-code
```
#### Usage
```python
from openai import OpenAI
client = OpenAI(base_url="http://localhost:30000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Qwen/Qwen3-4B",
messages=[{"role": "user", "content": "Write a quicksort in Python."}],
max_tokens=2048,
temperature=0.0,
extra_body={
"chat_template_kwargs": {"enable_thinking": False},
},
)
print(response.choices[0].message.content)
```
### vLLM
#### Installation
```bash
uv pip install vllm
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
```
#### Launch Server
```bash
vllm serve Qwen/Qwen3-4B \
--speculative-config '{"method": "dflash", "model": "z-lab/Qwen3-4B-DFlash-b16", "num_speculative_tokens": 15}' \
--attention-backend flash_attn \
--max-num-batched-tokens 32768
```
#### Usage
```python
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="Qwen/Qwen3-4B",
messages=[{"role": "user", "content": "Write a quicksort in Python."}],
max_tokens=2048,
temperature=0.0,
chat_template_kwargs: {"enable_thinking": False},
)
print(response.choices[0].message.content)
```
### Transformers
This model requires `trust_remote_code=True` to load the custom architecture for block diffusion generation.
#### Installation
Ensure you have `transformers` and `torch` installed. Our evaluation is conducted with torch==2.9.0 and transformers=4.57.3.
```bash
pip install transformers==4.57.3 torch==2.9.1 accelerate
```
#### Inference
The following example demonstrates how to load the DFlash drafter and the Qwen3-8B target model to perform speculative decoding.
```python
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
# 1. Load the DFlash Draft Model
# Note: trust_remote_code=True is required for DFlash. We recommend run on one GPU currently.
model = AutoModel.from_pretrained(
"z-lab/Qwen3-4B-DFlash-b16",
trust_remote_code=True,
dtype="auto",
device_map="cuda:0"
).eval()
# 2. Load the Target Model
target = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-4B",
dtype="auto",
device_map="cuda:0"
).eval()
# 3. Load Tokenizer and Prepare Input
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-4B")
prompt = "How many positive whole-number divisors does 196 have?"
messages = [
{"role": "user", "content": prompt}
]
# Note: this draft model is used for thinking mode disabled
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. Run Speculative Decoding
# The 'spec_generate' function is a custom method provided by the DFlash model
generate_ids = model.spec_generate(
input_ids=model_inputs["input_ids"],
max_new_tokens=2048,
temperature=0.0,
target=target,
stop_token_ids=[tokenizer.eos_token_id]
)
print(tokenizer.decode(generate_ids[0], skip_special_tokens=True))
```
## Evaluation
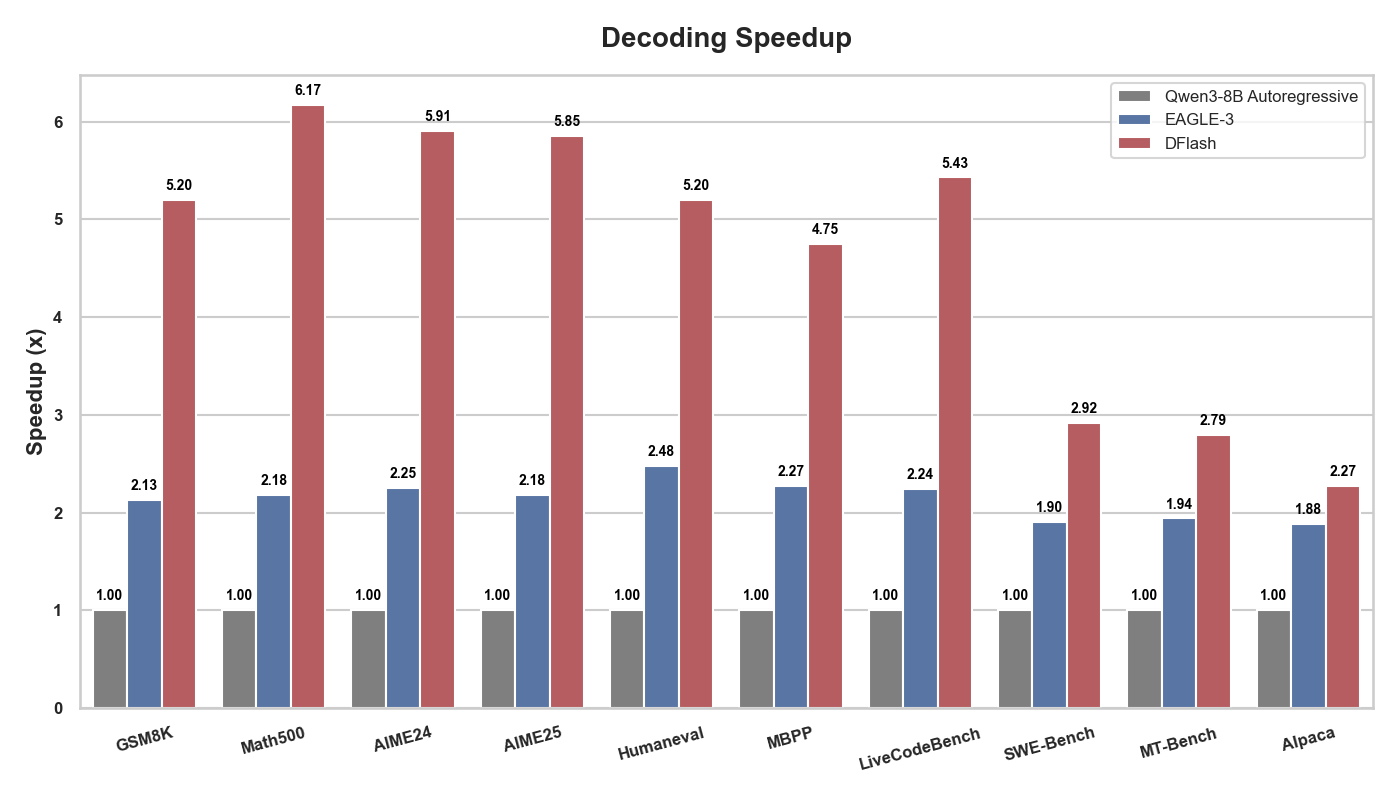
DFlash achieves up to **6.17x** lossless acceleration for **Qwen3-8B**, making it nearly **2.5x** faster than the state-of-the-art speculative decoding method EAGLE-3. Check out our [GitHub repository](https://github.com/z-lab/dflash) to see how to reproduce the results.
## **Citation**
If you find DFlash useful for your research or applications, please cite our project.
```bibtex
@misc{chen2026dflash,
title = {DFlash: Block Diffusion for Flash Speculative Decoding},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
year = {2026},
eprint = {2602.06036},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2602.06036}
}
```