
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +28 -0
- .gitignore +5 -0
- Dockerfile +33 -0
- LICENSE +21 -0
- README.md +375 -0
- data/cached_fineweb100B.py +16 -0
- data/cached_fineweb10B.py +16 -0
- data/cached_finewebedu10B.py +16 -0
- data/fineweb.py +126 -0
- data/requirements.txt +2 -0
- img/algo_optimizer.png +3 -0
- img/dofa.jpg +0 -0
- img/fig_optimizer.png +3 -0
- img/fig_tuned_nanogpt.png +3 -0
- img/nanogpt_speedrun51.png +3 -0
- img/nanogpt_speedrun52.png +0 -0
- img/nanogpt_speedrun53.png +3 -0
- img/nanogpt_speedrun54.png +0 -0
- records/track_1_short/2024-06-06_AdamW/README.md +8 -0
- records/track_1_short/2024-06-06_AdamW/f66d43d7-e449-4029-8adf-e8537bab49ea.log +0 -0
- records/track_1_short/2024-10-09_SOAP/5bdc3988-496c-4232-b4ef-53764cb81c92.txt +0 -0
- records/track_1_short/2024-10-09_SOAP/README.md +9 -0
- records/track_1_short/2024-10-09_SOAP/train_gpt2.py +857 -0
- records/track_1_short/2024-10-10_Muon/eb5659d0-fb6a-49e5-a311-f1f89412f726.txt +0 -0
- records/track_1_short/2024-10-10_Muon/train_gpt2.py +524 -0
- records/track_1_short/2024-10-13_llmc/README.md +11 -0
- records/track_1_short/2024-10-13_llmc/main.log +0 -0
- records/track_1_short/2024-10-14_ModernArch/dabaaddd-237c-4ec9-939d-6608a9ed5e27.txt +0 -0
- records/track_1_short/2024-10-14_ModernArch/train_gpt2.py +516 -0
- records/track_1_short/2024-10-17_DistributedMuon/22d24867-eb5a-4fcc-ae2c-263d0277dfd1.txt +0 -0
- records/track_1_short/2024-10-18_PyTorch25/d4bfb25f-688d-4da5-8743-33926fad4842.txt +0 -0
- records/track_1_short/2024-10-20_ScaleUp1B/87bd51fd-6203-4c88-b3aa-8a849a6a83ca.txt +0 -0
- records/track_1_short/2024-10-20_ScaleUp1B/ad8d7ae5-7b2d-4ee9-bc52-f912e9174d7a.txt +0 -0
- records/track_1_short/2024-10-20_ScaleUp1B/c0078066-c8c9-49c8-868a-ff4d4f32e615.txt +0 -0
- records/track_1_short/2024-10-29_Optimizers/8bfe4e35-c3fc-4b70-a984-3be937b71ff3.txt +0 -0
- records/track_1_short/2024-10-29_Optimizers/8d6193f4-27fc-4e68-899f-af70019a4d54.txt +0 -0
- records/track_1_short/2024-10-29_Optimizers/95a9fd44-7c13-49c7-b324-3e7d9e23a499.txt +0 -0
- records/track_1_short/2024-10-29_Optimizers/README.md +103 -0
- records/track_1_short/2024-10-29_Optimizers/e21a2838-a0f2-46f2-a247-db0021165682.txt +0 -0
- records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun81w.png +3 -0
- records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun82w.png +3 -0
- records/track_1_short/2024-11-03_UntieEmbed/README.md +27 -0
- records/track_1_short/2024-11-03_UntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.txt +0 -0
- records/track_1_short/2024-11-04_50Bruns/3d715d41-453a-40d6-9506-421ba69766b2.txt +0 -0
- records/track_1_short/2024-11-04_50Bruns/4fbe61ec-f79a-4c19-836d-46d599deecce.txt +0 -0
- records/track_1_short/2024-11-04_50Bruns/530f3ee1-8862-4d21-be2b-da10eb05e6a9.txt +0 -0
- records/track_1_short/2024-11-04_50Bruns/69c33fc9-eabb-4a38-aa08-6922914eb405.txt +0 -0
- records/track_1_short/2024-11-04_50Bruns/README.md +26 -0
- records/track_1_short/2024-11-06_ShortcutsTweaks/042f9e87-07e6-4504-bb04-4ec59a380211.txt +0 -0
- records/track_1_short/2024-11-06_ShortcutsTweaks/05b29e54-0be0-4a0f-a1e2-7d5317daedd3.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,31 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
img/algo_optimizer.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
img/fig_optimizer.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
img/fig_tuned_nanogpt.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
img/nanogpt_speedrun51.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
img/nanogpt_speedrun53.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun81w.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun82w.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
records/track_1_short/2024-11-06_ShortcutsTweaks/nanogpt_speedrun111.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
records/track_1_short/2025-01-04_SoftCap/curves_010425.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
records/track_1_short/2025-01-16_Sub3Min/long-short-swa.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
records/track_1_short/2025-01-26_BatchSize/ablations.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
records/track_1_short/2025-09-03_FA3/media/attn_speed_vs_batch_s1024_ws384.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-current-comm-overlap.png filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-current-first-rs.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-current-overview.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-hook-comm-overlap.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-hook-first-rs.png filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
records/track_1_short/2025-10-31_AdamSyncGradientHook/profiler-trace-hook-overview.png filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
records/track_1_short/2025-11-10_CautiousWD/assets/cwd_condition_numbers.jpg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
records/track_1_short/2025-11-29_BatchSizeSchedule/val_loss_five_step.png filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
records/track_1_short/2025-12-19_RetieLMHead/lm_head_weights.png filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
records/track_1_short/2025-12-21_SmoothedScalars/resid_lambdas_plots.png filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
records/track_1_short/2025-12-21_SmoothedScalars/smear_gate_plots.png filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
records/track_1_short/2025-12-21_SmoothedScalars/smear_lambda_plot.png filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
records/track_1_short/2025-12-21_SmoothedScalars/x0_lambdas_plots.png filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
records/track_1_short/2025-12-31_GatesToCompiledAdam/adam_kernel_fusion.png filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
records/track_1_short/2025-12-31_GatesToCompiledAdam/impact_to_opt_window.png filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
records/track_1_short/2025-12-31_GatesToCompiledAdam/smoothing_plots.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
fineweb10B/
|
| 2 |
+
pylog124M/
|
| 3 |
+
__pycache__/
|
| 4 |
+
logs/
|
| 5 |
+
.DS_Store
|
Dockerfile
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.6.2-cudnn-devel-ubuntu24.04
|
| 2 |
+
|
| 3 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 4 |
+
ENV PYTHON_VERSION=3.12.7
|
| 5 |
+
ENV PATH=/usr/local/bin:$PATH
|
| 6 |
+
|
| 7 |
+
RUN apt update && apt install -y --no-install-recommends build-essential libssl-dev zlib1g-dev \
|
| 8 |
+
libbz2-dev libreadline-dev libsqlite3-dev curl git libncursesw5-dev xz-utils tk-dev libxml2-dev \
|
| 9 |
+
libxmlsec1-dev libffi-dev liblzma-dev \
|
| 10 |
+
&& apt clean && rm -rf /var/lib/apt/lists/*
|
| 11 |
+
|
| 12 |
+
RUN curl -O https://www.python.org/ftp/python/${PYTHON_VERSION}/Python-${PYTHON_VERSION}.tgz && \
|
| 13 |
+
tar -xzf Python-${PYTHON_VERSION}.tgz && \
|
| 14 |
+
cd Python-${PYTHON_VERSION} && \
|
| 15 |
+
./configure --enable-optimizations && \
|
| 16 |
+
make -j$(nproc) && \
|
| 17 |
+
make altinstall && \
|
| 18 |
+
cd .. && \
|
| 19 |
+
rm -rf Python-${PYTHON_VERSION} Python-${PYTHON_VERSION}.tgz
|
| 20 |
+
|
| 21 |
+
RUN ln -s /usr/local/bin/python3.12 /usr/local/bin/python && \
|
| 22 |
+
ln -s /usr/local/bin/pip3.12 /usr/local/bin/pip
|
| 23 |
+
|
| 24 |
+
COPY requirements.txt /modded-nanogpt/requirements.txt
|
| 25 |
+
WORKDIR /modded-nanogpt
|
| 26 |
+
|
| 27 |
+
RUN python -m pip install --upgrade pip && \
|
| 28 |
+
pip install -r requirements.txt
|
| 29 |
+
|
| 30 |
+
RUN pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126 --upgrade
|
| 31 |
+
|
| 32 |
+
CMD ["bash"]
|
| 33 |
+
ENTRYPOINT []
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Keller Jordan
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,375 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modded-NanoGPT
|
| 2 |
+
|
| 3 |
+
This repository hosts the *NanoGPT speedrun*, in which we (collaboratively|competitively) search for the fastest algorithm to use 8 NVIDIA H100 GPUs to train a language model that attains 3.28 cross-entropy loss on the [FineWeb](https://huggingface.co/datasets/HuggingFaceFW/fineweb) validation set.
|
| 4 |
+
|
| 5 |
+
The target (3.28 validation loss on FineWeb) follows Andrej Karpathy's [GPT-2 replication in llm.c, which attains that loss after running for 45 minutes](https://github.com/karpathy/llm.c/discussions/481#:~:text=By%20the%20end%20of%20the%20optimization%20we%27ll%20get%20to%20about%203.29).
|
| 6 |
+
The speedrun code also descends from llm.c's [PyTorch trainer](https://github.com/karpathy/llm.c/blob/master/train_gpt2.py), which itself descends from NanoGPT, hence the name of the repo.
|
| 7 |
+
Thanks to the efforts of many contributors, this repo now contains a training algorithm which attains the target performance in:
|
| 8 |
+
* 2 minutes on 8xH100 (the llm.c GPT-2 replication needed 45)
|
| 9 |
+
* under 500M tokens (the llm.c GPT-2 replication needed 10B)
|
| 10 |
+
|
| 11 |
+
This improvement in training speed has been brought about by the following techniques:
|
| 12 |
+
* Modernized architecture: Rotary embeddings, QK-Norm, and ReLU²
|
| 13 |
+
* The Muon optimizer [[writeup](https://kellerjordan.github.io/posts/muon/)] [[repo](https://github.com/KellerJordan/Muon)]
|
| 14 |
+
* Use FP8 matmul for head, and asymmetric rescale and softcap logits
|
| 15 |
+
* Initialization of projections to zero (muP-like)
|
| 16 |
+
* Skip connections from embedding to every block as well as from block 3 to 6
|
| 17 |
+
* Extra embeddings which are mixed into the values in attention layers (inspired by Zhou et al. 2024)
|
| 18 |
+
* Flash Attention 3 with long-short sliding window attention pattern (inspired by Gemma 2) and window size warmup with YaRN
|
| 19 |
+
* Align training batch starts with EoS and set a max document length
|
| 20 |
+
* Accumulate gradients for 2 steps for embedding and lm_head before updating parameters
|
| 21 |
+
* Enable model to back out contributions from first 2/3 layers before prediction
|
| 22 |
+
* Polar Express implementation in Muon
|
| 23 |
+
* Smear module to enable 1 token look back
|
| 24 |
+
* Sparse attention gate
|
| 25 |
+
* NorMuon
|
| 26 |
+
* Cautious Weight Decay w/ schedule tied to LR
|
| 27 |
+
* Exponential decay of residual stream
|
| 28 |
+
* Batch size schedule
|
| 29 |
+
* Partial Key Offset
|
| 30 |
+
* Multi token prediction
|
| 31 |
+
* Untie embed and lm_head at 2/3 of training
|
| 32 |
+
* Additional gating on value embeddings and skip connection
|
| 33 |
+
* Paired head attention
|
| 34 |
+
|
| 35 |
+
As well as many systems optimizations.
|
| 36 |
+
|
| 37 |
+
Contributors list (growing with each new record): [@bozavlado](https://x.com/bozavlado); [@brendanh0gan](https://x.com/brendanh0gan);
|
| 38 |
+
[@fernbear.bsky.social](https://bsky.app/profile/fernbear.bsky.social); [@Grad62304977](https://x.com/Grad62304977);
|
| 39 |
+
[@jxbz](https://x.com/jxbz); [@kellerjordan0](https://x.com/kellerjordan0);
|
| 40 |
+
[@KoszarskyB](https://x.com/KoszarskyB); [@leloykun](https://x.com/@leloykun);
|
| 41 |
+
[@YouJiacheng](https://x.com/YouJiacheng); [@jadenj3o](https://x.com/jadenj3o);
|
| 42 |
+
[@KonstantinWilleke](https://github.com/KonstantinWilleke), [@alexrgilbert](https://github.com/alexrgilbert), [@adricarda](https://github.com/adricarda),
|
| 43 |
+
[@tuttyfrutyee](https://github.com/tuttyfrutyee), [@vdlad](https://github.com/vdlad);
|
| 44 |
+
[@ryanyang0](https://x.com/ryanyang0), [@vagrawal](https://github.com/vagrawal), [@classiclarryd](https://x.com/classiclarryd),
|
| 45 |
+
[@byronxu99](https://github.com/byronxu99), [@varunneal](https://x.com/varunneal), [@EmelyanenkoK](https://github.com/EmelyanenkoK),
|
| 46 |
+
[@bernard24](https://github.com/bernard24)/https://www.hiverge.ai/, [@Gusarich](https://x.com/Gusarich), [@li_zichong](https://x.com/li_zichong),
|
| 47 |
+
[@akash5474](https://github.com/akash5474), [@snimu](https://x.com/omouamoua), [@roeeshenberg](https://x.com/roeeshenberg),
|
| 48 |
+
[@ChrisJMcCormick](https://x.com/ChrisJMcCormick), [@dominikkallusky](https://github.com/dominikkallusky), [@acutkosky](https://github.com/acutkosky),
|
| 49 |
+
[@manikbhandari](https://github.com/manikbhandari), [@andrewbriand](https://github.com/andrewbriand), [@jrauvola](https://github.com/jrauvola)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
---
|
| 53 |
+
|
| 54 |
+
## Running the current record
|
| 55 |
+
|
| 56 |
+
To run the current record, run the following commands.
|
| 57 |
+
```bash
|
| 58 |
+
git clone https://github.com/KellerJordan/modded-nanogpt.git && cd modded-nanogpt
|
| 59 |
+
pip install -r requirements.txt
|
| 60 |
+
pip install torch==2.10.0.dev20251210+cu126 --index-url https://download.pytorch.org/whl/nightly/cu126
|
| 61 |
+
# downloads only the first 900M training tokens to save time
|
| 62 |
+
python data/cached_fineweb10B.py 9
|
| 63 |
+
./run.sh
|
| 64 |
+
```
|
| 65 |
+
Add torchrun to path if ./run.sh gives error `torchrun: command not found`.
|
| 66 |
+
|
| 67 |
+
**Note: torch.compile will add around 7 minutes of latency the first time you run the code.**
|
| 68 |
+
|
| 69 |
+
Official records are timed on 8 NVIDIA H100 GPUs from https://app.primeintellect.ai/. PrimeIntellect has generously sponsored recent validation runs.
|
| 70 |
+
|
| 71 |
+
## Alternative: Running with Docker (recommended for precise timing)
|
| 72 |
+
|
| 73 |
+
For cases where CUDA or NCCL versions aren't compatible with your current system setup, Docker can be a helpful alternative.
|
| 74 |
+
This approach standardizes versions for CUDA, NCCL, CUDNN, and Python, reducing dependency issues and simplifying setup.
|
| 75 |
+
Note: an NVIDIA driver must already be installed on the system (useful if only the NVIDIA driver and Docker are available).
|
| 76 |
+
|
| 77 |
+
```bash
|
| 78 |
+
git clone https://github.com/KellerJordan/modded-nanogpt.git && cd modded-nanogpt
|
| 79 |
+
sudo docker build -t modded-nanogpt .
|
| 80 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt python data/cached_fineweb10B.py 8
|
| 81 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt sh run.sh
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
To get an interactive docker, you can use
|
| 85 |
+
```bash
|
| 86 |
+
sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt bash
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
---
|
| 90 |
+
|
| 91 |
+
## World record history
|
| 92 |
+
|
| 93 |
+
The following is the historical progression of world speed records for the following competitive task:
|
| 94 |
+
|
| 95 |
+
> *Train a neural network to ≤3.28 validation loss on FineWeb using 8x NVIDIA H100s.*
|
| 96 |
+
|
| 97 |
+
Note: The 3.28 target was selected to match [Andrej Karpathy's GPT-2 (small) reproduction](https://github.com/karpathy/llm.c/discussions/481).
|
| 98 |
+
|
| 99 |
+
| # | Record time | Description | Date | Log | Contributors |
|
| 100 |
+
| - | - | - | - | - | - |
|
| 101 |
+
1 | 45 minutes | [llm.c baseline](https://github.com/karpathy/llm.c/discussions/481) | 05/28/24 | [log](records/track_1_short/2024-10-13_llmc/main.log) | @karpathy, llm.c contributors
|
| 102 |
+
2 | 31.4 minutes | [Tuned learning rate & rotary embeddings](https://x.com/kellerjordan0/status/1798863559243513937) | 06/06/24 | [log](records/track_1_short/2024-06-06_AdamW/f66d43d7-e449-4029-8adf-e8537bab49ea.log) | @kellerjordan0
|
| 103 |
+
3 | 24.9 minutes | [Introduced the Muon optimizer](https://x.com/kellerjordan0/status/1842300916864844014) | 10/04/24 | none | @kellerjordan0, @jxbz
|
| 104 |
+
4 | 22.3 minutes | [Muon improvements](https://x.com/kellerjordan0/status/1844820919061287009) | 10/11/24 | [log](records/track_1_short/2024-10-10_Muon/eb5659d0-fb6a-49e5-a311-f1f89412f726.txt) | @kellerjordan0, @bozavlado
|
| 105 |
+
5 | 15.2 minutes | [Pad embeddings, ReLU², zero-init projections, QK-norm](https://x.com/kellerjordan0/status/1845865698532450646) | 10/14/24 | [log](records/track_1_short/2024-10-14_ModernArch/dabaaddd-237c-4ec9-939d-6608a9ed5e27.txt) | @Grad62304977, @kellerjordan0
|
| 106 |
+
6 | 13.1 minutes | [Distributed the overhead of Muon](https://x.com/kellerjordan0/status/1847291684016783746) | 10/18/24 | [log](records/track_1_short/2024-10-17_DistributedMuon/22d24867-eb5a-4fcc-ae2c-263d0277dfd1.txt) | @kellerjordan0
|
| 107 |
+
7 | 12.0 minutes | [Upgraded PyTorch 2.5.0](https://x.com/kellerjordan0/status/1847358578686152764) | 10/18/24 | [log](records/track_1_short/2024-10-18_PyTorch25/d4bfb25f-688d-4da5-8743-33926fad4842.txt) | @kellerjordan0
|
| 108 |
+
8 | 10.8 minutes | [Untied embedding and head](https://x.com/kellerjordan0/status/1853188916704387239) | 11/03/24 | [log](records/track_1_short/2024-11-03_UntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.txt) | @Grad62304977, @kellerjordan0
|
| 109 |
+
9 | 8.2 minutes | [Value and embedding skip connections, momentum warmup, logit softcap](https://x.com/kellerjordan0/status/1854296101303800108) | 11/06/24 | [log](records/track_1_short/2024-11-06_ShortcutsTweaks/dd7304a6-cc43-4d5e-adb8-c070111464a1.txt) | @Grad62304977, @kellerjordan0
|
| 110 |
+
10 | 7.8 minutes | [Bfloat16 activations](https://x.com/kellerjordan0/status/1855267054774865980) | 11/08/24 | [log](records/track_1_short/2024-11-08_CastBf16/a833bed8-2fa8-4cfe-af05-58c1cc48bc30.txt) | @kellerjordan0
|
| 111 |
+
11 | 7.2 minutes | [U-net pattern skip connections & double lr](https://x.com/kellerjordan0/status/1856053121103093922) | 11/10/24 | [log](records/track_1_short/2024-11-10_UNetDoubleLr/c87bb826-797b-4f37-98c7-d3a5dad2de74.txt) | @brendanh0gan
|
| 112 |
+
12 | 5.03 minutes | [1024-ctx dense causal attention → 64K-ctx FlexAttention](https://x.com/kellerjordan0/status/1859331370268623321) | 11/19/24 | [log](records/track_1_short/2024-11-19_FlexAttention/8384493d-dba9-4991-b16b-8696953f5e6d.txt) | @KoszarskyB
|
| 113 |
+
13 | 4.66 minutes | [Attention window warmup](https://x.com/hi_tysam/status/1860851011797053450) | 11/24/24 | [log](records/track_1_short/2024-11-24_WindowWarmup/cf9e4571-c5fc-4323-abf3-a98d862ec6c8.txt) | @fernbear.bsky.social
|
| 114 |
+
14 | 4.41 minutes | [Value Embeddings](https://x.com/KoszarskyB/status/1864746625572257852) | 12/04/24 | [log](records/track_1_short/2024-12-04_ValueEmbed) | @KoszarskyB
|
| 115 |
+
15 | 3.95 minutes | [U-net pattern value embeddings, assorted code optimizations](https://x.com/YouJiacheng/status/1865761473886347747) | 12/08/24 | [log](records/track_1_short/2024-12-08_UNetValueEmbedsTweaks) | @leloykun, @YouJiacheng
|
| 116 |
+
16 | 3.80 minutes | [Split value embeddings, block sliding window, separate block mask](https://x.com/YouJiacheng/status/1866734331559071981) | 12/10/24 | [log](records/track_1_short/2024-12-10_MFUTweaks) | @YouJiacheng
|
| 117 |
+
17 | 3.57 minutes | [Sparsify value embeddings, improve rotary embeddings, drop an attn layer](https://x.com/YouJiacheng/status/1868938024731787640) | 12/17/24 | [log](records/track_1_short/2024-12-17_SparsifyEmbeds) | @YouJiacheng
|
| 118 |
+
18 | 3.4 minutes | [Lower logit softcap from 30 to 15](https://x.com/kellerjordan0/status/1876048851158880624) | 01/04/25 | [log](records/track_1_short/2025-01-04_SoftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd13fd.txt) | @KoszarskyB
|
| 119 |
+
19 | 3.142 minutes | [FP8 head, offset logits, lr decay to 0.1 instead of 0.0](https://x.com/YouJiacheng/status/1878827972519772241) | 01/13/25 | [log](records/track_1_short/2025-01-13_Fp8LmHead/c51969c2-d04c-40a7-bcea-c092c3c2d11a.txt) | @YouJiacheng
|
| 120 |
+
20 | 2.992 minutes | [Merged QKV weights, long-short attention, attention scale, lower Adam epsilon, batched Muon](https://x.com/leloykun/status/1880301753213809016) | 01/16/25 | [log](records/track_1_short/2025-01-16_Sub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt) | @leloykun, @fernbear.bsky.social, @YouJiacheng, @brendanh0gan, @scottjmaddox, @Grad62304977
|
| 121 |
+
21 | 2.933 minutes | [Reduced batch size](https://x.com/leloykun/status/1885640350368420160) | 01/26/25 | [log](records/track_1_short/2025-01-26_BatchSize/c44090cc-1b99-4c95-8624-38fb4b5834f9.txt) | @leloykun
|
| 122 |
+
21 | 2.997 minutes | 21st record with new timing | 02/01/25 | [log](records/track_1_short/2025-02-01_RuleTweak/eff63a8c-2f7e-4fc5-97ce-7f600dae0bc7.txt) | not a new record, just re-timing #21 with the [updated rules](#timing-change-after-record-21)
|
| 123 |
+
21 | 3.014 minutes | 21st record with latest torch | 05/24/25 | [log](records/track_1_short/2025-05-24_StableTorch/89d9f224-3b01-4581-966e-358d692335e0.txt) | not a new record, just re-timing #21 with latest torch
|
| 124 |
+
22 | 2.990 minutes | [Faster gradient all-reduce](https://x.com/KonstantinWille/status/1927137223238909969) | 05/24/25 | [log](records/track_1_short/2025-05-24_FasterReduce/23f40b75-06fb-4c3f-87a8-743524769a35.txt) | @KonstantinWilleke, @alexrgilbert, @adricarda, @tuttyfrutyee, @vdlad; The Enigma project
|
| 125 |
+
23 | 2.979 minutes | [Overlap computation and gradient communication](https://x.com/kellerjordan0/status/1927460573098262616) | 05/25/25 | [log](records/track_1_short/2025-05-25_EvenFasterReduce/6ae86d05-5cb2-4e40-a512-63246fd08e45.txt) | @ryanyang0
|
| 126 |
+
24 | 2.966 minutes | Replace gradient all_reduce with reduce_scatter | 05/30/25 | [log](records/track_1_short/2025-05-30_noallreduce/8054c239-3a18-499e-b0c8-dbd27cb4b3ab.txt) | @vagrawal
|
| 127 |
+
25 | 2.896 minutes | Upgrade PyTorch to 2.9.0.dev20250713+cu126 | 07/13/25 | [log](records/track_1_short/2025-07-13_UpgradeTorch190/692f80e0-5e64-4819-97d4-0dc83b7106b9.txt) | @kellerjordan0
|
| 128 |
+
26 | 2.863 minutes | Align training batch starts with EoS, increase cooldown frac to .45 | 07/13/25 | [log](records/track_1_short/2025-07-12_BosAlign/c1fd8a38-bb9f-45c4-8af0-d37f70c993f3.txt) | @classiclarryd
|
| 129 |
+
27 | 2.817 minutes | Transpose one of the MLP matrices + add Triton kernel for symmetric matmul | 07/18/25 | [log](records/track_1_short/2025-07-18_TritonMuon/record.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/109) | @byronxu99
|
| 130 |
+
28 | 2.812 minutes | Sparse attention gate | 08/23/25 | [log](records/track_1_short/2025-08-23_SparseAttnGate/020630eb-2191-4ba2-9ee4-4cdc94316943.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/117) | @classiclarryd
|
| 131 |
+
29 | 2.731 minutes | Flash Attention 3, 2048 max_doc_len, update ws schedule | 09/03/25 | [log](records/track_1_short/2025-09-03_FA3/44fc1276-0510-4961-92c0-730c65e5feba.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/118) | @varunneal
|
| 132 |
+
30 | 2.717 minutes | Drop first MLP layer | 09/05/25 | [log](records/track_1_short/2025-09-05_SkipMLPBlocks/07e7ae76-b7d0-4481-b149-01e7d81b5ad4.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/120) | @EmelyanenkoK
|
| 133 |
+
31 | 2.656 minutes | Dynamically incorporate YaRN during training and validation | 09/10/25 | [log](records/track_1_short/2025-09-10_Yarn/0ecdb695-510b-4c3b-b030-09861a162ce8.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/122) | @classiclarryd
|
| 134 |
+
32 | 2.625 minutes | Optimize distributed training, improve skip connection gating, and enhance bfloat16 usage | 09/11/25 | [log](records/track_1_short/2025-09-11_VectSigmoidBFloat16/0d0d9882-c34f-4d82-b961-a17d5659c988.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/125) | @bernard24 & hiverge.ai
|
| 135 |
+
33 | 2.565 minutes | Asynchronously fetch and index data batches, extend final layer attention window for validation | 09/15/25 | [log](records/track_1_short/2025-09-15_AsyncDataLoadAttnFinalWindow/25db37c7-2bab-4ef4-ae63-d593590ef823.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/127) | @classiclarryd
|
| 136 |
+
34 | 2.547 minutes | Smear token embeddings 1 position forward | 09/18/25 | [log](records/track_1_short/2025-09-18_Smear/18a1e5c7-947e-479d-bc3a-a57a61a98fc9.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/130) | @classiclarryd
|
| 137 |
+
35 | 2.527 minutes | Drop first attn layer, extend all long windows for validation, update schedule | 09/21/25 | [log](records/track_1_short/2025-09-21_DropAttn/01fc4a96-f2a0-47a1-8a6a-c7d10bac99fe.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/131) | @classiclarryd
|
| 138 |
+
36 | 2.495 minutes | MuonCustomSizing, perform mlp and attn reduce scatter in shared call | 09/23/25 | [log](records/track_1_short/2025-09-23_MuonCustomSizing/b067b4ac-72a6-4436-a6f8-ea51c1efeef3.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/132) | @classiclarryd
|
| 139 |
+
37 | 2.483 minutes | Compute cross entropy in BF16 during training | 09/27/25 | [log](records/track_1_short/2025-09-27_BF16CE/08c0770f-17fc-44cd-971d-734a7a28a3e3.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/133) | @Gusarich
|
| 140 |
+
38 | 2.476 minutes | Polar Express, replacement for Newton-Schulz | 09/29/25 | [log](records/track_1_short/2025-09-29_PolarExpress/0e3f0af5-ad08-47a6-813d-0c709b50d422.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/134) | @varunneal
|
| 141 |
+
39 | 2.447 minutes | Only update Adam params every other step, reduce batch size | 09/30/25 | [log](records/track_1_short/2025-09-30_CustomBatching/40b101b1-77ea-45ea-a089-1d3a647daa22.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/136) | @classiclarryd
|
| 142 |
+
40 | 2.358 minutes | Backout, misc hyperparameter tuning, optimize lambda padding | 10/04/25 | [log](records/track_1_short/2025-10-04_Backout/514e7581-fbd4-4338-a3e4-e556f9c958ce.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/140) | @classiclarryd
|
| 143 |
+
41 | 2.345 minutes | [NorMuon](https://arxiv.org/pdf/2510.05491) | 10/24/25 | [log](records/track_1_short/2025-10-24_NorMuon/088a77ee-9b67-475a-bbb9-3e92e4698799.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/144) | @li_zichong
|
| 144 |
+
42 | 2.313 minutes | Update NorMuon LR, Step Logic | 10/27/25 | [log](records/track_1_short/2025-10-27_FixMuonLR/14afd380-d3d9-48d7-ad23-4c13cb96754b.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/146) | @varunneal
|
| 145 |
+
43 | 2.284 minutes | Cautious Weight Decay w/ schedule | 11/10/25 | [log](records/track_1_short/2025-11-10_CautiousWD/1aac0132-a891-4ed9-b358-0fd2abd1b019.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/154) | @varunneal
|
| 146 |
+
44 | 2.269 minutes | Backward hooks on Adam, [Profiling 101](https://blog.underfit.ai/profiling-101-nanogpt) | 11/16/25 | [log](records/track_1_short/2025-10-31_AdamSyncGradientHook/0c17cdfd-772c-4906-8d11-141b370599a0.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/149) | @akash5474
|
| 147 |
+
45 | 2.248 minutes | Refine skip arch, update exponential decay init| 11/18/25 | [log](records/track_1_short/2025-11-18_RefineSkip/00f4e1e6-0044-4a08-b88a-3b7ec0624081.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/159) | @classiclarryd
|
| 148 |
+
46 | 2.203 minutes | [Batch size schedule](https://x.com/classiclarryd/status/1998212158770065844) | 11/29/25 | [log](records/track_1_short/2025-11-29_BatchSizeSchedule/10e8f7c6-7175-4467-bdb0-a5de25d771a6.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/163) | @varunneal
|
| 149 |
+
47 | 2.193 minutes | [Multiply attn lambda with weight instead of data, fix warmup](https://x.com/classiclarryd/status/1999630732814348451) | 12/10/25 | [log](records/track_1_short/2025-12-10_SALambdaOnWeights/15ef5eaf-56e1-40e1-9ddf-af010027c9dd.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/166) | @roeeshenberg
|
| 150 |
+
48 | 2.170 minutes | [Speed up Muon, additional pre-multiply lambda, reshape matrices, update lr, update NorMuon axis](https://x.com/classiclarryd/status/2000272495644152317) | 12/11/25 | [log](records/track_1_short/2025-12-11_NorMuonOptimsAndFixes/82edf6be-f343-475d-b93a-47c32acf4de2.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/168) | @ChrisJMcCormick
|
| 151 |
+
49 | 2.146 minutes | [Partial Key Offset](https://x.com/classiclarryd/status/2000841339299402142) | 12/14/25 | [log](records/track_1_short/2025-12-14_PartialKeyOffset/150d40bf-c20b-4568-aac9-26eb919e25fd.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/169) | @classiclarryd
|
| 152 |
+
50 | 2.128 minutes | [Extend Cautious Weight Decay to Adam parameters](https://x.com/classiclarryd/status/2002482925741486381) | 12/18/25 | [log](records/track_1_short/2025-12-18_CautiousWDAdam/1981d492-bc65-4ba9-a0fa-2b30fc5c3eba.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/172) | @roeeshenberg
|
| 153 |
+
51 | 2.075 minutes | [Retie Embed to lm_head, retune fp8 scales](https://x.com/classiclarryd/status/2003167208483209668) | 12/19/25 | [log](records/track_1_short/2025-12-19_RetieLMHead/0828d309-ecfe-4442-9ee9-68fed3a4b599.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/175) | @varunneal
|
| 154 |
+
52 | 2.037 minutes | [Smooth scalars via beta increase, decrease smear gate lr, freeze scalars during transitions, adam all reduce](https://x.com/classiclarryd/status/2003863282613190656) | 12/21/25 | [log](records/track_1_short/2025-12-21_SmoothedScalars/12-21-Smoothed-Scalars/0bc6e909-8ee8-4ae3-ac62-0070e151a808.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/177) | @ChrisJMcCormick
|
| 155 |
+
53 | 1.988 minutes | [Multi-token prediction, untie embed/lm_head at 2/3 training, lr update, tweak CWD](https://x.com/classiclarryd/status/2004248941878296580) | 12/22/25 | [log](records/track_1_short/2025-12-22_MultiTokenPrediction/17aaf854-f338-4d0d-9767-a5db30fd7980.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/178) | @varunneal, feat. @classiclarryd
|
| 156 |
+
54 | 1.940 minutes | [Asymmetric Logit Rescale](https://x.com/classiclarryd/status/2004791008098480232) | 12/26/25 | [log](records/track_1_short/2025-12-26_LogitRescale/03e41c2d-2951-4546-a599-24cd723247fc.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/181) | @classiclarryd
|
| 157 |
+
55 | 1.918 minutes | [Gates on value embeds and skip connection](https://x.com/classiclarryd/status/2005659526960492638) | 12/29/25 | [log](records/track_1_short/2025-12-29_VeSkipGates/2851d7dc-d6a5-4e74-8623-57031425db16.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/186) | @classiclarryd
|
| 158 |
+
56 | 1.894 minutes | [Optimize and compile Adam, increase Adam buffer precision, move gates from Muon to Adam parameter banks](https://x.com/classiclarryd/status/2007882371576873445) | 12/31/25 | [log](records/track_1_short/2025-12-31_GatesToCompiledAdam/12-31-gates-to-adam-20stps/219a5f2f-151e-4c56-ab91-3735ae4610b8.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/187) | @ChrisJMcCormick
|
| 159 |
+
57 | 1.878 minutes | [Bfloat16 attn/mlp weights, mixed precision Muon, interweave Adam/Muon, finer-grain Adam beta](https://x.com/classiclarryd/status/2008261904566022590) | 01/04/26 | [log](records/track_1_short/2026-01-04_MixedPrecisionInterweavedOptimizer/41f606b6-1b9c-46a3-b46e-2beff1521d18.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/190) | @classiclarryd, feat. @YouJiacheng, @ChrisJMcCormick
|
| 160 |
+
58 | 1.820 minutes | [Paired Head Attention](https://x.com/classiclarryd/status/2008963501688324228) | 01/07/26 | [log](records/track_1_short/2026-01-07_PairedHeadAttention/2a5d5cde-db5f-4aab-a4a8-cc8e183ea671.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/191) | @classiclarryd
|
| 161 |
+
59 | 1.781 minutes | Fused linear relu square triton kernel | 01/10/26 | [log](records/track_1_short/2026-01-10_FusedLinearReLUSquare/3c47e63b-075e-4b5b-9c76-9dbe7bad9ad4.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/197) | @andrewbriand, @jrauvola
|
| 162 |
+
## Rules
|
| 163 |
+
|
| 164 |
+
New records must:
|
| 165 |
+
|
| 166 |
+
1. Not modify the train or validation data pipelines. (You can change the batch size, sequence length, attention structure etc.; just don't change the underlying streams of tokens.)
|
| 167 |
+
2. Attain ≤3.28 mean val loss. (Due to inter-run variance, submissions must provide enough run logs to attain a statistical significance level of p<0.01 that their mean val loss is ≤3.28. Example code to compute p-value can be found [here](records/track_1_short/2025-01-04_SoftCap#softer-softcap). For submissions which improve speed by optimizing the systems performance, without touching the ML, this requirement is waived.)
|
| 168 |
+
3. Not use any extra `torch._inductor.config` or `torch.compile` flags. (These can save a few seconds, but they can also make compilation take >30min. This rule was introduced after the 21st record.)
|
| 169 |
+
4. Run faster than the prior record when baselined on the same hardware.
|
| 170 |
+
|
| 171 |
+
Discretionary reasons why a PR may not be accepted:
|
| 172 |
+
1. Disproportionately degrades the readability of the codebase. A 200 line kernel to drop 300ms is considered worthwhile. 500 lines that convolute the optimizer layout for a 50ms gain will likely be rejected.
|
| 173 |
+
2. The current record is intentionally kept roughly 0.001-0.002 loss below 3.28 to make validation simpler. If a PR substantially consumes this buffer, it should do so in a way that outperforms a simple step count decrease, when measured at equivalent loss.
|
| 174 |
+
|
| 175 |
+
> Note: `torch._inductor.config.coordinate_descent_tuning` is allowed for GPT-2 Medium track (a.k.a. 2.92 track).
|
| 176 |
+
|
| 177 |
+
Other than that, anything and everything is fair game!
|
| 178 |
+
|
| 179 |
+
[further clarifications](https://github.com/KellerJordan/modded-nanogpt/discussions/23?sort=new#discussioncomment-12109560)
|
| 180 |
+
|
| 181 |
+
---
|
| 182 |
+
|
| 183 |
+
### Comment on the target metric
|
| 184 |
+
|
| 185 |
+
The target metric is *cross-entropy loss on the FineWeb val set*. To speak mathematically, the goal of the speedrun is *to obtain a probability model of language which assigns a probability of at least `math.exp(-3.28 * 10485760)` to the first 10,485,760 tokens of the FineWeb valset. Hence, e.g., we allow evaluation at any sequence length, so long as we still have a valid probability model of language.
|
| 186 |
+
|
| 187 |
+
---
|
| 188 |
+
|
| 189 |
+
### Timing change after record 21
|
| 190 |
+
|
| 191 |
+
After the 21st record, we made two changes to the timing. First, there used to be an initial "grace period" of 10 untimed steps to allow kernel warmup. We replaced this with an explicit kernel-warmup section which is untimed and uses dummy data. This results in an extra runtime of 850ms from the 10 extra timed steps.
|
| 192 |
+
Second, we banned the use of `torch._inductor.config.coordinate_descent_tuning`. This saves ~25min of untimed pre-run compilation, but results in an extra runtime of ~3s.
|
| 193 |
+
|
| 194 |
+
<!--Note: The original llm.c baseline is intended to be closer to a replication of GPT-2 than to an optimized LLM training.
|
| 195 |
+
So it's no surprise that there is room to improve; as @karpathy has said, 'llm.c still has a lot of pending optimizations.'
|
| 196 |
+
In addition, many of the techniques used in these records are completely standard, such as rotary embeddings.
|
| 197 |
+
The goal of this benchmark/speedrun is simply to find out which techniques actually work, and maybe come up with some new ones.-->
|
| 198 |
+
<!--The goal of this benchmark is simply to find out all the techniques which actually work, because I'm going crazy reading all these
|
| 199 |
+
LLM training papers
|
| 200 |
+
which claim a huge benefit but then use their own idiosyncratic non-competitive benchmark and therefore no one in the community has any idea if it's legit for months.-->
|
| 201 |
+
<!--[LLM](https://arxiv.org/abs/2305.14342) [training](https://arxiv.org/abs/2402.17764) [papers](https://arxiv.org/abs/2410.01131)-->
|
| 202 |
+
<!--I mean hello??? We're in a completely empirical field; it is insane to not have a benchmark. Ideally everyone uses the same LLM training benchmark,
|
| 203 |
+
and then reviewing LLM training papers becomes as simple as checking if they beat the benchmark. It's not like this would be unprecedented, that's how things
|
| 204 |
+
were in the ImageNet days.
|
| 205 |
+
The only possible 'benefit' I can think of for any empirical field to abandon benchmarks is that it would make it easier to publish false results. Oh, I guess that's why it happened.
|
| 206 |
+
Hilarious to think about how, in the often-commented-upon and ongoing collapse of the peer review system, people blame the *reviewers* --
|
| 207 |
+
yeah, those guys doing free labor who everyone constantly musters all of their intelligence to lie to, it's *their* fault! My bad, you caught me monologuing.-->
|
| 208 |
+
|
| 209 |
+
---
|
| 210 |
+
|
| 211 |
+
### Notable attempts & forks
|
| 212 |
+
|
| 213 |
+
**Notable runs:**
|
| 214 |
+
|
| 215 |
+
* [@alexjc's 01/20/2025 2.77-minute TokenMonster-based record](https://x.com/alexjc/status/1881410039639863622).
|
| 216 |
+
This record is technically outside the rules of the speedrun, since we specified that the train/val tokens must be kept fixed.
|
| 217 |
+
However, it's very interesting, and worth including. The run is not more data-efficient; rather, the speedup comes from the improved tokenizer allowing
|
| 218 |
+
the vocabulary size to be reduced (nearly halved!) while preserving the same bytes-per-token, which saves lots of parameters and FLOPs in the head and embeddings.
|
| 219 |
+
|
| 220 |
+
**Notable forks:**
|
| 221 |
+
* [https://github.com/BlinkDL/modded-nanogpt-rwkv](https://github.com/BlinkDL/modded-nanogpt-rwkv)
|
| 222 |
+
* [https://github.com/nikhilvyas/modded-nanogpt-SOAP](https://github.com/nikhilvyas/modded-nanogpt-SOAP)
|
| 223 |
+
|
| 224 |
+
---
|
| 225 |
+
|
| 226 |
+
## Speedrun track 2: GPT-2 Medium
|
| 227 |
+
|
| 228 |
+
The target loss for this track is lowered from 3.28 to 2.92, as per Andrej Karpathy's 350M-parameter llm.c baseline.
|
| 229 |
+
This baseline generates a model with performance similar to the original GPT-2 Medium, whereas the first track's baseline generates a model on par with GPT-2 Small.
|
| 230 |
+
All other rules remain the same.
|
| 231 |
+
|
| 232 |
+
> Note: `torch._inductor.config.coordinate_descent_tuning` is turned on after the record 6 (*).
|
| 233 |
+
|
| 234 |
+
| # | Record time | Description | Date | Log | Contributors |
|
| 235 |
+
| - | - | - | - | - | - |
|
| 236 |
+
1 | 5.8 hours | [llm.c baseline (350M parameters)](https://github.com/karpathy/llm.c/discussions/481) | 05/28/24 | [log](records/track_2_medium/2025-01-18/main.log) | @karpathy, llm.c contributors
|
| 237 |
+
2 | 29.3 minutes | [Initial record based on scaling up the GPT-2 small track speedrun](https://x.com/kellerjordan0/status/1881959719012847703) | 01/18/25 | [log](records/track_2_medium/2025-01-18/241dd7a7-3d76-4dce-85a4-7df60387f32a.txt) | @kellerjordan0
|
| 238 |
+
3 | 28.1 minutes | [Added standard weight decay](https://x.com/kellerjordan0/status/1888320690543284449) | 02/08/25 | [log](records/track_2_medium/2025-02-08_WeightDecay/b01743db-605c-4326-b5b1-d388ee5bebc5.txt) | @kellerjordan0
|
| 239 |
+
4 | 27.7 minutes | [Tuned Muon Newton-Schulz coefficients](https://x.com/leloykun/status/1892793848163946799) | 02/14/25 | [log](records/track_2_medium/2025-02-14_OptCoeffs/1baa66b2-bff7-4850-aced-d63885ffb4b6.txt) | @leloykun
|
| 240 |
+
5 | 27.2 minutes | [Increased learning rate cooldown phase duration](records/track_2_medium/2025-03-06_LongerCooldown/779c041a-2a37-45d2-a18b-ec0f223c2bb7.txt) | 03/06/25 | [log](records/track_2_medium/2025-03-06_LongerCooldown/779c041a-2a37-45d2-a18b-ec0f223c2bb7.txt) | @YouJiacheng
|
| 241 |
+
6 | 25.95 minutes* | [2x MLP wd, qkv norm, all_reduce/opt.step() overlap, optimized skip pattern](https://x.com/YouJiacheng/status/1905861218138804534) | 03/25/25 | [log](records/track_2_medium/2025-03-25_ArchOptTweaks/train_gpt-20250329.txt) | @YouJiacheng
|
| 242 |
+
7 | 25.29 minutes | [Remove FP8 head; ISRU logits softcap; New sharded mixed precision Muon; merge weights](https://x.com/YouJiacheng/status/1912570883878842527) | 04/16/25 | [log](records/track_2_medium/2025-04-16_Record7/223_3310d0b1-b24d-48ee-899f-d5c2a254a195.txt) | @YouJiacheng
|
| 243 |
+
8 | 24.50 minutes | [Cubic sliding window size schedule, 2× max window size (24.84 minutes)](https://x.com/jadenj3o/status/1914893086276169754) [24.5min repro](https://x.com/YouJiacheng/status/1915667616913645985) | 04/22/25 | [log](records/track_2_medium/2025-04-22_Record8/075_640429f2-e726-4e83-aa27-684626239ffc.txt) | @jadenj3o
|
| 244 |
+
9 | 24.12 minutes | [Add two value embeddings](https://snimu.github.io/2025/10/07/modded-nanogpt-value-embeddings.html) | 08/28/25 | [log](records/track_2_medium/2025-08-28_NewValemb/036_61ef4351-7b68-4897-b440-a99221a1a629.txt), [PR](https://github.com/KellerJordan/modded-nanogpt/pull/119) | @snimu
|
| 245 |
+
10 | 24.07 minutes | [Second input embedding](https://snimu.github.io/2025/10/10/modded-nanogpt-x0.html) | 09/11/25 | [log](records/track_2_medium/2025-09-11_SecondInputEmbed/000_592014ec-6781-4f59-b274-c4af68ccfe75.txt), [PR](https://github.com/KellerJordan/modded-nanogpt/pull/124) | @snimu
|
| 246 |
+
11 | 23.45 minutes | Upgrade from torch 2.7 to torch==2.10.0.dev20251210+cu126 | - | - | -
|
| 247 |
+
12 | 23.28 minutes | Snoo Optimizer (Outer optimizer around Adam and Muon) | 09/16/25 | [log](records/track_2_medium/2025-09-16_Snoo/000_01db7a67-f715-4114-a7b5-6bfe23bac1b1.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/128) | @dominikkallusky
|
| 248 |
+
13 | 23.14 minutes | EMA Wrapper on Muon | 09/17/25 | [log](records/track_2_medium/2025-09-17_UpdateSmoothing/001_8379f695-6bc3-4f76-b58b-8fadd3b6ebb0.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/129) | @acutkosky
|
| 249 |
+
14 | 23.08 minutes | Combine both records 12 & 13 | 09/30/25 | [log](records/track_2_medium/2025-09-30_SmoothedSnooMedium/101_5bc91cd0-cb46-428c-a5da-9d8d228f1f97.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/137) | @acutkosky
|
| 250 |
+
15 | 23.03 minutes | Backout (Skip from 2/3 point to pre-lm_head) | 10/04/25 | [log](records/track_2_medium/2025-10-04_GPT2MediumLayerReuse/000_cc3943e4-02b5-4ae3-9441-839d32dfd9b2.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/139) | @snimu
|
| 251 |
+
16 | 22.99 minutes | Smear-MTP | 11/02/25 | [log](records/track_2_medium/2025-11-02-Smear-MTP/000_3b50518d-d542-44bc-8566-3abf633f83ad.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/151) | @snimu
|
| 252 |
+
17 | 22.98 minutes | Remove Redundant Mask Op | 11/12/25 | [log](records/track_2_medium/2025-11-12_BlockMaskRedundantOp/000_3b22a9d4-b52e-4916-99bf-3d48b38747a7.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/157/) | @manikbhandari
|
| 253 |
+
18 | 17.35 minutes | Bulk transfer short track features | 12/31/25 | [log](records/track_2_medium/2025-12-31_BulkSmallTrackTransfer/354be270-7d41-44b7-8064-f040923f024f.txt),[PR](https://github.com/KellerJordan/modded-nanogpt/pull/188) | -
|
| 254 |
+
---
|
| 255 |
+
|
| 256 |
+
### Q: What is the point of NanoGPT speedrunning?
|
| 257 |
+
|
| 258 |
+
A: The officially stated goal of NanoGPT speedrunning is as follows: `gotta go fast`. But for something a little more verbose involving an argument for good benchmarking, here's some kind of manifesto, adorned with a blessing from the master. [https://x.com/karpathy/status/1846790537262571739](https://x.com/karpathy/status/1846790537262571739)
|
| 259 |
+
|
| 260 |
+
### Q: What makes "NanoGPT speedrunning" not just another idiosyncratic benchmark?
|
| 261 |
+
|
| 262 |
+
A: Because it is a *competitive* benchmark. In particular, if you attain a new speed record (using whatever method you want), there is an open invitation for you
|
| 263 |
+
to post that record (on arXiv or X) and thereby vacuum up all the clout for yourself. I will even help you do it by reposting you as much as I can.
|
| 264 |
+
|
| 265 |
+
<!--On the contrary, for example, the benchmark used in the [Sophia](https://arxiv.org/abs/2305.14342) paper does *not* have this property.
|
| 266 |
+
There is no such open invitation for anyone to compete on the benchmark they used. In particular, if, for a random and definitely not weirdly specific example, you happen to find better AdamW hyperparameters for their training setup than
|
| 267 |
+
the ones they used which significantly close the gap between AdamW and their proposed optimizer,
|
| 268 |
+
then there is no clear path for you to publish that result in *any* form.
|
| 269 |
+
You could try posting it on X.com, but then you would be risking being perceived as aggressive/confrontational, which is *not a good look* in this racket.
|
| 270 |
+
So if you're rational, the result probably just dies with you and no one else learns anything
|
| 271 |
+
(unless you're in a frontier lab, in which case you can do a nice internal writeup. Boy I'd love to get my hands on those writeups).-->
|
| 272 |
+
|
| 273 |
+
["Artificial intelligence advances by inventing games and gloating to goad others to play" - Professor Ben Recht](https://www.argmin.net/p/too-much-information)
|
| 274 |
+
|
| 275 |
+
### Q: NanoGPT speedrunning is cool and all, but meh it probably won't scale and is just overfitting to val loss
|
| 276 |
+
|
| 277 |
+
A: This is hard to refute, since "at scale" is an infinite category (what if the methods stop working only for >100T models?), making it impossible to fully prove.
|
| 278 |
+
Also, I would agree that some of the methods used in the speedrun are unlikely to scale, particularly those which *impose additional structure* on the network, such as logit softcapping.
|
| 279 |
+
But if the reader cares about 1.5B models, they might be convinced by this result:
|
| 280 |
+
|
| 281 |
+
*Straightforwardly scaling up the speedrun (10/18/24 version) to 1.5B parameters yields a model with GPT-2 (1.5B)-level HellaSwag performance 2.5x more cheaply than [@karpathy's baseline](https://github.com/karpathy/llm.c/discussions/677) ($233 instead of $576):*
|
| 282 |
+
|
| 283 |
+

|
| 284 |
+
[[reproducible log](https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/2024-10-20_ScaleUp1B/ad8d7ae5-7b2d-4ee9-bc52-f912e9174d7a.txt)]
|
| 285 |
+

|
| 286 |
+
|
| 287 |
+
---
|
| 288 |
+
|
| 289 |
+
## [Muon optimizer](https://github.com/KellerJordan/Muon)
|
| 290 |
+
|
| 291 |
+
Muon is defined as follows:
|
| 292 |
+
|
| 293 |
+

|
| 294 |
+
|
| 295 |
+
Where NewtonSchulz5 is the following Newton-Schulz iteration [2, 3], which approximately replaces `G` with `U @ V.T` where `U, S, V = G.svd()`.
|
| 296 |
+
```python
|
| 297 |
+
@torch.compile
|
| 298 |
+
def zeroth_power_via_newtonschulz5(G, steps=5, eps=1e-7):
|
| 299 |
+
assert len(G.shape) == 2
|
| 300 |
+
a, b, c = (3.4445, -4.7750, 2.0315)
|
| 301 |
+
X = G.bfloat16() / (G.norm() + eps)
|
| 302 |
+
if G.size(0) > G.size(1):
|
| 303 |
+
X = X.T
|
| 304 |
+
for _ in range(steps):
|
| 305 |
+
A = X @ X.T
|
| 306 |
+
B = b * A + c * A @ A
|
| 307 |
+
X = a * X + B @ X
|
| 308 |
+
if G.size(0) > G.size(1):
|
| 309 |
+
X = X.T
|
| 310 |
+
return X.to(G.dtype)
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
For this training scenario, Muon has the following favorable properties:
|
| 314 |
+
* Lower memory usage than Adam
|
| 315 |
+
* ~1.5x better sample-efficiency
|
| 316 |
+
* <2% wallclock overhead
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
### Provenance
|
| 320 |
+
|
| 321 |
+
Many of the choices made to generate this optimizer were obtained experimentally by our pursuit of [CIFAR-10 speedrunning](https://github.com/KellerJordan/cifar10-airbench).
|
| 322 |
+
In particular, we experimentally obtained the following practices:
|
| 323 |
+
* Using Nesterov momentum inside the update, with orthogonalization applied after momentum.
|
| 324 |
+
* Using a specifically quintic Newton-Schulz iteration as the method of orthogonalization.
|
| 325 |
+
* Using non-convergent coefficients for the quintic polynomial in order to maximize slope at zero, and thereby minimize the number of necessary Newton-Schulz iterations.
|
| 326 |
+
It turns out that the variance doesn't actually matter that much, so we end up with a quintic that rapidly converges to the range 0.68, 1.13 upon repeated application, rather than converging more slowly to 1.
|
| 327 |
+
* Running the Newton-Schulz iteration in bfloat16 (whereas Shampoo implementations often depend on inverse-pth-roots run in fp32 or fp64).
|
| 328 |
+
|
| 329 |
+
Our use of a Newton-Schulz iteration for orthogonalization traces to [Bernstein & Newhouse (2024)](https://arxiv.org/abs/2409.20325),
|
| 330 |
+
who suggested it as a way to compute Shampoo [5, 6] preconditioners, and theoretically explored Shampoo without preconditioner accumulation.
|
| 331 |
+
In particular, Jeremy Bernstein @jxbz sent us the draft, which caused us to experiment with various Newton-Schulz iterations as the
|
| 332 |
+
orthogonalization method for this optimizer.
|
| 333 |
+
If we had used SVD instead of a Newton-Schulz iteration, this optimizer would have been too slow to be useful.
|
| 334 |
+
Bernstein & Newhouse also pointed out that Shampoo without preconditioner accumulation is equivalent to steepest descent in the spectral norm,
|
| 335 |
+
and therefore Shampoo can be thought of as a way to smooth out spectral steepest descent.
|
| 336 |
+
The proposed optimizer can be thought of as a second way of smoothing spectral steepest descent, with a different set of memory and runtime tradeoffs
|
| 337 |
+
compared to Shampoo.
|
| 338 |
+
|
| 339 |
+
---
|
| 340 |
+
|
| 341 |
+
## Running on fewer GPUs
|
| 342 |
+
|
| 343 |
+
* To run experiments on fewer GPUs, simply modify `run.sh` to have a different `--nproc_per_node`. This should not change the behavior of the training.
|
| 344 |
+
* If you're running out of memory, you may need to reduce the sequence length for FlexAttention (which does change the training. see [here](https://github.com/KellerJordan/modded-nanogpt/pull/38) for a guide)
|
| 345 |
+
|
| 346 |
+
---
|
| 347 |
+
|
| 348 |
+
## References
|
| 349 |
+
|
| 350 |
+
1. [Guilherme Penedo et al. "The fineweb datasets: Decanting the web for the finest text data at scale." arXiv preprint arXiv:2406.17557 (2024).](https://arxiv.org/abs/2406.17557)
|
| 351 |
+
2. Nicholas J. Higham. Functions of Matrices. Society for Industrial and Applied Mathematics (2008). Equation 5.22.
|
| 352 |
+
3. Günther Schulz. Iterative Berechnung der reziproken Matrix. Z. Angew. Math. Mech., 13:57â59 (1933).
|
| 353 |
+
4. [Jeremy Bernstein and Laker Newhouse. "Old Optimizer, New Norm: An Anthology." arxiv preprint arXiv:2409.20325 (2024).](https://arxiv.org/abs/2409.20325)
|
| 354 |
+
5. [Vineet Gupta, Tomer Koren, and Yoram Singer. "Shampoo: Preconditioned stochastic tensor optimization." International Conference on Machine Learning. PMLR, 2018.](https://arxiv.org/abs/1802.09568)
|
| 355 |
+
6. [Rohan Anil et al. "Scalable second order optimization for deep learning." arXiv preprint arXiv:2002.09018 (2020).](https://arxiv.org/abs/2002.09018)
|
| 356 |
+
7. [Alexander Hägele et al. "Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations." arXiv preprint arXiv:2405.18392 (2024).](https://arxiv.org/abs/2405.18392)
|
| 357 |
+
8. [Zhanchao Zhou et al. "Value Residual Learning For Alleviating Attention Concentration In Transformers." arXiv preprint arXiv:2410.17897 (2024).](https://arxiv.org/abs/2410.17897)
|
| 358 |
+
9. [Team, Gemma, et al. "Gemma 2: Improving open language models at a practical size." arXiv preprint arXiv:2408.00118 (2024).](https://arxiv.org/abs/2408.00118)
|
| 359 |
+
10. [Alec Radford et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019).](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
|
| 360 |
+
|
| 361 |
+
## Citation
|
| 362 |
+
|
| 363 |
+
```
|
| 364 |
+
@misc{modded_nanogpt_2024,
|
| 365 |
+
author = {Keller Jordan and Jeremy Bernstein and Brendan Rappazzo and
|
| 366 |
+
@fernbear.bsky.social and Boza Vlado and You Jiacheng and
|
| 367 |
+
Franz Cesista and Braden Koszarsky and @Grad62304977},
|
| 368 |
+
title = {modded-nanogpt: Speedrunning the NanoGPT baseline},
|
| 369 |
+
year = {2024},
|
| 370 |
+
url = {https://github.com/KellerJordan/modded-nanogpt}
|
| 371 |
+
}
|
| 372 |
+
```
|
| 373 |
+
|
| 374 |
+
<img src="img/dofa.jpg" alt="itsover_wereback" style="width:100%;">
|
| 375 |
+
|
data/cached_fineweb100B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of Fineweb100B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'fineweb100B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/fineweb100B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("fineweb_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 1030 # full fineweb100B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("fineweb_train_%06d.bin" % i)
|
data/cached_fineweb10B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of Fineweb10B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'fineweb10B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/fineweb10B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("fineweb_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 103 # full fineweb10B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("fineweb_train_%06d.bin" % i)
|
data/cached_finewebedu10B.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
# Download the GPT-2 tokens of FinewebEDU10B from huggingface. This
|
| 5 |
+
# saves about an hour of startup time compared to regenerating them.
|
| 6 |
+
def get(fname):
|
| 7 |
+
local_dir = os.path.join(os.path.dirname(__file__), 'finewebedu10B')
|
| 8 |
+
if not os.path.exists(os.path.join(local_dir, fname)):
|
| 9 |
+
hf_hub_download(repo_id="kjj0/finewebedu10B-gpt2", filename=fname,
|
| 10 |
+
repo_type="dataset", local_dir=local_dir)
|
| 11 |
+
get("finewebedu_val_%06d.bin" % 0)
|
| 12 |
+
num_chunks = 99 # full FinewebEDU10B. Each chunk is 100M tokens
|
| 13 |
+
if len(sys.argv) >= 2: # we can pass an argument to download less
|
| 14 |
+
num_chunks = int(sys.argv[1])
|
| 15 |
+
for i in range(1, num_chunks+1):
|
| 16 |
+
get("finewebedu_train_%06d.bin" % i)
|
data/fineweb.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
FineWeb dataset (for srs pretraining)
|
| 3 |
+
https://huggingface.co/datasets/HuggingFaceFW/fineweb
|
| 4 |
+
|
| 5 |
+
example doc to highlight the structure of the dataset:
|
| 6 |
+
{
|
| 7 |
+
"text": "Posted by mattsmith on 20th April 2012\nStraight from...",
|
| 8 |
+
"id": "<urn:uuid:d853d453-196e-4488-a411-efc2b26c40d2>",
|
| 9 |
+
"dump": "CC-MAIN-2013-20",
|
| 10 |
+
"url": "http://nleastchatter.com/philliesphandom/tag/freddy-galvis/",
|
| 11 |
+
"date": "2013-05-18T07:24:47Z",
|
| 12 |
+
"file_path": "s3://commoncrawl/long.../path.../file.gz",
|
| 13 |
+
"language": "en",
|
| 14 |
+
"language_score": 0.9185474514961243,
|
| 15 |
+
"token_count": 594
|
| 16 |
+
}
|
| 17 |
+
"""
|
| 18 |
+
import os
|
| 19 |
+
import argparse
|
| 20 |
+
import multiprocessing as mp
|
| 21 |
+
import numpy as np
|
| 22 |
+
import tiktoken
|
| 23 |
+
# from huggingface_hub import snapshot_download
|
| 24 |
+
from datasets import load_dataset
|
| 25 |
+
from tqdm import tqdm
|
| 26 |
+
import argparse
|
| 27 |
+
import numpy as np
|
| 28 |
+
def write_datafile(filename, toks):
|
| 29 |
+
"""
|
| 30 |
+
Saves token data as a .bin file, for reading in C.
|
| 31 |
+
- First comes a header with 256 int32s
|
| 32 |
+
- The tokens follow, each as a uint16
|
| 33 |
+
"""
|
| 34 |
+
assert len(toks) < 2**31, "token count too large" # ~2.1B tokens
|
| 35 |
+
# construct the header
|
| 36 |
+
header = np.zeros(256, dtype=np.int32)
|
| 37 |
+
header[0] = 20240520 # magic
|
| 38 |
+
header[1] = 1 # version
|
| 39 |
+
header[2] = len(toks) # number of tokens after the 256*4 bytes of header (each 2 bytes as uint16)
|
| 40 |
+
# construct the tokens numpy array, if not already
|
| 41 |
+
if not isinstance(toks, np.ndarray) or not toks.dtype == np.uint16:
|
| 42 |
+
# validate that no token exceeds a uint16
|
| 43 |
+
maxtok = 2**16
|
| 44 |
+
assert all(0 <= t < maxtok for t in toks), "token dictionary too large for uint16"
|
| 45 |
+
toks_np = np.array(toks, dtype=np.uint16)
|
| 46 |
+
else:
|
| 47 |
+
toks_np = toks
|
| 48 |
+
# write to file
|
| 49 |
+
print(f"writing {len(toks):,} tokens to {filename}")
|
| 50 |
+
with open(filename, "wb") as f:
|
| 51 |
+
f.write(header.tobytes())
|
| 52 |
+
f.write(toks_np.tobytes())
|
| 53 |
+
# ------------------------------------------
|
| 54 |
+
|
| 55 |
+
parser = argparse.ArgumentParser(description="FineWeb dataset preprocessing")
|
| 56 |
+
parser.add_argument("-v", "--version", type=str, default="10B", help="Which version of fineweb to use 10B|100B")
|
| 57 |
+
parser.add_argument("-s", "--shard_size", type=int, default=10**8, help="Size of each shard in tokens")
|
| 58 |
+
args = parser.parse_args()
|
| 59 |
+
|
| 60 |
+
# FineWeb has a few possible subsamples available
|
| 61 |
+
assert args.version in ["10B", "100B"], "version must be one of 10B, 100B"
|
| 62 |
+
if args.version == "10B":
|
| 63 |
+
local_dir = "fineweb10B"
|
| 64 |
+
remote_name = "sample-10BT"
|
| 65 |
+
elif args.version == "100B":
|
| 66 |
+
local_dir = "fineweb100B"
|
| 67 |
+
remote_name = "sample-100BT"
|
| 68 |
+
|
| 69 |
+
# create the cache the local directory if it doesn't exist yet
|
| 70 |
+
DATA_CACHE_DIR = os.path.join(os.path.dirname(__file__), local_dir)
|
| 71 |
+
os.makedirs(DATA_CACHE_DIR, exist_ok=True)
|
| 72 |
+
|
| 73 |
+
# download the dataset
|
| 74 |
+
fw = load_dataset("HuggingFaceFW/fineweb", name=remote_name, split="train")
|
| 75 |
+
|
| 76 |
+
# init the tokenizer
|
| 77 |
+
enc = tiktoken.get_encoding("gpt2")
|
| 78 |
+
eot = enc._special_tokens['<|endoftext|>'] # end of text token
|
| 79 |
+
def tokenize(doc):
|
| 80 |
+
# tokenizes a single document and returns a numpy array of uint16 tokens
|
| 81 |
+
tokens = [eot] # the special <|endoftext|> token delimits all documents
|
| 82 |
+
tokens.extend(enc.encode_ordinary(doc["text"]))
|
| 83 |
+
tokens_np = np.array(tokens)
|
| 84 |
+
assert (0 <= tokens_np).all() and (tokens_np < 2**16).all(), "token dictionary too large for uint16"
|
| 85 |
+
tokens_np_uint16 = tokens_np.astype(np.uint16)
|
| 86 |
+
return tokens_np_uint16
|
| 87 |
+
|
| 88 |
+
# tokenize all documents and write output shards, each of shard_size tokens (last shard has remainder)
|
| 89 |
+
nprocs = max(1, os.cpu_count() - 2) # don't hog the entire system
|
| 90 |
+
with mp.Pool(nprocs) as pool:
|
| 91 |
+
shard_index = 0
|
| 92 |
+
# preallocate buffer to hold current shard
|
| 93 |
+
all_tokens_np = np.empty((args.shard_size,), dtype=np.uint16)
|
| 94 |
+
token_count = 0
|
| 95 |
+
progress_bar = None
|
| 96 |
+
for tokens in pool.imap(tokenize, fw, chunksize=16):
|
| 97 |
+
|
| 98 |
+
# is there enough space in the current shard for the new tokens?
|
| 99 |
+
if token_count + len(tokens) < args.shard_size:
|
| 100 |
+
# simply append tokens to current shard
|
| 101 |
+
all_tokens_np[token_count:token_count+len(tokens)] = tokens
|
| 102 |
+
token_count += len(tokens)
|
| 103 |
+
# update progress bar
|
| 104 |
+
if progress_bar is None:
|
| 105 |
+
progress_bar = tqdm(total=args.shard_size, unit="tokens", desc=f"Shard {shard_index}")
|
| 106 |
+
progress_bar.update(len(tokens))
|
| 107 |
+
else:
|
| 108 |
+
# write the current shard and start a new one
|
| 109 |
+
split = "val" if shard_index == 0 else "train"
|
| 110 |
+
filename = os.path.join(DATA_CACHE_DIR, f"fineweb_{split}_{shard_index:06d}.bin")
|
| 111 |
+
# split the document into whatever fits in this shard; the remainder goes to next one
|
| 112 |
+
remainder = args.shard_size - token_count
|
| 113 |
+
progress_bar.update(remainder)
|
| 114 |
+
all_tokens_np[token_count:token_count+remainder] = tokens[:remainder]
|
| 115 |
+
write_datafile(filename, all_tokens_np)
|
| 116 |
+
shard_index += 1
|
| 117 |
+
progress_bar = None
|
| 118 |
+
# populate the next shard with the leftovers of the current doc
|
| 119 |
+
all_tokens_np[0:len(tokens)-remainder] = tokens[remainder:]
|
| 120 |
+
token_count = len(tokens)-remainder
|
| 121 |
+
|
| 122 |
+
# write any remaining tokens as the last shard
|
| 123 |
+
if token_count != 0:
|
| 124 |
+
split = "val" if shard_index == 0 else "train"
|
| 125 |
+
filename = os.path.join(DATA_CACHE_DIR, f"fineweb_{split}_{shard_index:06d}.bin")
|
| 126 |
+
write_datafile(filename, all_tokens_np[:token_count])
|
data/requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets
|
| 2 |
+
tiktoken
|
img/algo_optimizer.png
ADDED

|
Git LFS Details
|
img/dofa.jpg
ADDED

|
img/fig_optimizer.png
ADDED

|
Git LFS Details
|
img/fig_tuned_nanogpt.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun51.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun52.png
ADDED
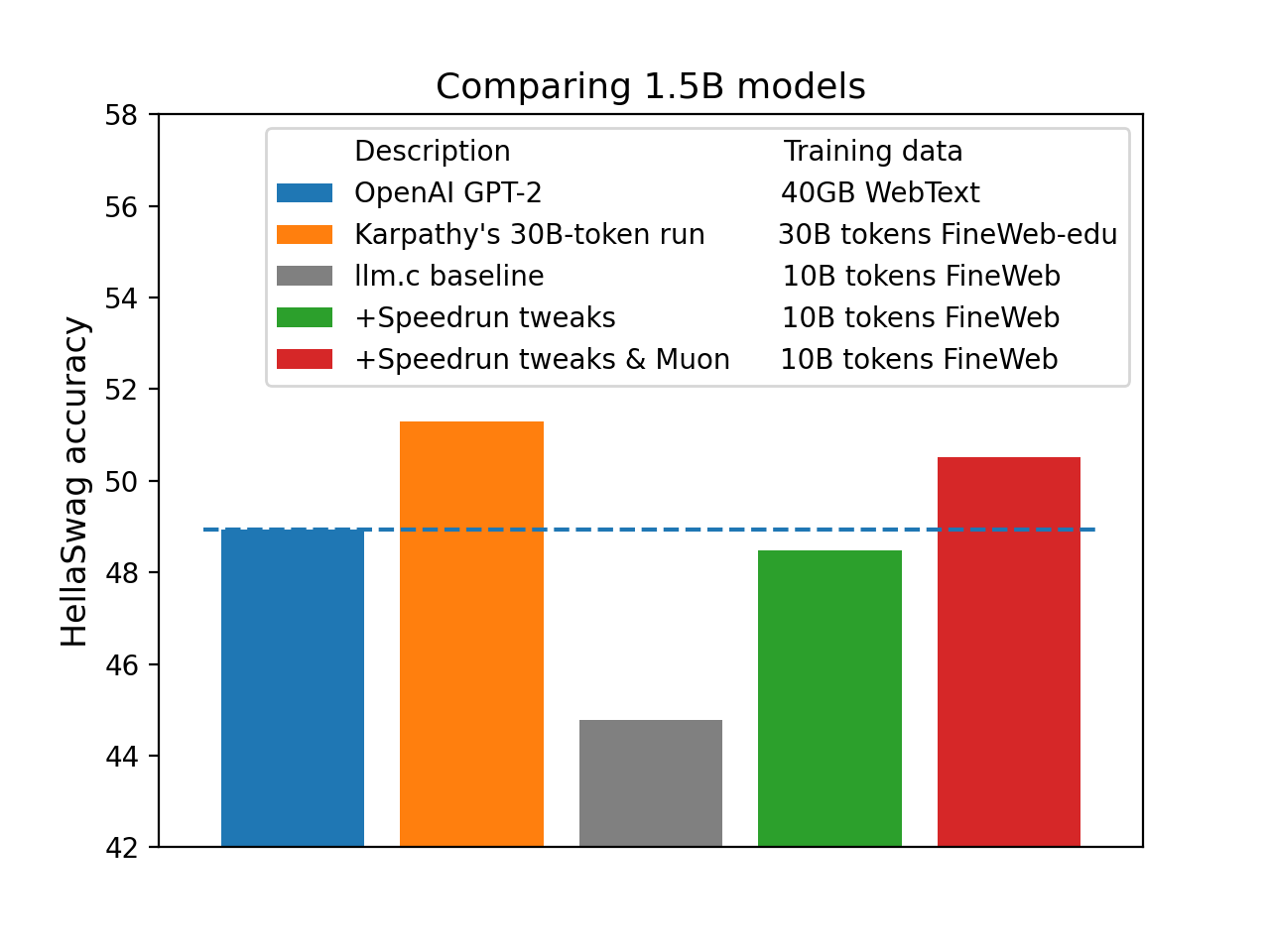
|
img/nanogpt_speedrun53.png
ADDED

|
Git LFS Details
|
img/nanogpt_speedrun54.png
ADDED
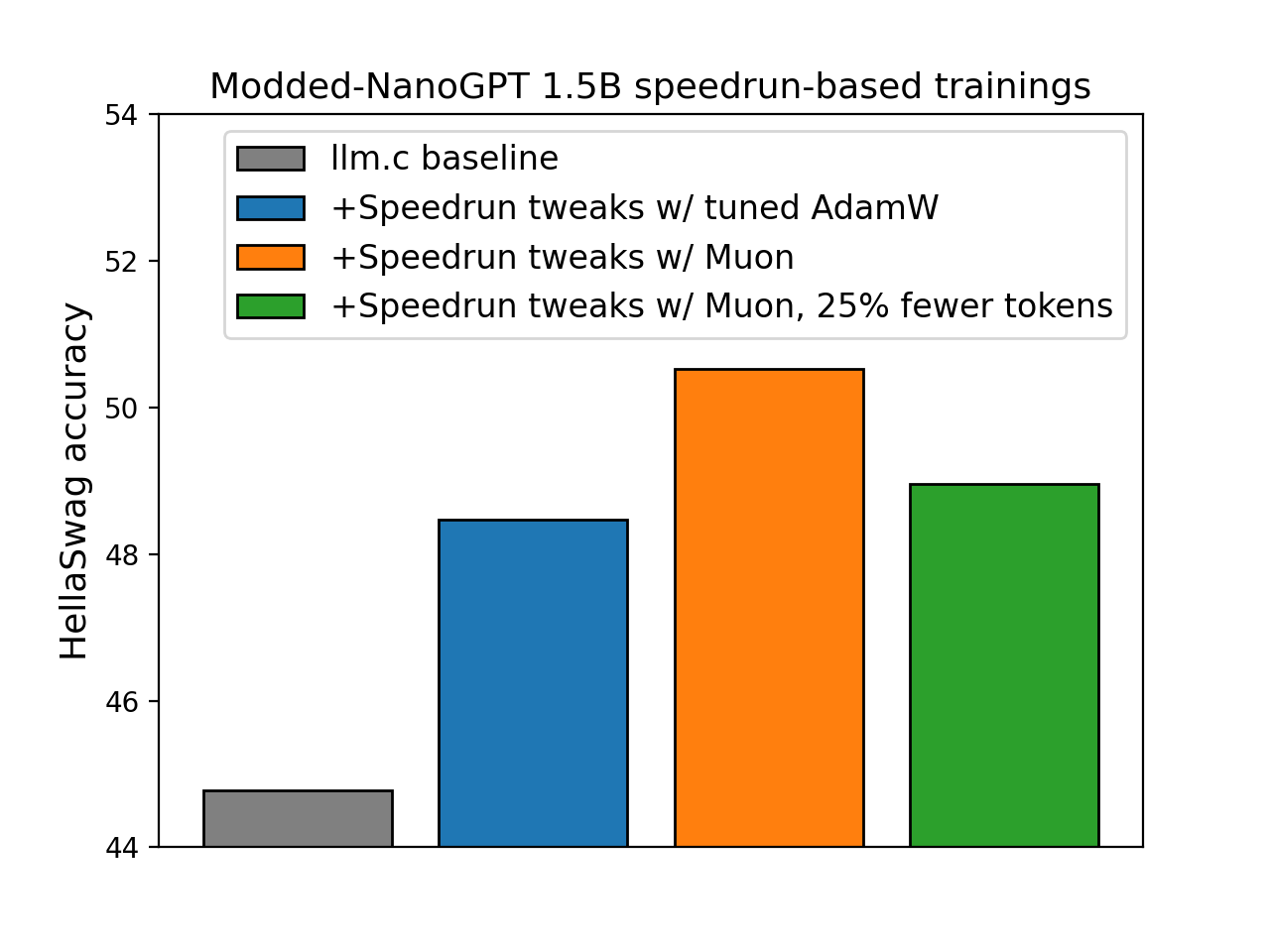
|
records/track_1_short/2024-06-06_AdamW/README.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This is the log for my baseline AdamW training to which I compared the new Muon and SOAP optimizers.
|
| 2 |
+
|
| 3 |
+
just the log, which is in the old llm.c format ("tel" lines are val loss)
|
| 4 |
+
|
| 5 |
+
this was batch size 2^19, so ~5B tokens
|
| 6 |
+
|
| 7 |
+
was learning rate 0.0018, warmup=250, warmdown=2000, betas=(0.9, 0.95) IIRC
|
| 8 |
+
|
records/track_1_short/2024-06-06_AdamW/f66d43d7-e449-4029-8adf-e8537bab49ea.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-09_SOAP/5bdc3988-496c-4232-b4ef-53764cb81c92.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-09_SOAP/README.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SOAP record October 9 2024
|
| 2 |
+
|
| 3 |
+
* New sample efficiency record: <3.28 validation loss in 3.15B tokens
|
| 4 |
+
* Uses SOAP optimizer ([Vyas et al. 2024](https://arxiv.org/abs/2409.11321))
|
| 5 |
+
* 363ms/step - not a new wallclock record (SOAP is in active development to reduce the wallclock overhead for distributed training, so this may change)
|
| 6 |
+
* Set by Nikhil Vyas @vyasnikhil96. Hyperparameters also tuned slightly by me
|
| 7 |
+
* [https://x.com/vyasnikhil96/status/1842656792217858063](https://x.com/vyasnikhil96/status/1842656792217858063)
|
| 8 |
+
* [https://github.com/nikhilvyas/modded-nanogpt-SOAP/tree/master](https://github.com/nikhilvyas/modded-nanogpt-SOAP/tree/master)
|
| 9 |
+
|
records/track_1_short/2024-10-09_SOAP/train_gpt2.py
ADDED
|
@@ -0,0 +1,857 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.optim as optim
|
| 4 |
+
|
| 5 |
+
from itertools import chain
|
| 6 |
+
|
| 7 |
+
# Parts of the code are modifications of Pytorch's AdamW optimizer
|
| 8 |
+
# Parts of the code are modifications of code from https://github.com/jiaweizzhao/GaLore/blob/master/galore_torch/galore_projector.py
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class SOAP(optim.Optimizer):
|
| 12 |
+
"""
|
| 13 |
+
Implements SOAP algorithm (https://arxiv.org/abs/2409.11321).
|
| 14 |
+
|
| 15 |
+
Parameters:
|
| 16 |
+
params (`Iterable[nn.parameter.Parameter]`):
|
| 17 |
+
Iterable of parameters to optimize or dictionaries defining parameter groups.
|
| 18 |
+
lr (`float`, *optional*, defaults to 0.003):
|
| 19 |
+
The learning rate to use.
|
| 20 |
+
betas (`Tuple[float,float]`, *optional*, defaults to `(0.95, 0.95)`):
|
| 21 |
+
Adam's betas parameters (b1, b2).
|
| 22 |
+
shampoo_beta (`float`, *optional*, defaults to -1):
|
| 23 |
+
If >= 0, use this beta for the preconditioner (L and R in paper, state['GG'] below) moving average instead of betas[1].
|
| 24 |
+
eps (`float`, *optional*, defaults to 1e-08):
|
| 25 |
+
Adam's epsilon for numerical stability.
|
| 26 |
+
weight_decay (`float`, *optional*, defaults to 0.01): weight decay coefficient.
|
| 27 |
+
precondition_frequency (`int`, *optional*, defaults to 10):
|
| 28 |
+
How often to update the preconditioner.
|
| 29 |
+
max_precond_dim (`int`, *optional*, defaults to 10000):
|
| 30 |
+
Maximum dimension of the preconditioner.
|
| 31 |
+
Set to 10000, so that we exclude most common vocab sizes while including layers.
|
| 32 |
+
merge_dims (`bool`, *optional*, defaults to `False`):
|
| 33 |
+
Whether or not to merge dimensions of the preconditioner.
|
| 34 |
+
precondition_1d (`bool`, *optional*, defaults to `False`):
|
| 35 |
+
Whether or not to precondition 1D gradients.
|
| 36 |
+
normalize_grads (`bool`, *optional*, defaults to `False`):
|
| 37 |
+
Whether or not to normalize gradients per layer.
|
| 38 |
+
Helps at large precondition_frequency (~100 in our experiments),
|
| 39 |
+
but hurts performance at small precondition_frequency (~10 in our experiments).
|
| 40 |
+
data_format (`str`, *optional*, defaults to `channels_first`):
|
| 41 |
+
Data format of the input for convolutional layers.
|
| 42 |
+
Should be "channels_last" for data_format of NHWC and "channels_first" for NCHW.
|
| 43 |
+
correct_bias (`bool`, *optional*, defaults to `True`):
|
| 44 |
+
Whether or not to use bias correction in Adam.
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
def __init__(
|
| 48 |
+
self,
|
| 49 |
+
params,
|
| 50 |
+
lr: float = 3e-3,
|
| 51 |
+
betas=(0.95, 0.95),
|
| 52 |
+
shampoo_beta: float= -1,
|
| 53 |
+
eps: float = 1e-8,
|
| 54 |
+
weight_decay: float = 0.01,
|
| 55 |
+
precondition_frequency: int=10,
|
| 56 |
+
max_precond_dim: int=10000, #
|
| 57 |
+
merge_dims: bool = False, # Merge dimensions till the product of the dimensions is less than or equal to max_precond_dim.
|
| 58 |
+
precondition_1d: bool = False,
|
| 59 |
+
normalize_grads: bool = False,
|
| 60 |
+
data_format: str = "channels_first",
|
| 61 |
+
correct_bias: bool = True,
|
| 62 |
+
):
|
| 63 |
+
defaults = {
|
| 64 |
+
"lr": lr,
|
| 65 |
+
"betas": betas,
|
| 66 |
+
"shampoo_beta": shampoo_beta,
|
| 67 |
+
"eps": eps,
|
| 68 |
+
"weight_decay": weight_decay,
|
| 69 |
+
"precondition_frequency": precondition_frequency,
|
| 70 |
+
"max_precond_dim": max_precond_dim,
|
| 71 |
+
"merge_dims": merge_dims,
|
| 72 |
+
"precondition_1d": precondition_1d,
|
| 73 |
+
"normalize_grads": normalize_grads,
|
| 74 |
+
"correct_bias": correct_bias,
|
| 75 |
+
}
|
| 76 |
+
super().__init__(params, defaults)
|
| 77 |
+
self._data_format = data_format
|
| 78 |
+
|
| 79 |
+
def merge_dims(self, grad, max_precond_dim):
|
| 80 |
+
"""
|
| 81 |
+
Merges dimensions of the gradient tensor till the product of the dimensions is less than or equal to max_precond_dim.
|
| 82 |
+
"""
|
| 83 |
+
assert self._data_format in ["channels_first", "channels_last"]
|
| 84 |
+
if self._data_format == "channels_last" and grad.dim() == 4:
|
| 85 |
+
grad = grad.permute(0, 3, 1, 2)
|
| 86 |
+
shape = grad.shape
|
| 87 |
+
new_shape = []
|
| 88 |
+
|
| 89 |
+
curr_shape = 1
|
| 90 |
+
for sh in shape:
|
| 91 |
+
temp_shape = curr_shape * sh
|
| 92 |
+
if temp_shape > max_precond_dim:
|
| 93 |
+
if curr_shape > 1:
|
| 94 |
+
new_shape.append(curr_shape)
|
| 95 |
+
curr_shape = sh
|
| 96 |
+
else:
|
| 97 |
+
new_shape.append(sh)
|
| 98 |
+
curr_shape = 1
|
| 99 |
+
else:
|
| 100 |
+
curr_shape = temp_shape
|
| 101 |
+
|
| 102 |
+
if curr_shape > 1 or len(new_shape)==0:
|
| 103 |
+
new_shape.append(curr_shape)
|
| 104 |
+
|
| 105 |
+
new_grad = grad.reshape(new_shape)
|
| 106 |
+
return new_grad
|
| 107 |
+
|
| 108 |
+
@torch.no_grad()
|
| 109 |
+
def step(self):
|
| 110 |
+
"""
|
| 111 |
+
Performs a single optimization step.
|
| 112 |
+
|
| 113 |
+
Arguments:
|
| 114 |
+
closure (`Callable`, *optional*): A closure that reevaluates the model and returns the loss.
|
| 115 |
+
"""
|
| 116 |
+
loss = None
|
| 117 |
+
|
| 118 |
+
for group in self.param_groups:
|
| 119 |
+
for p in group["params"]:
|
| 120 |
+
if p.grad is None:
|
| 121 |
+
continue
|
| 122 |
+
grad = p.grad
|
| 123 |
+
|
| 124 |
+
state = self.state[p]
|
| 125 |
+
|
| 126 |
+
if "step" not in state:
|
| 127 |
+
state["step"] = 0
|
| 128 |
+
|
| 129 |
+
# State initialization
|
| 130 |
+
if "exp_avg" not in state:
|
| 131 |
+
# Exponential moving average of gradient values
|
| 132 |
+
state["exp_avg"] = torch.zeros_like(grad)
|
| 133 |
+
# Exponential moving average of squared gradient values
|
| 134 |
+
state["exp_avg_sq"] = torch.zeros_like(grad)
|
| 135 |
+
|
| 136 |
+
if 'Q' not in state:
|
| 137 |
+
self.init_preconditioner(
|
| 138 |
+
grad,
|
| 139 |
+
state,
|
| 140 |
+
precondition_frequency=group['precondition_frequency'],
|
| 141 |
+
precondition_1d=group['precondition_1d'],
|
| 142 |
+
shampoo_beta=(group['shampoo_beta'] if group['shampoo_beta'] >= 0 else group["betas"][1]),
|
| 143 |
+
max_precond_dim=group['max_precond_dim'],
|
| 144 |
+
merge_dims=group["merge_dims"],
|
| 145 |
+
)
|
| 146 |
+
self.update_preconditioner(grad, state,
|
| 147 |
+
max_precond_dim=group['max_precond_dim'],
|
| 148 |
+
merge_dims=group["merge_dims"],
|
| 149 |
+
precondition_1d=group["precondition_1d"])
|
| 150 |
+
continue # first step is skipped so that we never use the current gradients in the projection.
|
| 151 |
+
|
| 152 |
+
# Projecting gradients to the eigenbases of Shampoo's preconditioner
|
| 153 |
+
# i.e. projecting to the eigenbases of matrices in state['GG']
|
| 154 |
+
grad_projected = self.project(grad, state, merge_dims=group["merge_dims"],
|
| 155 |
+
max_precond_dim=group['max_precond_dim'])
|
| 156 |
+
|
| 157 |
+
exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
|
| 158 |
+
beta1, beta2 = group["betas"]
|
| 159 |
+
|
| 160 |
+
state["step"] += 1
|
| 161 |
+
|
| 162 |
+
# Decay the first and second moment running average coefficient
|
| 163 |
+
# In-place operations to update the averages at the same time
|
| 164 |
+
exp_avg.mul_(beta1).add_(grad, alpha=(1.0 - beta1))
|
| 165 |
+
exp_avg_sq.mul_(beta2).add_(grad_projected.square(), alpha=(1.0 - beta2))
|
| 166 |
+
|
| 167 |
+
denom = exp_avg_sq.sqrt().add_(group["eps"])
|
| 168 |
+
|
| 169 |
+
# Projecting the exponential moving average of gradients to the eigenbases of Shampoo's preconditioner
|
| 170 |
+
# i.e. projecting to the eigenbases of matrices in state['GG']
|
| 171 |
+
exp_avg_projected = self.project(exp_avg, state, merge_dims=group["merge_dims"],
|
| 172 |
+
max_precond_dim=group['max_precond_dim'])
|
| 173 |
+
|
| 174 |
+
step_size = group["lr"]
|
| 175 |
+
if group["correct_bias"]:
|
| 176 |
+
bias_correction1 = 1.0 - beta1 ** (state["step"])
|
| 177 |
+
bias_correction2 = 1.0 - beta2 ** (state["step"])
|
| 178 |
+
step_size = step_size * (bias_correction2 ** .5) / bias_correction1
|
| 179 |
+
|
| 180 |
+
# Projecting back the preconditioned (by Adam) exponential moving average of gradients
|
| 181 |
+
# to the original space
|
| 182 |
+
norm_grad = self.project_back(exp_avg_projected / denom, state, merge_dims=group["merge_dims"],
|
| 183 |
+
max_precond_dim=group['max_precond_dim'])
|
| 184 |
+
|
| 185 |
+
if group["normalize_grads"]:
|
| 186 |
+
norm_grad = norm_grad / (1e-30+torch.mean(norm_grad**2)**0.5)
|
| 187 |
+
|
| 188 |
+
p.add_(norm_grad, alpha=-step_size)
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
# From AdamW code: Just adding the square of the weights to the loss function is *not*
|
| 192 |
+
# the correct way of using L2 regularization/weight decay with Adam,
|
| 193 |
+
# since that will interact with the m and v parameters in strange ways.
|
| 194 |
+
#
|
| 195 |
+
# Instead we want to decay the weights in a manner that doesn't interact
|
| 196 |
+
# with the m/v parameters. This is equivalent to adding the square
|
| 197 |
+
# of the weights to the loss with plain (non-momentum) SGD.
|
| 198 |
+
# Add weight decay at the end (fixed version)
|
| 199 |
+
if group["weight_decay"] > 0.0:
|
| 200 |
+
p.add_(p, alpha=(-group["lr"] * group["weight_decay"]))
|
| 201 |
+
|
| 202 |
+
# Update is done after the gradient step to avoid using current gradients in the projection.
|
| 203 |
+
self.update_preconditioner(grad, state,
|
| 204 |
+
max_precond_dim=group['max_precond_dim'],
|
| 205 |
+
merge_dims=group["merge_dims"],
|
| 206 |
+
precondition_1d=group["precondition_1d"])
|
| 207 |
+
|
| 208 |
+
return loss
|
| 209 |
+
|
| 210 |
+
def init_preconditioner(self, grad, state, precondition_frequency=10,
|
| 211 |
+
shampoo_beta=0.95, max_precond_dim=10000, precondition_1d=False,
|
| 212 |
+
merge_dims=False):
|
| 213 |
+
"""
|
| 214 |
+
Initializes the preconditioner matrices (L and R in the paper).
|
| 215 |
+
"""
|
| 216 |
+
state['GG'] = [] # Will hold all the preconditioner matrices (L and R in the paper).
|
| 217 |
+
if grad.dim() == 1:
|
| 218 |
+
if not precondition_1d or grad.shape[0] > max_precond_dim:
|
| 219 |
+
state['GG'].append([])
|
| 220 |
+
else:
|
| 221 |
+
state['GG'].append(torch.zeros(grad.shape[0], grad.shape[0], device=grad.device))
|
| 222 |
+
else:
|
| 223 |
+
if merge_dims:
|
| 224 |
+
grad = self.merge_dims(grad, max_precond_dim)
|
| 225 |
+
|
| 226 |
+
for sh in grad.shape:
|
| 227 |
+
if sh > max_precond_dim:
|
| 228 |
+
state['GG'].append([])
|
| 229 |
+
else:
|
| 230 |
+
state['GG'].append(torch.zeros(sh, sh, device=grad.device))
|
| 231 |
+
|
| 232 |
+
state['Q'] = None # Will hold all the eigenbases of the preconditioner.
|
| 233 |
+
state['precondition_frequency'] = precondition_frequency
|
| 234 |
+
state['shampoo_beta'] = shampoo_beta
|
| 235 |
+
|
| 236 |
+
def project(self, grad, state, merge_dims=False, max_precond_dim=10000):
|
| 237 |
+
"""
|
| 238 |
+
Projects the gradient to the eigenbases of the preconditioner.
|
| 239 |
+
"""
|
| 240 |
+
original_shape = grad.shape
|
| 241 |
+
if merge_dims:
|
| 242 |
+
if grad.dim() == 4 and self._data_format == 'channels_last':
|
| 243 |
+
permuted_shape = grad.permute(0, 3, 1, 2).shape
|
| 244 |
+
grad = self.merge_dims(grad, max_precond_dim)
|
| 245 |
+
|
| 246 |
+
for mat in state['Q']:
|
| 247 |
+
if len(mat) > 0:
|
| 248 |
+
grad = torch.tensordot(
|
| 249 |
+
grad,
|
| 250 |
+
mat,
|
| 251 |
+
dims=[[0], [0]],
|
| 252 |
+
)
|
| 253 |
+
else:
|
| 254 |
+
permute_order = list(range(1, len(grad.shape))) + [0]
|
| 255 |
+
grad = grad.permute(permute_order)
|
| 256 |
+
|
| 257 |
+
if merge_dims:
|
| 258 |
+
if self._data_format == 'channels_last' and len(original_shape) == 4:
|
| 259 |
+
grad = grad.reshape(permuted_shape).permute(0, 2, 3, 1)
|
| 260 |
+
else:
|
| 261 |
+
grad = grad.reshape(original_shape)
|
| 262 |
+
return grad
|
| 263 |
+
|
| 264 |
+
def update_preconditioner(self, grad, state,
|
| 265 |
+
max_precond_dim=10000, merge_dims=False, precondition_1d=False):
|
| 266 |
+
"""
|
| 267 |
+
Updates the preconditioner matrices and the eigenbases (L, R, Q_L, Q_R in the paper).
|
| 268 |
+
"""
|
| 269 |
+
if grad.dim() == 1:
|
| 270 |
+
if precondition_1d and grad.shape[0] <= max_precond_dim:
|
| 271 |
+
state['GG'][0].lerp_(grad.unsqueeze(1) @ grad.unsqueeze(0), 1-state['shampoo_beta'])
|
| 272 |
+
else:
|
| 273 |
+
if merge_dims:
|
| 274 |
+
new_grad = self.merge_dims(grad, max_precond_dim)
|
| 275 |
+
for idx, sh in enumerate(new_grad.shape):
|
| 276 |
+
if sh <= max_precond_dim:
|
| 277 |
+
outer_product = torch.tensordot(
|
| 278 |
+
new_grad,
|
| 279 |
+
new_grad,
|
| 280 |
+
dims=[[*chain(range(idx), range(idx + 1, len(new_grad.shape)))]] * 2,
|
| 281 |
+
)
|
| 282 |
+
state['GG'][idx].lerp_(outer_product, 1-state['shampoo_beta'])
|
| 283 |
+
else:
|
| 284 |
+
for idx, sh in enumerate(grad.shape):
|
| 285 |
+
if sh <= max_precond_dim:
|
| 286 |
+
outer_product = torch.tensordot(
|
| 287 |
+
grad,
|
| 288 |
+
grad,
|
| 289 |
+
# Contracts across all dimensions except for k.
|
| 290 |
+
dims=[[*chain(range(idx), range(idx + 1, len(grad.shape)))]] * 2,
|
| 291 |
+
)
|
| 292 |
+
state['GG'][idx].lerp_(outer_product, 1-state['shampoo_beta'])
|
| 293 |
+
|
| 294 |
+
if state['Q'] is None:
|
| 295 |
+
state['Q'] = self.get_orthogonal_matrix(state['GG'])
|
| 296 |
+
if state['step'] > 0 and state['step'] % state['precondition_frequency'] == 0:
|
| 297 |
+
state['Q'] = self.get_orthogonal_matrix_QR(state, max_precond_dim, merge_dims)
|
| 298 |
+
|
| 299 |
+
def project_back(self, grad, state, merge_dims=False, max_precond_dim=10000):
|
| 300 |
+
"""
|
| 301 |
+
Projects the gradient back to the original space.
|
| 302 |
+
"""
|
| 303 |
+
original_shape = grad.shape
|
| 304 |
+
if merge_dims:
|
| 305 |
+
if self._data_format == 'channels_last' and grad.dim() == 4:
|
| 306 |
+
permuted_shape = grad.permute(0, 3, 1, 2).shape
|
| 307 |
+
grad = self.merge_dims(grad, max_precond_dim)
|
| 308 |
+
for mat in state['Q']:
|
| 309 |
+
if len(mat) > 0:
|
| 310 |
+
grad = torch.tensordot(
|
| 311 |
+
grad,
|
| 312 |
+
mat,
|
| 313 |
+
dims=[[0], [1]],
|
| 314 |
+
)
|
| 315 |
+
else:
|
| 316 |
+
permute_order = list(range(1, len(grad.shape))) + [0]
|
| 317 |
+
grad = grad.permute(permute_order)
|
| 318 |
+
|
| 319 |
+
if merge_dims:
|
| 320 |
+
if self._data_format == 'channels_last' and len(original_shape) == 4:
|
| 321 |
+
grad = grad.reshape(permuted_shape).permute(0, 2, 3, 1)
|
| 322 |
+
else:
|
| 323 |
+
grad = grad.reshape(original_shape)
|
| 324 |
+
return grad
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def get_orthogonal_matrix(self, mat):
|
| 328 |
+
"""
|
| 329 |
+
Computes the eigenbases of the preconditioner using torch.linalg.eigh decomposition.
|
| 330 |
+
"""
|
| 331 |
+
matrix = []
|
| 332 |
+
for m in mat:
|
| 333 |
+
if len(m) == 0:
|
| 334 |
+
matrix.append([])
|
| 335 |
+
continue
|
| 336 |
+
if m.data.dtype != torch.float:
|
| 337 |
+
float_data = False
|
| 338 |
+
original_type = m.data.dtype
|
| 339 |
+
original_device = m.data.device
|
| 340 |
+
matrix.append(m.data.float())
|
| 341 |
+
else:
|
| 342 |
+
float_data = True
|
| 343 |
+
matrix.append(m.data)
|
| 344 |
+
|
| 345 |
+
final = []
|
| 346 |
+
for m in matrix:
|
| 347 |
+
if len(m) == 0:
|
| 348 |
+
final.append([])
|
| 349 |
+
continue
|
| 350 |
+
try:
|
| 351 |
+
_, Q = torch.linalg.eigh(m+1e-30*torch.eye(m.shape[0], device=m.device))
|
| 352 |
+
except:
|
| 353 |
+
_, Q = torch.linalg.eigh(m.to(torch.float64)+1e-30*torch.eye(m.shape[0], device=m.device))
|
| 354 |
+
Q = Q.to(m.dtype)
|
| 355 |
+
Q = torch.flip(Q, [1])
|
| 356 |
+
|
| 357 |
+
if not float_data:
|
| 358 |
+
Q = Q.to(original_device).type(original_type)
|
| 359 |
+
final.append(Q)
|
| 360 |
+
return final
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
def get_orthogonal_matrix_QR(self, state, max_precond_dim=10000, merge_dims=False):
|
| 364 |
+
"""
|
| 365 |
+
Computes the eigenbases of the preconditioner using one round of power iteration
|
| 366 |
+
followed by torch.linalg.qr decomposition.
|
| 367 |
+
"""
|
| 368 |
+
precond_list = state['GG']
|
| 369 |
+
orth_list = state['Q']
|
| 370 |
+
|
| 371 |
+
matrix = []
|
| 372 |
+
orth_matrix = []
|
| 373 |
+
for m,o in zip(precond_list, orth_list):
|
| 374 |
+
if len(m) == 0:
|
| 375 |
+
matrix.append([])
|
| 376 |
+
orth_matrix.append([])
|
| 377 |
+
continue
|
| 378 |
+
if m.data.dtype != torch.float:
|
| 379 |
+
float_data = False
|
| 380 |
+
original_type = m.data.dtype
|
| 381 |
+
original_device = m.data.device
|
| 382 |
+
matrix.append(m.data.float())
|
| 383 |
+
orth_matrix.append(o.data.float())
|
| 384 |
+
else:
|
| 385 |
+
float_data = True
|
| 386 |
+
matrix.append(m.data.float())
|
| 387 |
+
orth_matrix.append(o.data.float())
|
| 388 |
+
|
| 389 |
+
orig_shape = state['exp_avg_sq'].shape
|
| 390 |
+
if self._data_format == 'channels_last' and len(orig_shape) == 4:
|
| 391 |
+
permuted_shape = state['exp_avg_sq'].permute(0, 3, 1, 2).shape
|
| 392 |
+
if merge_dims:
|
| 393 |
+
exp_avg_sq = self.merge_dims(state['exp_avg_sq'], max_precond_dim)
|
| 394 |
+
else:
|
| 395 |
+
exp_avg_sq = state['exp_avg_sq']
|
| 396 |
+
|
| 397 |
+
final = []
|
| 398 |
+
for ind, (m,o) in enumerate(zip(matrix, orth_matrix)):
|
| 399 |
+
if len(m)==0:
|
| 400 |
+
final.append([])
|
| 401 |
+
continue
|
| 402 |
+
est_eig = torch.diag(o.T @ m @ o)
|
| 403 |
+
sort_idx = torch.argsort(est_eig, descending=True)
|
| 404 |
+
exp_avg_sq = exp_avg_sq.index_select(ind, sort_idx)
|
| 405 |
+
o = o[:,sort_idx]
|
| 406 |
+
power_iter = m @ o
|
| 407 |
+
Q, _ = torch.linalg.qr(power_iter)
|
| 408 |
+
|
| 409 |
+
if not float_data:
|
| 410 |
+
Q = Q.to(original_device).type(original_type)
|
| 411 |
+
final.append(Q)
|
| 412 |
+
|
| 413 |
+
if merge_dims:
|
| 414 |
+
if self._data_format == 'channels_last' and len(orig_shape) == 4:
|
| 415 |
+
exp_avg_sq = exp_avg_sq.reshape(permuted_shape).permute(0, 2, 3, 1)
|
| 416 |
+
else:
|
| 417 |
+
exp_avg_sq = exp_avg_sq.reshape(orig_shape)
|
| 418 |
+
|
| 419 |
+
state['exp_avg_sq'] = exp_avg_sq
|
| 420 |
+
return final
|
| 421 |
+
|
| 422 |
+
import os
|
| 423 |
+
import sys
|
| 424 |
+
with open(sys.argv[0]) as f:
|
| 425 |
+
code = f.read() # read the code of this file ASAP, for logging
|
| 426 |
+
import uuid
|
| 427 |
+
import glob
|
| 428 |
+
import time
|
| 429 |
+
from dataclasses import dataclass
|
| 430 |
+
|
| 431 |
+
import numpy as np
|
| 432 |
+
import torch
|
| 433 |
+
from torch import nn
|
| 434 |
+
import torch.nn.functional as F
|
| 435 |
+
import torch.distributed as dist
|
| 436 |
+
import torch._inductor.config as config
|
| 437 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 438 |
+
|
| 439 |
+
# -----------------------------------------------------------------------------
|
| 440 |
+
# PyTorch nn.Module definitions for the GPT-2 model
|
| 441 |
+
|
| 442 |
+
class Rotary(torch.nn.Module):
|
| 443 |
+
|
| 444 |
+
def __init__(self, dim, base=10000):
|
| 445 |
+
super().__init__()
|
| 446 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 447 |
+
self.register_buffer("inv_freq", inv_freq)
|
| 448 |
+
self.seq_len_cached = None
|
| 449 |
+
self.cos_cached = None
|
| 450 |
+
self.sin_cached = None
|
| 451 |
+
|
| 452 |
+
def forward(self, x):
|
| 453 |
+
seq_len = x.shape[1]
|
| 454 |
+
if seq_len != self.seq_len_cached:
|
| 455 |
+
self.seq_len_cached = seq_len
|
| 456 |
+
t = torch.arange(seq_len, device=x.device).type_as(self.inv_freq)
|
| 457 |
+
freqs = torch.outer(t, self.inv_freq).to(x.device)
|
| 458 |
+
self.cos_cached = freqs.cos()
|
| 459 |
+
self.sin_cached = freqs.sin()
|
| 460 |
+
return self.cos_cached[None, :, None, :], self.sin_cached[None, :, None, :]
|
| 461 |
+
|
| 462 |
+
def apply_rotary_emb(x, cos, sin):
|
| 463 |
+
assert x.ndim == 4 # multihead attention
|
| 464 |
+
d = x.shape[3]//2
|
| 465 |
+
x1 = x[..., :d]
|
| 466 |
+
x2 = x[..., d:]
|
| 467 |
+
y1 = x1 * cos + x2 * sin
|
| 468 |
+
y2 = x1 * (-sin) + x2 * cos
|
| 469 |
+
return torch.cat([y1, y2], 3)
|
| 470 |
+
|
| 471 |
+
def rmsnorm(x0, eps=1e-6):
|
| 472 |
+
x = x0.float()
|
| 473 |
+
x = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
|
| 474 |
+
return x.type_as(x0)
|
| 475 |
+
|
| 476 |
+
class CausalSelfAttention(nn.Module):
|
| 477 |
+
|
| 478 |
+
def __init__(self, config):
|
| 479 |
+
super().__init__()
|
| 480 |
+
self.n_head = config.n_head
|
| 481 |
+
self.n_embd = config.n_embd
|
| 482 |
+
self.head_dim = self.n_embd // self.n_head
|
| 483 |
+
assert self.n_embd % self.n_head == 0
|
| 484 |
+
self.c_q = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 485 |
+
self.c_k = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 486 |
+
self.c_v = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 487 |
+
# output projection
|
| 488 |
+
self.c_proj = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 489 |
+
self.rotary = Rotary(self.head_dim)
|
| 490 |
+
|
| 491 |
+
def forward(self, x):
|
| 492 |
+
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
|
| 493 |
+
q, k, v = self.c_q(x), self.c_k(x), self.c_v(x)
|
| 494 |
+
k = k.view(B, T, self.n_head, self.head_dim)
|
| 495 |
+
q = q.view(B, T, self.n_head, self.head_dim)
|
| 496 |
+
v = v.view(B, T, self.n_head, self.head_dim)
|
| 497 |
+
cos, sin = self.rotary(q)
|
| 498 |
+
q = apply_rotary_emb(q, cos, sin)
|
| 499 |
+
k = apply_rotary_emb(k, cos, sin)
|
| 500 |
+
y = F.scaled_dot_product_attention(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2), is_causal=True)
|
| 501 |
+
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
|
| 502 |
+
# output projection
|
| 503 |
+
y = self.c_proj(y)
|
| 504 |
+
return y
|
| 505 |
+
|
| 506 |
+
class MLP(nn.Module):
|
| 507 |
+
|
| 508 |
+
def __init__(self, config):
|
| 509 |
+
super().__init__()
|
| 510 |
+
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=False)
|
| 511 |
+
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=False)
|
| 512 |
+
|
| 513 |
+
def forward(self, x):
|
| 514 |
+
x = self.c_fc(x)
|
| 515 |
+
x = F.gelu(x)
|
| 516 |
+
x = self.c_proj(x)
|
| 517 |
+
return x
|
| 518 |
+
|
| 519 |
+
class Block(nn.Module):
|
| 520 |
+
|
| 521 |
+
def __init__(self, config):
|
| 522 |
+
super().__init__()
|
| 523 |
+
self.attn = CausalSelfAttention(config)
|
| 524 |
+
self.mlp = MLP(config)
|
| 525 |
+
self.attn_scale = (1 / (2 * config.n_layer)**0.5)
|
| 526 |
+
|
| 527 |
+
def forward(self, x):
|
| 528 |
+
x = x + self.attn_scale * self.attn(rmsnorm(x))
|
| 529 |
+
x = x + self.mlp(rmsnorm(x))
|
| 530 |
+
return x
|
| 531 |
+
|
| 532 |
+
# -----------------------------------------------------------------------------
|
| 533 |
+
# The main GPT-2 model
|
| 534 |
+
|
| 535 |
+
@dataclass
|
| 536 |
+
class GPTConfig:
|
| 537 |
+
vocab_size : int = 50257
|
| 538 |
+
n_layer : int = 12
|
| 539 |
+
n_head : int = 12
|
| 540 |
+
n_embd : int = 768
|
| 541 |
+
|
| 542 |
+
class GPT(nn.Module):
|
| 543 |
+
|
| 544 |
+
def __init__(self, config):
|
| 545 |
+
super().__init__()
|
| 546 |
+
self.config = config
|
| 547 |
+
|
| 548 |
+
self.transformer = nn.ModuleDict(dict(
|
| 549 |
+
wte = nn.Embedding(config.vocab_size, config.n_embd),
|
| 550 |
+
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
|
| 551 |
+
))
|
| 552 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 553 |
+
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
|
| 554 |
+
|
| 555 |
+
def forward(self, idx, targets=None, return_logits=True):
|
| 556 |
+
b, t = idx.size()
|
| 557 |
+
pos = torch.arange(0, t, dtype=torch.long, device=idx.device) # shape (t)
|
| 558 |
+
|
| 559 |
+
# forward the GPT model itself
|
| 560 |
+
x = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
|
| 561 |
+
|
| 562 |
+
for block in self.transformer.h:
|
| 563 |
+
x = block(x)
|
| 564 |
+
x = rmsnorm(x)
|
| 565 |
+
|
| 566 |
+
if targets is not None:
|
| 567 |
+
# if we are given some desired targets also calculate the loss
|
| 568 |
+
logits = self.lm_head(x)
|
| 569 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 570 |
+
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
|
| 571 |
+
else:
|
| 572 |
+
# inference-time mini-optimization: only forward the lm_head on the very last position
|
| 573 |
+
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
|
| 574 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 575 |
+
loss = None
|
| 576 |
+
|
| 577 |
+
# there are performance reasons why not returning logits is prudent, if not needed
|
| 578 |
+
if not return_logits:
|
| 579 |
+
logits = None
|
| 580 |
+
|
| 581 |
+
return logits, loss
|
| 582 |
+
|
| 583 |
+
# -----------------------------------------------------------------------------
|
| 584 |
+
# Our own simple Distributed Data Loader
|
| 585 |
+
|
| 586 |
+
def _peek_data_shard(filename):
|
| 587 |
+
# only reads the header, returns header data
|
| 588 |
+
with open(filename, "rb") as f:
|
| 589 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 590 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 591 |
+
if header[0] != 20240520:
|
| 592 |
+
print("ERROR: magic number mismatch in the data .bin file!")
|
| 593 |
+
print("---> HINT: Are you passing in a correct file with --input_bin?")
|
| 594 |
+
print("---> HINT: Dataset encoding changed recently, re-run data prepro or refer again to README")
|
| 595 |
+
print("---> HINT: For example re-run: `python dev/data/tinyshakespeare.py`, then re-try")
|
| 596 |
+
exit(1)
|
| 597 |
+
assert header[1] == 1, "unsupported version"
|
| 598 |
+
ntok = header[2] # number of tokens (claimed)
|
| 599 |
+
return ntok # for now just return the number of tokens
|
| 600 |
+
|
| 601 |
+
def _load_data_shard(filename):
|
| 602 |
+
with open(filename, "rb") as f:
|
| 603 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 604 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 605 |
+
assert header[0] == 20240520, "magic number mismatch in the data .bin file"
|
| 606 |
+
assert header[1] == 1, "unsupported version"
|
| 607 |
+
ntok = header[2] # number of tokens (claimed)
|
| 608 |
+
# the rest of it are tokens, stored as uint16
|
| 609 |
+
tokens = np.frombuffer(f.read(), dtype=np.uint16)
|
| 610 |
+
assert len(tokens) == ntok, "number of tokens read does not match header?"
|
| 611 |
+
return tokens
|
| 612 |
+
|
| 613 |
+
class DistributedDataLoader:
|
| 614 |
+
def __init__(self, filename_pattern, B, T, process_rank, num_processes):
|
| 615 |
+
self.process_rank = process_rank
|
| 616 |
+
self.num_processes = num_processes
|
| 617 |
+
self.B = B
|
| 618 |
+
self.T = T
|
| 619 |
+
|
| 620 |
+
# glob files that match the pattern
|
| 621 |
+
self.files = sorted(glob.glob(filename_pattern))
|
| 622 |
+
assert len(self.files) > 0, f"did not find any files that match the pattern {filename_pattern}"
|
| 623 |
+
|
| 624 |
+
# load and validate all data shards, count number of tokens in total
|
| 625 |
+
ntok_total = 0
|
| 626 |
+
for fname in self.files:
|
| 627 |
+
shard_ntok = _peek_data_shard(fname)
|
| 628 |
+
assert shard_ntok >= num_processes * B * T + 1
|
| 629 |
+
ntok_total += int(shard_ntok)
|
| 630 |
+
self.ntok_total = ntok_total
|
| 631 |
+
|
| 632 |
+
# kick things off
|
| 633 |
+
self.reset()
|
| 634 |
+
|
| 635 |
+
def reset(self):
|
| 636 |
+
self.current_shard = 0
|
| 637 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 638 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 639 |
+
|
| 640 |
+
def advance(self): # advance to next data shard
|
| 641 |
+
self.current_shard = (self.current_shard + 1) % len(self.files)
|
| 642 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 643 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 644 |
+
|
| 645 |
+
def next_batch(self):
|
| 646 |
+
B = self.B
|
| 647 |
+
T = self.T
|
| 648 |
+
buf = self.tokens[self.current_position : self.current_position+B*T+1]
|
| 649 |
+
buf = torch.tensor(buf.astype(np.int32), dtype=torch.long)
|
| 650 |
+
x = (buf[:-1]).view(B, T) # inputs
|
| 651 |
+
y = (buf[1:]).view(B, T) # targets
|
| 652 |
+
# advance current position and load next shard if necessary
|
| 653 |
+
self.current_position += B * T * self.num_processes
|
| 654 |
+
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
|
| 655 |
+
self.advance()
|
| 656 |
+
return x.cuda(), y.cuda()
|
| 657 |
+
|
| 658 |
+
# -----------------------------------------------------------------------------
|
| 659 |
+
# int main
|
| 660 |
+
|
| 661 |
+
@dataclass
|
| 662 |
+
class Hyperparameters:
|
| 663 |
+
# data hyperparams
|
| 664 |
+
input_bin : str = 'data/fineweb10B/fineweb_train_*.bin' # input .bin to train on
|
| 665 |
+
input_val_bin : str = 'data/fineweb10B/fineweb_val_*.bin' # input .bin to eval validation loss on
|
| 666 |
+
# optimization hyperparams
|
| 667 |
+
batch_size : int = 8*64 # batch size, in sequences, across all devices
|
| 668 |
+
device_batch_size : int = 64 # batch size, in sequences, per device
|
| 669 |
+
sequence_length : int = 1024 # sequence length, in tokens
|
| 670 |
+
num_iterations : int = 6000 # number of iterations to run
|
| 671 |
+
learning_rate : float = 0.0036
|
| 672 |
+
warmup_iters : int = 250
|
| 673 |
+
warmdown_iters : int = 1800 # number of iterations of linear warmup/warmdown for triangular or trapezoidal schedule
|
| 674 |
+
# evaluation and logging hyperparams
|
| 675 |
+
val_loss_every : int = 125 # every how many steps to evaluate val loss? 0 for only at the end
|
| 676 |
+
val_tokens : int = 10485760 # how many tokens of validation data? it's important to keep this fixed for consistent comparisons
|
| 677 |
+
save_every : int = 0 # every how many steps to save the checkpoint? 0 for only at the end
|
| 678 |
+
args = Hyperparameters()
|
| 679 |
+
|
| 680 |
+
# set up DDP (distributed data parallel). torchrun sets this env variable
|
| 681 |
+
assert torch.cuda.is_available()
|
| 682 |
+
dist.init_process_group(backend='nccl')
|
| 683 |
+
ddp_rank = int(os.environ['RANK'])
|
| 684 |
+
ddp_local_rank = int(os.environ['LOCAL_RANK'])
|
| 685 |
+
ddp_world_size = int(os.environ['WORLD_SIZE'])
|
| 686 |
+
device = f'cuda:{ddp_local_rank}'
|
| 687 |
+
torch.cuda.set_device(device)
|
| 688 |
+
print(f"using device: {device}")
|
| 689 |
+
master_process = (ddp_rank == 0) # this process will do logging, checkpointing etc.
|
| 690 |
+
|
| 691 |
+
# convenience variables
|
| 692 |
+
B, T = args.device_batch_size, args.sequence_length
|
| 693 |
+
# calculate the number of steps to take in the val loop.
|
| 694 |
+
assert args.val_tokens % (B * T * ddp_world_size) == 0
|
| 695 |
+
val_steps = args.val_tokens // (B * T * ddp_world_size)
|
| 696 |
+
# calculate the steps of gradient accumulation required to attain the desired global batch size.
|
| 697 |
+
assert args.batch_size % (B * ddp_world_size) == 0
|
| 698 |
+
train_accumulation_steps = args.batch_size // (B * ddp_world_size)
|
| 699 |
+
|
| 700 |
+
# load tokens
|
| 701 |
+
train_loader = DistributedDataLoader(args.input_bin, B, T, ddp_rank, ddp_world_size)
|
| 702 |
+
val_loader = DistributedDataLoader(args.input_val_bin, B, T, ddp_rank, ddp_world_size)
|
| 703 |
+
if master_process:
|
| 704 |
+
print(f"Training DataLoader: total number of tokens: {train_loader.ntok_total} across {len(train_loader.files)} files")
|
| 705 |
+
print(f"Validation DataLoader: total number of tokens: {val_loader.ntok_total} across {len(val_loader.files)} files")
|
| 706 |
+
x, y = train_loader.next_batch()
|
| 707 |
+
|
| 708 |
+
# init the model from scratch
|
| 709 |
+
num_vocab = 50257
|
| 710 |
+
model = GPT(GPTConfig(vocab_size=num_vocab, n_layer=12, n_head=12, n_embd=768))
|
| 711 |
+
model = model.cuda()
|
| 712 |
+
if hasattr(config, "coordinate_descent_tuning"):
|
| 713 |
+
config.coordinate_descent_tuning = True # suggested by @Chillee
|
| 714 |
+
model = torch.compile(model)
|
| 715 |
+
# here we wrap model into DDP container
|
| 716 |
+
model = DDP(model, device_ids=[ddp_local_rank])
|
| 717 |
+
raw_model = model.module # always contains the "raw" unwrapped model
|
| 718 |
+
ctx = torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16)
|
| 719 |
+
|
| 720 |
+
# init the optimizer(s)
|
| 721 |
+
optimizer1 = torch.optim.AdamW(raw_model.lm_head.parameters(), lr=args.learning_rate, betas=(0.9, 0.95),
|
| 722 |
+
weight_decay=0, fused=True)
|
| 723 |
+
optimizer2 = SOAP(raw_model.transformer.h.parameters(), lr=0.5*args.learning_rate, betas=(.95, .95), weight_decay=0, precondition_frequency=10)
|
| 724 |
+
optimizers = [optimizer1, optimizer2]
|
| 725 |
+
# learning rate decay scheduler (linear warmup and warmdown)
|
| 726 |
+
def get_lr(it):
|
| 727 |
+
assert it <= args.num_iterations
|
| 728 |
+
# 1) linear warmup for warmup_iters steps
|
| 729 |
+
if it < args.warmup_iters:
|
| 730 |
+
return (it+1) / args.warmup_iters
|
| 731 |
+
# 2) constant lr for a while
|
| 732 |
+
elif it < args.num_iterations - args.warmdown_iters:
|
| 733 |
+
return 1.0
|
| 734 |
+
# 3) linear warmdown
|
| 735 |
+
else:
|
| 736 |
+
decay_ratio = (args.num_iterations - it) / args.warmdown_iters
|
| 737 |
+
return decay_ratio
|
| 738 |
+
schedulers = [torch.optim.lr_scheduler.LambdaLR(opt, get_lr) for opt in optimizers]
|
| 739 |
+
|
| 740 |
+
# begin logging
|
| 741 |
+
if master_process:
|
| 742 |
+
run_id = str(uuid.uuid4())
|
| 743 |
+
logdir = 'logs/%s/' % run_id
|
| 744 |
+
os.makedirs(logdir, exist_ok=True)
|
| 745 |
+
logfile = 'logs/%s.txt' % run_id
|
| 746 |
+
# create the log file
|
| 747 |
+
with open(logfile, "w") as f:
|
| 748 |
+
# begin the log by printing this file (the Python code)
|
| 749 |
+
f.write('='*100 + '\n')
|
| 750 |
+
f.write(code)
|
| 751 |
+
f.write('='*100 + '\n')
|
| 752 |
+
# log information about the hardware/software environment this is running on
|
| 753 |
+
# and print the full `nvidia-smi` to file
|
| 754 |
+
f.write(f"Running pytorch {torch.version.__version__} compiled for CUDA {torch.version.cuda}\nnvidia-smi:\n")
|
| 755 |
+
import subprocess
|
| 756 |
+
result = subprocess.run(['nvidia-smi'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
|
| 757 |
+
f.write(f'{result.stdout}\n')
|
| 758 |
+
f.write('='*100 + '\n')
|
| 759 |
+
|
| 760 |
+
training_time_ms = 0
|
| 761 |
+
# start the clock
|
| 762 |
+
torch.cuda.synchronize()
|
| 763 |
+
t0 = time.time()
|
| 764 |
+
# begin training
|
| 765 |
+
train_loader.reset()
|
| 766 |
+
for step in range(args.num_iterations + 1):
|
| 767 |
+
last_step = (step == args.num_iterations)
|
| 768 |
+
# This effectively ignores timing first 10 steps, which are slower for weird reasons.
|
| 769 |
+
# Alternately, and slightly more correctly in terms of benchmarking, we could do 10
|
| 770 |
+
# steps with dummy data first, and then re-initialize the model and reset the loader.
|
| 771 |
+
if step == 10:
|
| 772 |
+
training_time_ms = 0
|
| 773 |
+
t0 = time.time()
|
| 774 |
+
timed_steps = float('nan') if step <= 11 else (step - 10) + 1 # <= 11 to avoid bug in val
|
| 775 |
+
|
| 776 |
+
# once in a while evaluate the validation dataset
|
| 777 |
+
if (last_step or (args.val_loss_every > 0 and step % args.val_loss_every == 0)):
|
| 778 |
+
# stop the clock
|
| 779 |
+
torch.cuda.synchronize()
|
| 780 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 781 |
+
# run validation batches
|
| 782 |
+
model.eval()
|
| 783 |
+
val_loader.reset()
|
| 784 |
+
val_loss = 0.0
|
| 785 |
+
for _ in range(val_steps):
|
| 786 |
+
x_val, y_val = val_loader.next_batch()
|
| 787 |
+
with torch.no_grad(): # of course, we'd like to use ctx here too, but that creates a torch.compile error for some reason
|
| 788 |
+
_, loss = model(x_val, y_val, return_logits=False)
|
| 789 |
+
val_loss += loss
|
| 790 |
+
dist.all_reduce(val_loss, op=dist.ReduceOp.AVG)
|
| 791 |
+
val_loss /= val_steps
|
| 792 |
+
# log val loss to console and to logfile
|
| 793 |
+
if master_process:
|
| 794 |
+
print(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms')
|
| 795 |
+
with open(logfile, "a") as f:
|
| 796 |
+
f.write(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms\n')
|
| 797 |
+
# start the clock again
|
| 798 |
+
torch.cuda.synchronize()
|
| 799 |
+
t0 = time.time()
|
| 800 |
+
|
| 801 |
+
if master_process and (last_step or (args.save_every > 0 and step % args.save_every == 0)):
|
| 802 |
+
# stop the clock
|
| 803 |
+
torch.cuda.synchronize()
|
| 804 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 805 |
+
# save the state of the training process
|
| 806 |
+
log = dict(step=step, code=code, model=raw_model.state_dict(), optimizers=[opt.state_dict() for opt in optimizers])
|
| 807 |
+
torch.save(log, 'logs/%s/state_step%06d.pt' % (run_id, step))
|
| 808 |
+
# start the clock again
|
| 809 |
+
torch.cuda.synchronize()
|
| 810 |
+
t0 = time.time()
|
| 811 |
+
|
| 812 |
+
# bit confusing: we want to make sure to eval on 0th iteration
|
| 813 |
+
# but also after the very last iteration. so we loop for step <= num_iterations
|
| 814 |
+
# instead of just < num_iterations (one extra due to <=), only to do
|
| 815 |
+
# the validation/sampling one last time, and then we break right here as we're done.
|
| 816 |
+
if last_step:
|
| 817 |
+
break
|
| 818 |
+
|
| 819 |
+
# --------------- TRAINING SECTION BEGIN -----------------
|
| 820 |
+
model.train()
|
| 821 |
+
for i in range(1, train_accumulation_steps+1):
|
| 822 |
+
# forward pass
|
| 823 |
+
with ctx:
|
| 824 |
+
_, loss = model(x, y, return_logits=False)
|
| 825 |
+
train_loss = loss.detach()
|
| 826 |
+
# advance the dataset for the next batch
|
| 827 |
+
x, y = train_loader.next_batch()
|
| 828 |
+
# backward pass
|
| 829 |
+
if i < train_accumulation_steps:
|
| 830 |
+
with model.no_sync(): # there's no need to sync gradients every accumulation step
|
| 831 |
+
loss.backward()
|
| 832 |
+
else:
|
| 833 |
+
loss.backward() # just sync on the last step
|
| 834 |
+
for p in model.parameters():
|
| 835 |
+
p.grad /= train_accumulation_steps
|
| 836 |
+
# step the optimizers and schedulers
|
| 837 |
+
for opt, sched in zip(optimizers, schedulers):
|
| 838 |
+
opt.step()
|
| 839 |
+
sched.step()
|
| 840 |
+
# null the gradients
|
| 841 |
+
model.zero_grad(set_to_none=True)
|
| 842 |
+
# --------------- TRAINING SECTION END -------------------
|
| 843 |
+
# everything that follows now is just diagnostics, prints, logging, etc.
|
| 844 |
+
|
| 845 |
+
#dist.all_reduce(train_loss, op=dist.ReduceOp.AVG) # all-reducing the training loss would be more correct in terms of logging, but slower
|
| 846 |
+
if master_process:
|
| 847 |
+
approx_time = training_time_ms + 1000 * (time.time() - t0)
|
| 848 |
+
print(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms")
|
| 849 |
+
with open(logfile, "a") as f:
|
| 850 |
+
f.write(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms\n")
|
| 851 |
+
|
| 852 |
+
if master_process:
|
| 853 |
+
print(f"peak memory consumption: {torch.cuda.max_memory_allocated() // 1024 // 1024} MiB")
|
| 854 |
+
|
| 855 |
+
# -------------------------------------------------------------------------
|
| 856 |
+
# clean up nice
|
| 857 |
+
dist.destroy_process_group()
|
records/track_1_short/2024-10-10_Muon/eb5659d0-fb6a-49e5-a311-f1f89412f726.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-10_Muon/train_gpt2.py
ADDED
|
@@ -0,0 +1,524 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
with open(sys.argv[0]) as f:
|
| 4 |
+
code = f.read() # read the code of this file ASAP, for logging
|
| 5 |
+
import uuid
|
| 6 |
+
import glob
|
| 7 |
+
import time
|
| 8 |
+
from dataclasses import dataclass
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torch import nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
import torch._inductor.config as config
|
| 16 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 17 |
+
|
| 18 |
+
# -----------------------------------------------------------------------------
|
| 19 |
+
# Muon optimizer
|
| 20 |
+
|
| 21 |
+
def zeropower_via_svd(G, steps=None):
|
| 22 |
+
U, S, V = G.svd()
|
| 23 |
+
return U @ V.T
|
| 24 |
+
|
| 25 |
+
@torch.compile
|
| 26 |
+
def zeropower_via_newtonschulz5(G, steps=10, eps=1e-7):
|
| 27 |
+
"""
|
| 28 |
+
Newton-Schulz iteration to compute the zeroth power / orthogonalization of G. We opt to use a
|
| 29 |
+
quintic iteration whose coefficients are selected to maximize the slope at zero. For the purpose
|
| 30 |
+
of minimizing steps, it turns out to be empirically effective to keep increasing the slope at
|
| 31 |
+
zero even beyond the point where the iteration no longer converges all the way to one everywhere
|
| 32 |
+
on the interval. This iteration therefore does not produce UV^T but rather something like US'V^T
|
| 33 |
+
where S' is diagonal with S_{ii}' \sim Uniform(0.5, 1.5), which turns out not to hurt model
|
| 34 |
+
performance at all relative to UV^T, where USV^T = G is the SVD.
|
| 35 |
+
"""
|
| 36 |
+
assert len(G.shape) == 2
|
| 37 |
+
a, b, c = (3.4445, -4.7750, 2.0315)
|
| 38 |
+
X = G.bfloat16() / (G.norm() + eps) # ensure top singular value <= 1
|
| 39 |
+
if G.size(0) > G.size(1):
|
| 40 |
+
X = X.T
|
| 41 |
+
for _ in range(steps):
|
| 42 |
+
A = X @ X.T
|
| 43 |
+
B = A @ X
|
| 44 |
+
X = a * X + b * B + c * A @ B
|
| 45 |
+
if G.size(0) > G.size(1):
|
| 46 |
+
X = X.T
|
| 47 |
+
return X.to(G.dtype)
|
| 48 |
+
|
| 49 |
+
zeropower_backends = dict(svd=zeropower_via_svd, newtonschulz5=zeropower_via_newtonschulz5)
|
| 50 |
+
|
| 51 |
+
class Muon(torch.optim.Optimizer):
|
| 52 |
+
"""
|
| 53 |
+
Muon: MomentUm Orthogonalized by Newton-schulz
|
| 54 |
+
|
| 55 |
+
Muon internally runs standard SGD-momentum, and then performs an orthogonalization post-
|
| 56 |
+
processing step, in which each 2D parameter's update is replaced with the nearest orthogonal
|
| 57 |
+
matrix. To efficiently orthogonalize each update, we use a Newton-Schulz iteration, which has
|
| 58 |
+
the advantage that it can be stably run in bfloat16 on the GPU.
|
| 59 |
+
|
| 60 |
+
Some warnings:
|
| 61 |
+
- This optimizer assumes that all parameters passed in are 2D.
|
| 62 |
+
- It should not be used for the embedding layer, the final fully connected layer, or any {0,1}-D
|
| 63 |
+
parameters; those should all be optimized by a standard method (e.g., AdamW).
|
| 64 |
+
- To use it with 4D convolutional filters, it works well to just flatten their last 3 dimensions.
|
| 65 |
+
- We believe it is unlikely to work well for training with small batch size.
|
| 66 |
+
- We believe it may not work well for finetuning pretrained models, but we haven't tested this.
|
| 67 |
+
- We have not yet tried this optimizer for training scenarios larger than NanoGPT (124M).
|
| 68 |
+
|
| 69 |
+
Arguments:
|
| 70 |
+
lr: The learning rate used by the internal SGD.
|
| 71 |
+
momentum: The momentum used by the internal SGD.
|
| 72 |
+
nesterov: Whether to use Nesterov-style momentum in the internal SGD. (recommended)
|
| 73 |
+
backend: The chosen backend for the orthogonalization step. (recommended: 'newtonschulz5')
|
| 74 |
+
backend_steps: The number of iteration steps to use in the backend, if it is iterative.
|
| 75 |
+
"""
|
| 76 |
+
def __init__(self, params, lr=3e-4, momentum=0.95, nesterov=True, backend='newtonschulz5', backend_steps=5):
|
| 77 |
+
defaults = dict(lr=lr, momentum=momentum, nesterov=nesterov, backend=backend, backend_steps=backend_steps)
|
| 78 |
+
super().__init__(params, defaults)
|
| 79 |
+
|
| 80 |
+
def step(self):
|
| 81 |
+
for group in self.param_groups:
|
| 82 |
+
lr = group['lr']
|
| 83 |
+
momentum = group['momentum']
|
| 84 |
+
zeropower_backend = zeropower_backends[group['backend']]
|
| 85 |
+
for p in group['params']:
|
| 86 |
+
g = p.grad
|
| 87 |
+
if g is None:
|
| 88 |
+
continue
|
| 89 |
+
state = self.state[p]
|
| 90 |
+
if 'momentum_buffer' not in state:
|
| 91 |
+
state['momentum_buffer'] = torch.zeros_like(g)
|
| 92 |
+
buf = state['momentum_buffer']
|
| 93 |
+
buf.mul_(momentum).add_(g)
|
| 94 |
+
if group['nesterov']:
|
| 95 |
+
g = g.add(buf, alpha=momentum)
|
| 96 |
+
if g.size(0) == 3 * g.size(1): # split grouped QKV parameters
|
| 97 |
+
g = torch.cat([zeropower_backend(g1, steps=group['backend_steps']) for g1 in g.split(g.size(1))])
|
| 98 |
+
scale = g.size(1)**0.5
|
| 99 |
+
else:
|
| 100 |
+
g = zeropower_backend(g, steps=group['backend_steps'])
|
| 101 |
+
scale = max(g.size(0), g.size(1))**0.5 # scale to have update.square().mean() == 1
|
| 102 |
+
p.data.add_(g, alpha=-lr * scale)
|
| 103 |
+
|
| 104 |
+
# -----------------------------------------------------------------------------
|
| 105 |
+
# PyTorch nn.Module definitions for the GPT-2 model
|
| 106 |
+
|
| 107 |
+
class Rotary(torch.nn.Module):
|
| 108 |
+
|
| 109 |
+
def __init__(self, dim, base=10000):
|
| 110 |
+
super().__init__()
|
| 111 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 112 |
+
self.register_buffer("inv_freq", inv_freq)
|
| 113 |
+
self.seq_len_cached = None
|
| 114 |
+
self.cos_cached = None
|
| 115 |
+
self.sin_cached = None
|
| 116 |
+
|
| 117 |
+
def forward(self, x):
|
| 118 |
+
seq_len = x.shape[1]
|
| 119 |
+
if seq_len != self.seq_len_cached:
|
| 120 |
+
self.seq_len_cached = seq_len
|
| 121 |
+
t = torch.arange(seq_len, device=x.device).type_as(self.inv_freq)
|
| 122 |
+
freqs = torch.outer(t, self.inv_freq).to(x.device)
|
| 123 |
+
self.cos_cached = freqs.cos()
|
| 124 |
+
self.sin_cached = freqs.sin()
|
| 125 |
+
return self.cos_cached[None, :, None, :], self.sin_cached[None, :, None, :]
|
| 126 |
+
|
| 127 |
+
def apply_rotary_emb(x, cos, sin):
|
| 128 |
+
assert x.ndim == 4 # multihead attention
|
| 129 |
+
d = x.shape[3]//2
|
| 130 |
+
x1 = x[..., :d]
|
| 131 |
+
x2 = x[..., d:]
|
| 132 |
+
y1 = x1 * cos + x2 * sin
|
| 133 |
+
y2 = x1 * (-sin) + x2 * cos
|
| 134 |
+
return torch.cat([y1, y2], 3)
|
| 135 |
+
|
| 136 |
+
def rmsnorm(x0, eps=1e-6):
|
| 137 |
+
x = x0.float()
|
| 138 |
+
x = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
|
| 139 |
+
return x.type_as(x0)
|
| 140 |
+
|
| 141 |
+
class CausalSelfAttention(nn.Module):
|
| 142 |
+
|
| 143 |
+
def __init__(self, config):
|
| 144 |
+
super().__init__()
|
| 145 |
+
self.n_head = config.n_head
|
| 146 |
+
self.n_embd = config.n_embd
|
| 147 |
+
self.head_dim = self.n_embd // self.n_head
|
| 148 |
+
assert self.n_embd % self.n_head == 0
|
| 149 |
+
# key, query, value projections for all heads, but in a batch
|
| 150 |
+
self.c_attn = nn.Linear(self.n_embd, 3 * self.n_embd, bias=False)
|
| 151 |
+
# output projection
|
| 152 |
+
self.c_proj = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 153 |
+
self.rotary = Rotary(self.head_dim)
|
| 154 |
+
|
| 155 |
+
def forward(self, x):
|
| 156 |
+
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
|
| 157 |
+
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
|
| 158 |
+
qkv = self.c_attn(x)
|
| 159 |
+
q, k, v = qkv.split(self.n_embd, dim=2)
|
| 160 |
+
k = k.view(B, T, self.n_head, self.head_dim)
|
| 161 |
+
q = q.view(B, T, self.n_head, self.head_dim)
|
| 162 |
+
v = v.view(B, T, self.n_head, self.head_dim)
|
| 163 |
+
cos, sin = self.rotary(q)
|
| 164 |
+
q = apply_rotary_emb(q, cos, sin)
|
| 165 |
+
k = apply_rotary_emb(k, cos, sin)
|
| 166 |
+
y = F.scaled_dot_product_attention(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2), is_causal=True)
|
| 167 |
+
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
|
| 168 |
+
# output projection
|
| 169 |
+
y = self.c_proj(y)
|
| 170 |
+
return y
|
| 171 |
+
|
| 172 |
+
class MLP(nn.Module):
|
| 173 |
+
|
| 174 |
+
def __init__(self, config):
|
| 175 |
+
super().__init__()
|
| 176 |
+
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=False)
|
| 177 |
+
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=False)
|
| 178 |
+
|
| 179 |
+
def forward(self, x):
|
| 180 |
+
x = self.c_fc(x)
|
| 181 |
+
x = F.gelu(x)
|
| 182 |
+
x = self.c_proj(x)
|
| 183 |
+
return x
|
| 184 |
+
|
| 185 |
+
class Block(nn.Module):
|
| 186 |
+
|
| 187 |
+
def __init__(self, config):
|
| 188 |
+
super().__init__()
|
| 189 |
+
self.attn = CausalSelfAttention(config)
|
| 190 |
+
self.mlp = MLP(config)
|
| 191 |
+
self.attn_scale = (1 / (2 * config.n_layer)**0.5)
|
| 192 |
+
|
| 193 |
+
def forward(self, x):
|
| 194 |
+
x = x + self.attn_scale * self.attn(rmsnorm(x))
|
| 195 |
+
x = x + self.mlp(rmsnorm(x))
|
| 196 |
+
return x
|
| 197 |
+
|
| 198 |
+
# -----------------------------------------------------------------------------
|
| 199 |
+
# The main GPT-2 model
|
| 200 |
+
|
| 201 |
+
@dataclass
|
| 202 |
+
class GPTConfig:
|
| 203 |
+
vocab_size : int = 50257
|
| 204 |
+
n_layer : int = 12
|
| 205 |
+
n_head : int = 12
|
| 206 |
+
n_embd : int = 768
|
| 207 |
+
|
| 208 |
+
class GPT(nn.Module):
|
| 209 |
+
|
| 210 |
+
def __init__(self, config):
|
| 211 |
+
super().__init__()
|
| 212 |
+
self.config = config
|
| 213 |
+
|
| 214 |
+
self.transformer = nn.ModuleDict(dict(
|
| 215 |
+
wte = nn.Embedding(config.vocab_size, config.n_embd),
|
| 216 |
+
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
|
| 217 |
+
))
|
| 218 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 219 |
+
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
|
| 220 |
+
|
| 221 |
+
def forward(self, idx, targets=None, return_logits=True):
|
| 222 |
+
b, t = idx.size()
|
| 223 |
+
pos = torch.arange(0, t, dtype=torch.long, device=idx.device) # shape (t)
|
| 224 |
+
|
| 225 |
+
# forward the GPT model itself
|
| 226 |
+
x = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
|
| 227 |
+
|
| 228 |
+
for block in self.transformer.h:
|
| 229 |
+
x = block(x)
|
| 230 |
+
x = rmsnorm(x)
|
| 231 |
+
|
| 232 |
+
if targets is not None:
|
| 233 |
+
# if we are given some desired targets also calculate the loss
|
| 234 |
+
logits = self.lm_head(x)
|
| 235 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 236 |
+
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
|
| 237 |
+
else:
|
| 238 |
+
# inference-time mini-optimization: only forward the lm_head on the very last position
|
| 239 |
+
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
|
| 240 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 241 |
+
loss = None
|
| 242 |
+
|
| 243 |
+
# there are performance reasons why not returning logits is prudent, if not needed
|
| 244 |
+
if not return_logits:
|
| 245 |
+
logits = None
|
| 246 |
+
|
| 247 |
+
return logits, loss
|
| 248 |
+
|
| 249 |
+
# -----------------------------------------------------------------------------
|
| 250 |
+
# Our own simple Distributed Data Loader
|
| 251 |
+
|
| 252 |
+
def _peek_data_shard(filename):
|
| 253 |
+
# only reads the header, returns header data
|
| 254 |
+
with open(filename, "rb") as f:
|
| 255 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 256 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 257 |
+
if header[0] != 20240520:
|
| 258 |
+
print("ERROR: magic number mismatch in the data .bin file!")
|
| 259 |
+
print("---> HINT: Are you passing in a correct file with --input_bin?")
|
| 260 |
+
print("---> HINT: Dataset encoding changed recently, re-run data prepro or refer again to README")
|
| 261 |
+
print("---> HINT: For example re-run: `python dev/data/tinyshakespeare.py`, then re-try")
|
| 262 |
+
exit(1)
|
| 263 |
+
assert header[1] == 1, "unsupported version"
|
| 264 |
+
ntok = header[2] # number of tokens (claimed)
|
| 265 |
+
return ntok # for now just return the number of tokens
|
| 266 |
+
|
| 267 |
+
def _load_data_shard(filename):
|
| 268 |
+
with open(filename, "rb") as f:
|
| 269 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 270 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 271 |
+
assert header[0] == 20240520, "magic number mismatch in the data .bin file"
|
| 272 |
+
assert header[1] == 1, "unsupported version"
|
| 273 |
+
ntok = header[2] # number of tokens (claimed)
|
| 274 |
+
# the rest of it are tokens, stored as uint16
|
| 275 |
+
tokens = np.frombuffer(f.read(), dtype=np.uint16)
|
| 276 |
+
assert len(tokens) == ntok, "number of tokens read does not match header?"
|
| 277 |
+
return tokens
|
| 278 |
+
|
| 279 |
+
class DistributedDataLoader:
|
| 280 |
+
def __init__(self, filename_pattern, B, T, process_rank, num_processes):
|
| 281 |
+
self.process_rank = process_rank
|
| 282 |
+
self.num_processes = num_processes
|
| 283 |
+
self.B = B
|
| 284 |
+
self.T = T
|
| 285 |
+
|
| 286 |
+
# glob files that match the pattern
|
| 287 |
+
self.files = sorted(glob.glob(filename_pattern))
|
| 288 |
+
assert len(self.files) > 0, f"did not find any files that match the pattern {filename_pattern}"
|
| 289 |
+
|
| 290 |
+
# load and validate all data shards, count number of tokens in total
|
| 291 |
+
ntok_total = 0
|
| 292 |
+
for fname in self.files:
|
| 293 |
+
shard_ntok = _peek_data_shard(fname)
|
| 294 |
+
assert shard_ntok >= num_processes * B * T + 1
|
| 295 |
+
ntok_total += int(shard_ntok)
|
| 296 |
+
self.ntok_total = ntok_total
|
| 297 |
+
|
| 298 |
+
# kick things off
|
| 299 |
+
self.reset()
|
| 300 |
+
|
| 301 |
+
def reset(self):
|
| 302 |
+
self.current_shard = 0
|
| 303 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 304 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 305 |
+
|
| 306 |
+
def advance(self): # advance to next data shard
|
| 307 |
+
self.current_shard = (self.current_shard + 1) % len(self.files)
|
| 308 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 309 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 310 |
+
|
| 311 |
+
def next_batch(self):
|
| 312 |
+
B = self.B
|
| 313 |
+
T = self.T
|
| 314 |
+
buf = self.tokens[self.current_position : self.current_position+B*T+1]
|
| 315 |
+
buf = torch.tensor(buf.astype(np.int32), dtype=torch.long)
|
| 316 |
+
x = (buf[:-1]).view(B, T) # inputs
|
| 317 |
+
y = (buf[1:]).view(B, T) # targets
|
| 318 |
+
# advance current position and load next shard if necessary
|
| 319 |
+
self.current_position += B * T * self.num_processes
|
| 320 |
+
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
|
| 321 |
+
self.advance()
|
| 322 |
+
return x.cuda(), y.cuda()
|
| 323 |
+
|
| 324 |
+
# -----------------------------------------------------------------------------
|
| 325 |
+
# int main
|
| 326 |
+
|
| 327 |
+
@dataclass
|
| 328 |
+
class Hyperparameters:
|
| 329 |
+
# data hyperparams
|
| 330 |
+
input_bin : str = 'data/fineweb10B/fineweb_train_*.bin' # input .bin to train on
|
| 331 |
+
input_val_bin : str = 'data/fineweb10B/fineweb_val_*.bin' # input .bin to eval validation loss on
|
| 332 |
+
# optimization hyperparams
|
| 333 |
+
batch_size : int = 8*64 # batch size, in sequences, across all devices
|
| 334 |
+
device_batch_size : int = 64 # batch size, in sequences, per device
|
| 335 |
+
sequence_length : int = 1024 # sequence length, in tokens
|
| 336 |
+
num_iterations : int = 6200 # number of iterations to run
|
| 337 |
+
learning_rate : float = 0.0036
|
| 338 |
+
warmup_iters : int = 0
|
| 339 |
+
warmdown_iters : int = 1800 # number of iterations of linear warmup/warmdown for triangular or trapezoidal schedule
|
| 340 |
+
weight_decay : float = 0
|
| 341 |
+
# evaluation and logging hyperparams
|
| 342 |
+
val_loss_every : int = 125 # every how many steps to evaluate val loss? 0 for only at the end
|
| 343 |
+
val_tokens : int = 10485760 # how many tokens of validation data? it's important to keep this fixed for consistent comparisons
|
| 344 |
+
save_every : int = 0 # every how many steps to save the checkpoint? 0 for only at the end
|
| 345 |
+
args = Hyperparameters()
|
| 346 |
+
|
| 347 |
+
# set up DDP (distributed data parallel). torchrun sets this env variable
|
| 348 |
+
assert torch.cuda.is_available()
|
| 349 |
+
dist.init_process_group(backend='nccl')
|
| 350 |
+
ddp_rank = int(os.environ['RANK'])
|
| 351 |
+
ddp_local_rank = int(os.environ['LOCAL_RANK'])
|
| 352 |
+
ddp_world_size = int(os.environ['WORLD_SIZE'])
|
| 353 |
+
device = f'cuda:{ddp_local_rank}'
|
| 354 |
+
torch.cuda.set_device(device)
|
| 355 |
+
print(f"using device: {device}")
|
| 356 |
+
master_process = (ddp_rank == 0) # this process will do logging, checkpointing etc.
|
| 357 |
+
|
| 358 |
+
# convenience variables
|
| 359 |
+
B, T = args.device_batch_size, args.sequence_length
|
| 360 |
+
# calculate the number of steps to take in the val loop.
|
| 361 |
+
assert args.val_tokens % (B * T * ddp_world_size) == 0
|
| 362 |
+
val_steps = args.val_tokens // (B * T * ddp_world_size)
|
| 363 |
+
# calculate the steps of gradient accumulation required to attain the desired global batch size.
|
| 364 |
+
assert args.batch_size % (B * ddp_world_size) == 0
|
| 365 |
+
train_accumulation_steps = args.batch_size // (B * ddp_world_size)
|
| 366 |
+
|
| 367 |
+
# load tokens
|
| 368 |
+
train_loader = DistributedDataLoader(args.input_bin, B, T, ddp_rank, ddp_world_size)
|
| 369 |
+
val_loader = DistributedDataLoader(args.input_val_bin, B, T, ddp_rank, ddp_world_size)
|
| 370 |
+
if master_process:
|
| 371 |
+
print(f"Training DataLoader: total number of tokens: {train_loader.ntok_total} across {len(train_loader.files)} files")
|
| 372 |
+
print(f"Validation DataLoader: total number of tokens: {val_loader.ntok_total} across {len(val_loader.files)} files")
|
| 373 |
+
x, y = train_loader.next_batch()
|
| 374 |
+
|
| 375 |
+
# init the model from scratch
|
| 376 |
+
num_vocab = 50257
|
| 377 |
+
model = GPT(GPTConfig(vocab_size=num_vocab, n_layer=12, n_head=12, n_embd=768))
|
| 378 |
+
model = model.cuda()
|
| 379 |
+
if hasattr(config, "coordinate_descent_tuning"):
|
| 380 |
+
config.coordinate_descent_tuning = True # suggested by @Chillee
|
| 381 |
+
model = torch.compile(model)
|
| 382 |
+
# here we wrap model into DDP container
|
| 383 |
+
model = DDP(model, device_ids=[ddp_local_rank])
|
| 384 |
+
raw_model = model.module # always contains the "raw" unwrapped model
|
| 385 |
+
ctx = torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16)
|
| 386 |
+
|
| 387 |
+
# init the optimizer(s)
|
| 388 |
+
optimizer1 = torch.optim.AdamW(raw_model.lm_head.parameters(), lr=args.learning_rate, betas=(0.9, 0.95),
|
| 389 |
+
weight_decay=args.weight_decay, fused=True)
|
| 390 |
+
optimizer2 = Muon(raw_model.transformer.h.parameters(), lr=0.1*args.learning_rate, momentum=0.95)
|
| 391 |
+
optimizers = [optimizer1, optimizer2]
|
| 392 |
+
# learning rate decay scheduler (linear warmup and warmdown)
|
| 393 |
+
def get_lr(it):
|
| 394 |
+
assert it <= args.num_iterations
|
| 395 |
+
# 1) linear warmup for warmup_iters steps
|
| 396 |
+
if it < args.warmup_iters:
|
| 397 |
+
return (it+1) / args.warmup_iters
|
| 398 |
+
# 2) constant lr for a while
|
| 399 |
+
elif it < args.num_iterations - args.warmdown_iters:
|
| 400 |
+
return 1.0
|
| 401 |
+
# 3) linear warmdown
|
| 402 |
+
else:
|
| 403 |
+
decay_ratio = (args.num_iterations - it) / args.warmdown_iters
|
| 404 |
+
return decay_ratio
|
| 405 |
+
schedulers = [torch.optim.lr_scheduler.LambdaLR(opt, get_lr) for opt in optimizers]
|
| 406 |
+
|
| 407 |
+
# begin logging
|
| 408 |
+
if master_process:
|
| 409 |
+
run_id = str(uuid.uuid4())
|
| 410 |
+
logdir = 'logs/%s/' % run_id
|
| 411 |
+
os.makedirs(logdir, exist_ok=True)
|
| 412 |
+
logfile = 'logs/%s.txt' % run_id
|
| 413 |
+
# create the log file
|
| 414 |
+
with open(logfile, "w") as f:
|
| 415 |
+
# begin the log by printing this file (the Python code)
|
| 416 |
+
f.write('='*100 + '\n')
|
| 417 |
+
f.write(code)
|
| 418 |
+
f.write('='*100 + '\n')
|
| 419 |
+
# log information about the hardware/software environment this is running on
|
| 420 |
+
# and print the full `nvidia-smi` to file
|
| 421 |
+
f.write(f"Running pytorch {torch.version.__version__} compiled for CUDA {torch.version.cuda}\nnvidia-smi:\n")
|
| 422 |
+
import subprocess
|
| 423 |
+
result = subprocess.run(['nvidia-smi'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
|
| 424 |
+
f.write(f'{result.stdout}\n')
|
| 425 |
+
f.write('='*100 + '\n')
|
| 426 |
+
|
| 427 |
+
training_time_ms = 0
|
| 428 |
+
# start the clock
|
| 429 |
+
torch.cuda.synchronize()
|
| 430 |
+
t0 = time.time()
|
| 431 |
+
# begin training
|
| 432 |
+
train_loader.reset()
|
| 433 |
+
for step in range(args.num_iterations + 1):
|
| 434 |
+
last_step = (step == args.num_iterations)
|
| 435 |
+
# This effectively ignores timing first 10 steps, which are slower for weird reasons.
|
| 436 |
+
# Alternately, and slightly more correctly in terms of benchmarking, we could do 10
|
| 437 |
+
# steps with dummy data first, and then re-initialize the model and reset the loader.
|
| 438 |
+
if step == 10:
|
| 439 |
+
training_time_ms = 0
|
| 440 |
+
t0 = time.time()
|
| 441 |
+
timed_steps = float('nan') if step <= 11 else (step - 10) + 1 # <= 11 to avoid bug in val
|
| 442 |
+
|
| 443 |
+
# once in a while evaluate the validation dataset
|
| 444 |
+
if (last_step or (args.val_loss_every > 0 and step % args.val_loss_every == 0)):
|
| 445 |
+
# stop the clock
|
| 446 |
+
torch.cuda.synchronize()
|
| 447 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 448 |
+
# run validation batches
|
| 449 |
+
model.eval()
|
| 450 |
+
val_loader.reset()
|
| 451 |
+
val_loss = 0.0
|
| 452 |
+
for _ in range(val_steps):
|
| 453 |
+
x_val, y_val = val_loader.next_batch()
|
| 454 |
+
with torch.no_grad(): # of course, we'd like to use ctx here too, but that creates a torch.compile error for some reason
|
| 455 |
+
_, loss = model(x_val, y_val, return_logits=False)
|
| 456 |
+
val_loss += loss
|
| 457 |
+
dist.all_reduce(val_loss, op=dist.ReduceOp.AVG)
|
| 458 |
+
val_loss /= val_steps
|
| 459 |
+
# log val loss to console and to logfile
|
| 460 |
+
if master_process:
|
| 461 |
+
print(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms')
|
| 462 |
+
with open(logfile, "a") as f:
|
| 463 |
+
f.write(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms\n')
|
| 464 |
+
# start the clock again
|
| 465 |
+
torch.cuda.synchronize()
|
| 466 |
+
t0 = time.time()
|
| 467 |
+
|
| 468 |
+
if master_process and (last_step or (args.save_every > 0 and step % args.save_every == 0)):
|
| 469 |
+
# stop the clock
|
| 470 |
+
torch.cuda.synchronize()
|
| 471 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 472 |
+
# save the state of the training process
|
| 473 |
+
log = dict(step=step, code=code, model=raw_model.state_dict(), optimizers=[opt.state_dict() for opt in optimizers])
|
| 474 |
+
torch.save(log, 'logs/%s/state_step%06d.pt' % (run_id, step))
|
| 475 |
+
# start the clock again
|
| 476 |
+
torch.cuda.synchronize()
|
| 477 |
+
t0 = time.time()
|
| 478 |
+
|
| 479 |
+
# bit confusing: we want to make sure to eval on 0th iteration
|
| 480 |
+
# but also after the very last iteration. so we loop for step <= num_iterations
|
| 481 |
+
# instead of just < num_iterations (one extra due to <=), only to do
|
| 482 |
+
# the validation/sampling one last time, and then we break right here as we're done.
|
| 483 |
+
if last_step:
|
| 484 |
+
break
|
| 485 |
+
|
| 486 |
+
# --------------- TRAINING SECTION BEGIN -----------------
|
| 487 |
+
model.train()
|
| 488 |
+
for i in range(1, train_accumulation_steps+1):
|
| 489 |
+
# forward pass
|
| 490 |
+
with ctx:
|
| 491 |
+
_, loss = model(x, y, return_logits=False)
|
| 492 |
+
train_loss = loss.detach()
|
| 493 |
+
# advance the dataset for the next batch
|
| 494 |
+
x, y = train_loader.next_batch()
|
| 495 |
+
# backward pass
|
| 496 |
+
if i < train_accumulation_steps:
|
| 497 |
+
with model.no_sync(): # there's no need to sync gradients every accumulation step
|
| 498 |
+
loss.backward()
|
| 499 |
+
else:
|
| 500 |
+
loss.backward() # just sync on the last step
|
| 501 |
+
for p in model.parameters():
|
| 502 |
+
p.grad /= train_accumulation_steps
|
| 503 |
+
# step the optimizers and schedulers
|
| 504 |
+
for opt, sched in zip(optimizers, schedulers):
|
| 505 |
+
opt.step()
|
| 506 |
+
sched.step()
|
| 507 |
+
# null the gradients
|
| 508 |
+
model.zero_grad(set_to_none=True)
|
| 509 |
+
# --------------- TRAINING SECTION END -------------------
|
| 510 |
+
# everything that follows now is just diagnostics, prints, logging, etc.
|
| 511 |
+
|
| 512 |
+
#dist.all_reduce(train_loss, op=dist.ReduceOp.AVG) # all-reducing the training loss would be more correct in terms of logging, but slower
|
| 513 |
+
if master_process:
|
| 514 |
+
approx_time = training_time_ms + 1000 * (time.time() - t0)
|
| 515 |
+
print(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms")
|
| 516 |
+
with open(logfile, "a") as f:
|
| 517 |
+
f.write(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms\n")
|
| 518 |
+
|
| 519 |
+
if master_process:
|
| 520 |
+
print(f"peak memory consumption: {torch.cuda.max_memory_allocated() // 1024 // 1024} MiB")
|
| 521 |
+
|
| 522 |
+
# -------------------------------------------------------------------------
|
| 523 |
+
# clean up nice
|
| 524 |
+
dist.destroy_process_group()
|
records/track_1_short/2024-10-13_llmc/README.md
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This is a log produced by running the current version of Andrej Karpathy's [llm.c](https://github.com/karpathy/llm.c), as of October 13th 2024.
|
| 2 |
+
|
| 3 |
+
It was run on a node with 8x H100 HBM3 according to the instructions [here](https://github.com/karpathy/llm.c/discussions/481).
|
| 4 |
+
The mean per-step time was 140ms. The total number of training tokens is 10.26B. The final validation loss was **3.2722**.
|
| 5 |
+
|
| 6 |
+
This is (significantly) better than the quoted result of **3.29** val loss in
|
| 7 |
+
[Andrej Karpathy's May 28th GPT-2 replication discussion](https://github.com/karpathy/llm.c/discussions/481#:~:text=By%20the%20end%20of%20the%20optimization%20we%27ll%20get%20to%20about%203.29).
|
| 8 |
+
So it appears that there have been some improvements to the training algorithm used by llm.c since then.
|
| 9 |
+
|
| 10 |
+
Note that the set of examples which llm.c uses for validation appears to be the same as what we do in this repo, i.e., the first `10 * 2**20` tokens of the val set.
|
| 11 |
+
|
records/track_1_short/2024-10-13_llmc/main.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-14_ModernArch/dabaaddd-237c-4ec9-939d-6608a9ed5e27.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-14_ModernArch/train_gpt2.py
ADDED
|
@@ -0,0 +1,516 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
with open(sys.argv[0]) as f:
|
| 4 |
+
code = f.read() # read the code of this file ASAP, for logging
|
| 5 |
+
import uuid
|
| 6 |
+
import glob
|
| 7 |
+
import time
|
| 8 |
+
from dataclasses import dataclass
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torch import nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
import torch._inductor.config as config
|
| 16 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 17 |
+
|
| 18 |
+
# -----------------------------------------------------------------------------
|
| 19 |
+
# Muon optimizer
|
| 20 |
+
|
| 21 |
+
def zeropower_via_svd(G, steps=None):
|
| 22 |
+
U, S, V = G.svd()
|
| 23 |
+
return U @ V.T
|
| 24 |
+
|
| 25 |
+
@torch.compile
|
| 26 |
+
def zeropower_via_newtonschulz5(G, steps=10, eps=1e-7):
|
| 27 |
+
"""
|
| 28 |
+
Newton-Schulz iteration to compute the zeroth power / orthogonalization of G. We opt to use a
|
| 29 |
+
quintic iteration whose coefficients are selected to maximize the slope at zero. For the purpose
|
| 30 |
+
of minimizing steps, it turns out to be empirically effective to keep increasing the slope at
|
| 31 |
+
zero even beyond the point where the iteration no longer converges all the way to one everywhere
|
| 32 |
+
on the interval. This iteration therefore does not produce UV^T but rather something like US'V^T
|
| 33 |
+
where S' is diagonal with S_{ii}' \sim Uniform(0.5, 1.5), which turns out not to hurt model
|
| 34 |
+
performance at all relative to UV^T, where USV^T = G is the SVD.
|
| 35 |
+
"""
|
| 36 |
+
assert len(G.shape) == 2
|
| 37 |
+
a, b, c = (3.4445, -4.7750, 2.0315)
|
| 38 |
+
X = G.bfloat16()
|
| 39 |
+
X /= (X.norm() + eps) # ensure top singular value <= 1
|
| 40 |
+
if G.size(0) > G.size(1):
|
| 41 |
+
X = X.T
|
| 42 |
+
for _ in range(steps):
|
| 43 |
+
A = X @ X.T
|
| 44 |
+
B = A @ X
|
| 45 |
+
X = a * X + b * B + c * A @ B
|
| 46 |
+
if G.size(0) > G.size(1):
|
| 47 |
+
X = X.T
|
| 48 |
+
return X
|
| 49 |
+
|
| 50 |
+
zeropower_backends = dict(svd=zeropower_via_svd, newtonschulz5=zeropower_via_newtonschulz5)
|
| 51 |
+
|
| 52 |
+
class Muon(torch.optim.Optimizer):
|
| 53 |
+
"""
|
| 54 |
+
Muon - MomentUm Orthogonalized by Newton-schulz
|
| 55 |
+
|
| 56 |
+
Muon internally runs standard SGD-momentum, and then performs an orthogonalization post-
|
| 57 |
+
processing step, in which each 2D parameter's update is replaced with the nearest orthogonal
|
| 58 |
+
matrix. To efficiently orthogonalize each update, we use a Newton-Schulz iteration, which has
|
| 59 |
+
the advantage that it can be stably run in bfloat16 on the GPU.
|
| 60 |
+
|
| 61 |
+
Some warnings:
|
| 62 |
+
- This optimizer assumes that all parameters passed in are 2D.
|
| 63 |
+
- It should not be used for the embedding layer, the final fully connected layer, or any {0,1}-D
|
| 64 |
+
parameters; those should all be optimized by a standard method (e.g., AdamW).
|
| 65 |
+
- To use it with 4D convolutional filters, it works well to just flatten their last 3 dimensions.
|
| 66 |
+
- We believe it is unlikely to work well for training with small batch size.
|
| 67 |
+
- We believe it may not work well for finetuning pretrained models, but we haven't tested this.
|
| 68 |
+
- We have not yet tried this optimizer for training scenarios larger than NanoGPT (124M).
|
| 69 |
+
|
| 70 |
+
Arguments:
|
| 71 |
+
lr: The learning rate used by the internal SGD.
|
| 72 |
+
momentum: The momentum used by the internal SGD.
|
| 73 |
+
nesterov: Whether to use Nesterov-style momentum in the internal SGD. (recommended)
|
| 74 |
+
backend: The chosen backend for the orthogonalization step. (recommended: 'newtonschulz5')
|
| 75 |
+
backend_steps: The number of iteration steps to use in the backend, if it is iterative.
|
| 76 |
+
"""
|
| 77 |
+
def __init__(self, params, lr=3e-4, momentum=0.95, nesterov=True, backend='newtonschulz5', backend_steps=5):
|
| 78 |
+
defaults = dict(lr=lr, momentum=momentum, nesterov=nesterov, backend=backend, backend_steps=backend_steps)
|
| 79 |
+
super().__init__(params, defaults)
|
| 80 |
+
|
| 81 |
+
def step(self):
|
| 82 |
+
for group in self.param_groups:
|
| 83 |
+
lr = group['lr']
|
| 84 |
+
momentum = group['momentum']
|
| 85 |
+
zeropower_backend = zeropower_backends[group['backend']]
|
| 86 |
+
for p in group['params']:
|
| 87 |
+
g = p.grad
|
| 88 |
+
if g is None:
|
| 89 |
+
continue
|
| 90 |
+
state = self.state[p]
|
| 91 |
+
if 'momentum_buffer' not in state:
|
| 92 |
+
state['momentum_buffer'] = torch.zeros_like(g)
|
| 93 |
+
buf = state['momentum_buffer']
|
| 94 |
+
buf.mul_(momentum).add_(g)
|
| 95 |
+
if group['nesterov']:
|
| 96 |
+
g = g.add(buf, alpha=momentum)
|
| 97 |
+
if g.size(0) == 3 * g.size(1): # split grouped QKV parameters
|
| 98 |
+
g = torch.cat([zeropower_backend(g1, steps=group['backend_steps']) for g1 in g.split(g.size(1))])
|
| 99 |
+
scale = g.size(1)**0.5
|
| 100 |
+
else:
|
| 101 |
+
g = zeropower_backend(g, steps=group['backend_steps'])
|
| 102 |
+
scale = max(g.size(0), g.size(1))**0.5 # scale to have update.square().mean() == 1
|
| 103 |
+
p.data.add_(g, alpha=-lr * scale)
|
| 104 |
+
|
| 105 |
+
# -----------------------------------------------------------------------------
|
| 106 |
+
# PyTorch nn.Module definitions for the GPT-2 model
|
| 107 |
+
|
| 108 |
+
class Rotary(torch.nn.Module):
|
| 109 |
+
|
| 110 |
+
def __init__(self, dim, base=10000):
|
| 111 |
+
super().__init__()
|
| 112 |
+
self.inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float() / dim))
|
| 113 |
+
self.seq_len_cached = None
|
| 114 |
+
self.cos_cached = None
|
| 115 |
+
self.sin_cached = None
|
| 116 |
+
|
| 117 |
+
def forward(self, x):
|
| 118 |
+
seq_len = x.shape[1]
|
| 119 |
+
if seq_len != self.seq_len_cached:
|
| 120 |
+
self.seq_len_cached = seq_len
|
| 121 |
+
t = torch.arange(seq_len, device=x.device).type_as(self.inv_freq)
|
| 122 |
+
freqs = torch.outer(t, self.inv_freq).to(x.device)
|
| 123 |
+
self.cos_cached = freqs.cos().bfloat16()
|
| 124 |
+
self.sin_cached = freqs.sin().bfloat16()
|
| 125 |
+
return self.cos_cached[None, :, None, :], self.sin_cached[None, :, None, :]
|
| 126 |
+
|
| 127 |
+
def apply_rotary_emb(x, cos, sin):
|
| 128 |
+
assert x.ndim == 4 # multihead attention
|
| 129 |
+
d = x.shape[3]//2
|
| 130 |
+
x1 = x[..., :d]
|
| 131 |
+
x2 = x[..., d:]
|
| 132 |
+
y1 = x1 * cos + x2 * sin
|
| 133 |
+
y2 = x1 * (-sin) + x2 * cos
|
| 134 |
+
return torch.cat([y1, y2], 3).type_as(x)
|
| 135 |
+
|
| 136 |
+
class CausalSelfAttention(nn.Module):
|
| 137 |
+
|
| 138 |
+
def __init__(self, config):
|
| 139 |
+
super().__init__()
|
| 140 |
+
self.n_head = config.n_head
|
| 141 |
+
self.n_embd = config.n_embd
|
| 142 |
+
self.head_dim = self.n_embd // self.n_head
|
| 143 |
+
assert self.n_embd % self.n_head == 0
|
| 144 |
+
self.c_q = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 145 |
+
self.c_k = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 146 |
+
self.c_v = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 147 |
+
# output projection
|
| 148 |
+
self.c_proj = nn.Linear(self.n_embd, self.n_embd, bias=False)
|
| 149 |
+
self.c_proj.weight.data.zero_() # zero init suggested by @Grad62304977
|
| 150 |
+
self.rotary = Rotary(self.head_dim)
|
| 151 |
+
|
| 152 |
+
def forward(self, x):
|
| 153 |
+
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
|
| 154 |
+
q = self.c_q(x).view(B, T, self.n_head, self.head_dim)
|
| 155 |
+
k = self.c_k(x).view(B, T, self.n_head, self.head_dim)
|
| 156 |
+
v = self.c_v(x).view(B, T, self.n_head, self.head_dim)
|
| 157 |
+
cos, sin = self.rotary(q)
|
| 158 |
+
q, k = apply_rotary_emb(q, cos, sin), apply_rotary_emb(k, cos, sin)
|
| 159 |
+
q, k = F.rms_norm(q, (q.size(-1),)), F.rms_norm(k, (k.size(-1),)) # QK norm suggested by @Grad62304977
|
| 160 |
+
y = F.scaled_dot_product_attention(q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2), is_causal=True)
|
| 161 |
+
y = y.transpose(1, 2).contiguous().view_as(x) # re-assemble all head outputs side by side
|
| 162 |
+
y = self.c_proj(y)
|
| 163 |
+
return y
|
| 164 |
+
|
| 165 |
+
class MLP(nn.Module):
|
| 166 |
+
|
| 167 |
+
def __init__(self, config):
|
| 168 |
+
super().__init__()
|
| 169 |
+
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=False)
|
| 170 |
+
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=False)
|
| 171 |
+
self.c_proj.weight.data.zero_() # zero init suggested by @Grad62304977
|
| 172 |
+
|
| 173 |
+
def forward(self, x):
|
| 174 |
+
x = self.c_fc(x)
|
| 175 |
+
x = F.relu(x).square() # https://arxiv.org/abs/2109.08668v2; ~1-2% better than GELU; suggested by @SKYLINEZ007 and @Grad62304977
|
| 176 |
+
x = self.c_proj(x)
|
| 177 |
+
return x
|
| 178 |
+
|
| 179 |
+
class Block(nn.Module):
|
| 180 |
+
|
| 181 |
+
def __init__(self, config):
|
| 182 |
+
super().__init__()
|
| 183 |
+
self.attn = CausalSelfAttention(config)
|
| 184 |
+
self.mlp = MLP(config)
|
| 185 |
+
|
| 186 |
+
def forward(self, x):
|
| 187 |
+
x = x + self.attn(F.rms_norm(x, (x.size(-1),)))
|
| 188 |
+
x = x + self.mlp(F.rms_norm(x, (x.size(-1),)))
|
| 189 |
+
return x
|
| 190 |
+
|
| 191 |
+
# -----------------------------------------------------------------------------
|
| 192 |
+
# The main GPT-2 model
|
| 193 |
+
|
| 194 |
+
@dataclass
|
| 195 |
+
class GPTConfig:
|
| 196 |
+
vocab_size : int = 50304
|
| 197 |
+
n_layer : int = 12
|
| 198 |
+
n_head : int = 6 # head dim 128 suggested by @Grad62304977
|
| 199 |
+
n_embd : int = 768
|
| 200 |
+
|
| 201 |
+
class GPT(nn.Module):
|
| 202 |
+
|
| 203 |
+
def __init__(self, config):
|
| 204 |
+
super().__init__()
|
| 205 |
+
self.config = config
|
| 206 |
+
|
| 207 |
+
self.transformer = nn.ModuleDict(dict(
|
| 208 |
+
wte = nn.Embedding(config.vocab_size, config.n_embd),
|
| 209 |
+
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
|
| 210 |
+
))
|
| 211 |
+
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
|
| 212 |
+
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
|
| 213 |
+
|
| 214 |
+
def forward(self, idx, targets=None, return_logits=True):
|
| 215 |
+
|
| 216 |
+
# forward the GPT model itself
|
| 217 |
+
x = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
|
| 218 |
+
for block in self.transformer.h:
|
| 219 |
+
x = block(x)
|
| 220 |
+
x = F.rms_norm(x, (x.size(-1),))
|
| 221 |
+
|
| 222 |
+
if targets is not None:
|
| 223 |
+
# if we are given some desired targets also calculate the loss
|
| 224 |
+
logits = self.lm_head(x)
|
| 225 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 226 |
+
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
|
| 227 |
+
else:
|
| 228 |
+
# inference-time mini-optimization: only forward the lm_head on the very last position
|
| 229 |
+
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
|
| 230 |
+
logits = logits.float() # use tf32/fp32 for logits
|
| 231 |
+
loss = None
|
| 232 |
+
|
| 233 |
+
# there are performance reasons why not returning logits is prudent, if not needed
|
| 234 |
+
if not return_logits:
|
| 235 |
+
logits = None
|
| 236 |
+
|
| 237 |
+
return logits, loss
|
| 238 |
+
|
| 239 |
+
# -----------------------------------------------------------------------------
|
| 240 |
+
# Our own simple Distributed Data Loader
|
| 241 |
+
|
| 242 |
+
def _peek_data_shard(filename):
|
| 243 |
+
# only reads the header, returns header data
|
| 244 |
+
with open(filename, "rb") as f:
|
| 245 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 246 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 247 |
+
if header[0] != 20240520:
|
| 248 |
+
print("ERROR: magic number mismatch in the data .bin file!")
|
| 249 |
+
print("---> HINT: Are you passing in a correct file with --input_bin?")
|
| 250 |
+
print("---> HINT: Dataset encoding changed recently, re-run data prepro or refer again to README")
|
| 251 |
+
print("---> HINT: For example re-run: `python dev/data/tinyshakespeare.py`, then re-try")
|
| 252 |
+
exit(1)
|
| 253 |
+
assert header[1] == 1, "unsupported version"
|
| 254 |
+
ntok = header[2] # number of tokens (claimed)
|
| 255 |
+
return ntok # for now just return the number of tokens
|
| 256 |
+
|
| 257 |
+
def _load_data_shard(filename):
|
| 258 |
+
with open(filename, "rb") as f:
|
| 259 |
+
# first read the header, which is 256 int32 integers (4 bytes each)
|
| 260 |
+
header = np.frombuffer(f.read(256*4), dtype=np.int32)
|
| 261 |
+
assert header[0] == 20240520, "magic number mismatch in the data .bin file"
|
| 262 |
+
assert header[1] == 1, "unsupported version"
|
| 263 |
+
ntok = header[2] # number of tokens (claimed)
|
| 264 |
+
# the rest of it are tokens, stored as uint16
|
| 265 |
+
tokens = np.frombuffer(f.read(), dtype=np.uint16)
|
| 266 |
+
assert len(tokens) == ntok, "number of tokens read does not match header?"
|
| 267 |
+
return tokens
|
| 268 |
+
|
| 269 |
+
class DistributedDataLoader:
|
| 270 |
+
def __init__(self, filename_pattern, B, T, process_rank, num_processes):
|
| 271 |
+
self.process_rank = process_rank
|
| 272 |
+
self.num_processes = num_processes
|
| 273 |
+
self.B = B
|
| 274 |
+
self.T = T
|
| 275 |
+
|
| 276 |
+
# glob files that match the pattern
|
| 277 |
+
self.files = sorted(glob.glob(filename_pattern))
|
| 278 |
+
assert len(self.files) > 0, f"did not find any files that match the pattern {filename_pattern}"
|
| 279 |
+
|
| 280 |
+
# load and validate all data shards, count number of tokens in total
|
| 281 |
+
ntok_total = 0
|
| 282 |
+
for fname in self.files:
|
| 283 |
+
shard_ntok = _peek_data_shard(fname)
|
| 284 |
+
assert shard_ntok >= num_processes * B * T + 1
|
| 285 |
+
ntok_total += int(shard_ntok)
|
| 286 |
+
self.ntok_total = ntok_total
|
| 287 |
+
|
| 288 |
+
# kick things off
|
| 289 |
+
self.reset()
|
| 290 |
+
|
| 291 |
+
def reset(self):
|
| 292 |
+
self.current_shard = 0
|
| 293 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 294 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 295 |
+
|
| 296 |
+
def advance(self): # advance to next data shard
|
| 297 |
+
self.current_shard = (self.current_shard + 1) % len(self.files)
|
| 298 |
+
self.current_position = self.process_rank * self.B * self.T
|
| 299 |
+
self.tokens = _load_data_shard(self.files[self.current_shard])
|
| 300 |
+
|
| 301 |
+
def next_batch(self):
|
| 302 |
+
B = self.B
|
| 303 |
+
T = self.T
|
| 304 |
+
buf = self.tokens[self.current_position : self.current_position+B*T+1]
|
| 305 |
+
buf = torch.tensor(buf.astype(np.int32), dtype=torch.long)
|
| 306 |
+
x = (buf[:-1]).view(B, T) # inputs
|
| 307 |
+
y = (buf[1:]).view(B, T) # targets
|
| 308 |
+
# advance current position and load next shard if necessary
|
| 309 |
+
self.current_position += B * T * self.num_processes
|
| 310 |
+
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
|
| 311 |
+
self.advance()
|
| 312 |
+
return x.cuda(), y.cuda()
|
| 313 |
+
|
| 314 |
+
# -----------------------------------------------------------------------------
|
| 315 |
+
# int main
|
| 316 |
+
|
| 317 |
+
@dataclass
|
| 318 |
+
class Hyperparameters:
|
| 319 |
+
# data hyperparams
|
| 320 |
+
input_bin : str = 'data/fineweb10B/fineweb_train_*.bin' # input .bin to train on
|
| 321 |
+
input_val_bin : str = 'data/fineweb10B/fineweb_val_*.bin' # input .bin to eval validation loss on
|
| 322 |
+
# optimization hyperparams
|
| 323 |
+
batch_size : int = 8*64 # batch size, in sequences, across all devices
|
| 324 |
+
device_batch_size : int = 64 # batch size, in sequences, per device
|
| 325 |
+
sequence_length : int = 1024 # sequence length, in tokens
|
| 326 |
+
num_iterations : int = 5100 # number of iterations to run
|
| 327 |
+
learning_rate : float = 0.0036
|
| 328 |
+
warmup_iters : int = 0
|
| 329 |
+
warmdown_iters : int = 1450 # number of iterations of linear warmup/warmdown for triangular or trapezoidal schedule
|
| 330 |
+
weight_decay : float = 0
|
| 331 |
+
# evaluation and logging hyperparams
|
| 332 |
+
val_loss_every : int = 125 # every how many steps to evaluate val loss? 0 for only at the end
|
| 333 |
+
val_tokens : int = 10485760 # how many tokens of validation data? it's important to keep this fixed for consistent comparisons
|
| 334 |
+
save_every : int = 0 # every how many steps to save the checkpoint? 0 for only at the end
|
| 335 |
+
args = Hyperparameters()
|
| 336 |
+
|
| 337 |
+
# set up DDP (distributed data parallel). torchrun sets this env variable
|
| 338 |
+
assert torch.cuda.is_available()
|
| 339 |
+
dist.init_process_group(backend='nccl')
|
| 340 |
+
ddp_rank = int(os.environ['RANK'])
|
| 341 |
+
ddp_local_rank = int(os.environ['LOCAL_RANK'])
|
| 342 |
+
ddp_world_size = int(os.environ['WORLD_SIZE'])
|
| 343 |
+
device = f'cuda:{ddp_local_rank}'
|
| 344 |
+
torch.cuda.set_device(device)
|
| 345 |
+
print(f"using device: {device}")
|
| 346 |
+
master_process = (ddp_rank == 0) # this process will do logging, checkpointing etc.
|
| 347 |
+
|
| 348 |
+
# convenience variables
|
| 349 |
+
B, T = args.device_batch_size, args.sequence_length
|
| 350 |
+
# calculate the number of steps to take in the val loop.
|
| 351 |
+
assert args.val_tokens % (B * T * ddp_world_size) == 0
|
| 352 |
+
val_steps = args.val_tokens // (B * T * ddp_world_size)
|
| 353 |
+
# calculate the steps of gradient accumulation required to attain the desired global batch size.
|
| 354 |
+
assert args.batch_size % (B * ddp_world_size) == 0
|
| 355 |
+
train_accumulation_steps = args.batch_size // (B * ddp_world_size)
|
| 356 |
+
|
| 357 |
+
# load tokens
|
| 358 |
+
train_loader = DistributedDataLoader(args.input_bin, B, T, ddp_rank, ddp_world_size)
|
| 359 |
+
val_loader = DistributedDataLoader(args.input_val_bin, B, T, ddp_rank, ddp_world_size)
|
| 360 |
+
if master_process:
|
| 361 |
+
print(f"Training DataLoader: total number of tokens: {train_loader.ntok_total} across {len(train_loader.files)} files")
|
| 362 |
+
print(f"Validation DataLoader: total number of tokens: {val_loader.ntok_total} across {len(val_loader.files)} files")
|
| 363 |
+
x, y = train_loader.next_batch()
|
| 364 |
+
|
| 365 |
+
# there are only 50257 unique GPT-2 tokens; we extend to nearest multiple of 128 for efficiency. suggested to me by @Grad62304977.
|
| 366 |
+
# this originates from Karpathy's experiments.
|
| 367 |
+
num_vocab = 50304
|
| 368 |
+
model = GPT(GPTConfig(vocab_size=num_vocab, n_layer=12, n_head=6, n_embd=768))
|
| 369 |
+
model = model.cuda()
|
| 370 |
+
if hasattr(config, "coordinate_descent_tuning"):
|
| 371 |
+
config.coordinate_descent_tuning = True # suggested by @Chillee
|
| 372 |
+
model = torch.compile(model)
|
| 373 |
+
# here we wrap model into DDP container
|
| 374 |
+
model = DDP(model, device_ids=[ddp_local_rank])
|
| 375 |
+
raw_model = model.module # always contains the "raw" unwrapped model
|
| 376 |
+
ctx = torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16)
|
| 377 |
+
|
| 378 |
+
# init the optimizer(s)
|
| 379 |
+
optimizer1 = torch.optim.AdamW(raw_model.lm_head.parameters(), lr=args.learning_rate, betas=(0.9, 0.95),
|
| 380 |
+
weight_decay=args.weight_decay, fused=True)
|
| 381 |
+
optimizer2 = Muon(raw_model.transformer.h.parameters(), lr=0.1*args.learning_rate, momentum=0.95)
|
| 382 |
+
optimizers = [optimizer1, optimizer2]
|
| 383 |
+
# learning rate decay scheduler (linear warmup and warmdown)
|
| 384 |
+
def get_lr(it):
|
| 385 |
+
assert it <= args.num_iterations
|
| 386 |
+
# 1) linear warmup for warmup_iters steps
|
| 387 |
+
if it < args.warmup_iters:
|
| 388 |
+
return (it+1) / args.warmup_iters
|
| 389 |
+
# 2) constant lr for a while
|
| 390 |
+
elif it < args.num_iterations - args.warmdown_iters:
|
| 391 |
+
return 1.0
|
| 392 |
+
# 3) linear warmdown
|
| 393 |
+
else:
|
| 394 |
+
decay_ratio = (args.num_iterations - it) / args.warmdown_iters
|
| 395 |
+
return decay_ratio
|
| 396 |
+
schedulers = [torch.optim.lr_scheduler.LambdaLR(opt, get_lr) for opt in optimizers]
|
| 397 |
+
|
| 398 |
+
# begin logging
|
| 399 |
+
if master_process:
|
| 400 |
+
run_id = str(uuid.uuid4())
|
| 401 |
+
logdir = 'logs/%s/' % run_id
|
| 402 |
+
os.makedirs(logdir, exist_ok=True)
|
| 403 |
+
logfile = 'logs/%s.txt' % run_id
|
| 404 |
+
# create the log file
|
| 405 |
+
with open(logfile, "w") as f:
|
| 406 |
+
# begin the log by printing this file (the Python code)
|
| 407 |
+
f.write('='*100 + '\n')
|
| 408 |
+
f.write(code)
|
| 409 |
+
f.write('='*100 + '\n')
|
| 410 |
+
# log information about the hardware/software environment this is running on
|
| 411 |
+
# and print the full `nvidia-smi` to file
|
| 412 |
+
f.write(f"Running pytorch {torch.version.__version__} compiled for CUDA {torch.version.cuda}\nnvidia-smi:\n")
|
| 413 |
+
import subprocess
|
| 414 |
+
result = subprocess.run(['nvidia-smi'], stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
|
| 415 |
+
f.write(f'{result.stdout}\n')
|
| 416 |
+
f.write('='*100 + '\n')
|
| 417 |
+
|
| 418 |
+
training_time_ms = 0
|
| 419 |
+
# start the clock
|
| 420 |
+
torch.cuda.synchronize()
|
| 421 |
+
t0 = time.time()
|
| 422 |
+
# begin training
|
| 423 |
+
train_loader.reset()
|
| 424 |
+
for step in range(args.num_iterations + 1):
|
| 425 |
+
last_step = (step == args.num_iterations)
|
| 426 |
+
# This effectively ignores timing first 10 steps, which are slower for weird reasons.
|
| 427 |
+
# Alternately, and slightly more correctly in terms of benchmarking, we could do 10
|
| 428 |
+
# steps with dummy data first, and then re-initialize the model and reset the loader.
|
| 429 |
+
if step == 10:
|
| 430 |
+
training_time_ms = 0
|
| 431 |
+
t0 = time.time()
|
| 432 |
+
timed_steps = float('nan') if step <= 11 else (step - 10) + 1 # <= 11 to avoid bug in val
|
| 433 |
+
|
| 434 |
+
# once in a while evaluate the validation dataset
|
| 435 |
+
if (last_step or (args.val_loss_every > 0 and step % args.val_loss_every == 0)):
|
| 436 |
+
# stop the clock
|
| 437 |
+
torch.cuda.synchronize()
|
| 438 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 439 |
+
# run validation batches
|
| 440 |
+
model.eval()
|
| 441 |
+
val_loader.reset()
|
| 442 |
+
val_loss = 0.0
|
| 443 |
+
for _ in range(val_steps):
|
| 444 |
+
x_val, y_val = val_loader.next_batch()
|
| 445 |
+
with ctx: # of course, we'd like to use no_grad() here too, but that creates a torch.compile error for some reason
|
| 446 |
+
_, loss = model(x_val, y_val, return_logits=False)
|
| 447 |
+
val_loss += loss.detach()
|
| 448 |
+
del loss
|
| 449 |
+
dist.all_reduce(val_loss, op=dist.ReduceOp.AVG)
|
| 450 |
+
val_loss /= val_steps
|
| 451 |
+
# log val loss to console and to logfile
|
| 452 |
+
if master_process:
|
| 453 |
+
print(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms')
|
| 454 |
+
with open(logfile, "a") as f:
|
| 455 |
+
f.write(f'step:{step}/{args.num_iterations} val_loss:{val_loss:.4f} train_time:{training_time_ms:.0f}ms step_avg:{training_time_ms/(timed_steps-1):.2f}ms\n')
|
| 456 |
+
# start the clock again
|
| 457 |
+
torch.cuda.synchronize()
|
| 458 |
+
t0 = time.time()
|
| 459 |
+
|
| 460 |
+
if master_process and (last_step or (args.save_every > 0 and step % args.save_every == 0)):
|
| 461 |
+
# stop the clock
|
| 462 |
+
torch.cuda.synchronize()
|
| 463 |
+
training_time_ms += 1000 * (time.time() - t0)
|
| 464 |
+
# save the state of the training process
|
| 465 |
+
log = dict(step=step, code=code, model=raw_model.state_dict(), optimizers=[opt.state_dict() for opt in optimizers])
|
| 466 |
+
torch.save(log, 'logs/%s/state_step%06d.pt' % (run_id, step))
|
| 467 |
+
# start the clock again
|
| 468 |
+
torch.cuda.synchronize()
|
| 469 |
+
t0 = time.time()
|
| 470 |
+
|
| 471 |
+
# bit confusing: we want to make sure to eval on 0th iteration
|
| 472 |
+
# but also after the very last iteration. so we loop for step <= num_iterations
|
| 473 |
+
# instead of just < num_iterations (one extra due to <=), only to do
|
| 474 |
+
# the validation/sampling one last time, and then we break right here as we're done.
|
| 475 |
+
if last_step:
|
| 476 |
+
break
|
| 477 |
+
|
| 478 |
+
# --------------- TRAINING SECTION BEGIN -----------------
|
| 479 |
+
model.train()
|
| 480 |
+
for i in range(1, train_accumulation_steps+1):
|
| 481 |
+
# forward pass
|
| 482 |
+
with ctx:
|
| 483 |
+
_, loss = model(x, y, return_logits=False)
|
| 484 |
+
train_loss = loss.detach()
|
| 485 |
+
# advance the dataset for the next batch
|
| 486 |
+
x, y = train_loader.next_batch()
|
| 487 |
+
# backward pass
|
| 488 |
+
if i < train_accumulation_steps:
|
| 489 |
+
with model.no_sync(): # there's no need to sync gradients every accumulation step
|
| 490 |
+
loss.backward()
|
| 491 |
+
else:
|
| 492 |
+
loss.backward() # just sync on the last step
|
| 493 |
+
for p in model.parameters():
|
| 494 |
+
p.grad /= train_accumulation_steps
|
| 495 |
+
# step the optimizers and schedulers
|
| 496 |
+
for opt, sched in zip(optimizers, schedulers):
|
| 497 |
+
opt.step()
|
| 498 |
+
sched.step()
|
| 499 |
+
# null the gradients
|
| 500 |
+
model.zero_grad(set_to_none=True)
|
| 501 |
+
# --------------- TRAINING SECTION END -------------------
|
| 502 |
+
# everything that follows now is just diagnostics, prints, logging, etc.
|
| 503 |
+
|
| 504 |
+
#dist.all_reduce(train_loss, op=dist.ReduceOp.AVG) # all-reducing the training loss would be more correct in terms of logging, but slower
|
| 505 |
+
if master_process:
|
| 506 |
+
approx_time = training_time_ms + 1000 * (time.time() - t0)
|
| 507 |
+
print(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms")
|
| 508 |
+
with open(logfile, "a") as f:
|
| 509 |
+
f.write(f"step:{step+1}/{args.num_iterations} train_loss:{train_loss.item():.4f} train_time:{approx_time:.0f}ms step_avg:{approx_time/timed_steps:.2f}ms\n")
|
| 510 |
+
|
| 511 |
+
if master_process:
|
| 512 |
+
print(f"peak memory consumption: {torch.cuda.max_memory_allocated() // 1024 // 1024} MiB")
|
| 513 |
+
|
| 514 |
+
# -------------------------------------------------------------------------
|
| 515 |
+
# clean up nice
|
| 516 |
+
dist.destroy_process_group()
|
records/track_1_short/2024-10-17_DistributedMuon/22d24867-eb5a-4fcc-ae2c-263d0277dfd1.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-18_PyTorch25/d4bfb25f-688d-4da5-8743-33926fad4842.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-20_ScaleUp1B/87bd51fd-6203-4c88-b3aa-8a849a6a83ca.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-20_ScaleUp1B/ad8d7ae5-7b2d-4ee9-bc52-f912e9174d7a.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-20_ScaleUp1B/c0078066-c8c9-49c8-868a-ff4d4f32e615.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-29_Optimizers/8bfe4e35-c3fc-4b70-a984-3be937b71ff3.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-29_Optimizers/8d6193f4-27fc-4e68-899f-af70019a4d54.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-29_Optimizers/95a9fd44-7c13-49c7-b324-3e7d9e23a499.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-29_Optimizers/README.md
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Optimizer comparison for NanoGPT speedrunning
|
| 2 |
+
|
| 3 |
+
This is a comparison between the four best optimizers I am aware of for NanoGPT speedrunning. They are compared using the 10/18/24 NanoGPT speedrunning record.
|
| 4 |
+
|
| 5 |
+
Reproducible logs:
|
| 6 |
+
* [Adam](95a9fd44-7c13-49c7-b324-3e7d9e23a499.txt)
|
| 7 |
+
* [DistributedShampoo](8bfe4e35-c3fc-4b70-a984-3be937b71ff3)
|
| 8 |
+
* [SOAP](e21a2838-a0f2-46f2-a247-db0021165682.txt)
|
| 9 |
+
* [Muon](8d6193f4-27fc-4e68-899f-af70019a4d54.txt)
|
| 10 |
+
|
| 11 |
+
Results:
|
| 12 |
+

|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
### General notes for all optimizers
|
| 16 |
+
|
| 17 |
+
All optimizers are run using zero weight decay (which is found to be empirically optimal).
|
| 18 |
+
|
| 19 |
+
And they are all run with a warmup-stable-decay / trapezoidal schedule, which also seems to be optimal. That's what causes the kink in the loss curve ~75% of the way to the end.
|
| 20 |
+
|
| 21 |
+
In addition, in all cases, we optimize the shared embedding/head layer just using Adam (which is also found to be empirically optimal).
|
| 22 |
+
Note that in the following code snippets, `raw_model.transformer.h.parameters()` gives all parameters besides those two.
|
| 23 |
+
|
| 24 |
+
In each case, the hyperparameters are the best ones I could find in around 20 attempts.
|
| 25 |
+
|
| 26 |
+
## [Adam](95a9fd44-7c13-49c7-b324-3e7d9e23a499.txt)
|
| 27 |
+
The optimizer here is equivalent to:
|
| 28 |
+
```
|
| 29 |
+
torch.optim.Adam(raw_model.transformer.h.parameters(), lr=0.0018, betas=(0.9, 0.95))
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## [DistributedShampoo](8bfe4e35-c3fc-4b70-a984-3be937b71ff3.txt)
|
| 34 |
+
Run as follows:
|
| 35 |
+
```
|
| 36 |
+
DistributedShampoo(
|
| 37 |
+
raw_model.transformer.h.parameters(),
|
| 38 |
+
lr=0.0018,
|
| 39 |
+
betas=(0.95, 0.95),
|
| 40 |
+
epsilon=1e-12,
|
| 41 |
+
weight_decay=0,
|
| 42 |
+
max_preconditioner_dim=8192,
|
| 43 |
+
precondition_frequency=10,
|
| 44 |
+
use_decoupled_weight_decay=True,
|
| 45 |
+
grafting_config=AdamGraftingConfig(
|
| 46 |
+
beta2=0.95,
|
| 47 |
+
epsilon=1e-8,
|
| 48 |
+
),
|
| 49 |
+
distributed_config=DDPShampooConfig(
|
| 50 |
+
communication_dtype=CommunicationDType.FP32,
|
| 51 |
+
num_trainers_per_group=8,
|
| 52 |
+
communicate_params=False,
|
| 53 |
+
),
|
| 54 |
+
)
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
This is using the official `DistributedShampoo` implementation from [here](https://github.com/facebookresearch/optimizers/tree/ad2809a291c01859f68fcabbcb49a2aa75fd7827/distributed_shampoo).
|
| 58 |
+
|
| 59 |
+
Things that turned out to be important:
|
| 60 |
+
* Don't use epsilon above 1e-8; this loses performance. Epsilon 1e-12 performs as well as 1e-15
|
| 61 |
+
* Betas=(0.95, 0.95) seemed optimal, which turns out to be the same thing that SOAP uses
|
| 62 |
+
* Higher preconditioner update frequency is better but slower
|
| 63 |
+
|
| 64 |
+
I'm open to hyperparameter suggestions; the experiment takes ~20-30 minutes to run on a fresh 8xH100 instance, so it's not hard for me to run more attempts.
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## [SOAP](e21a2838-a0f2-46f2-a247-db0021165682.txt)
|
| 68 |
+
```
|
| 69 |
+
SOAP(model.transformer.h.parameters(), lr=0.0018, betas=(.95, .95), precondition_frequency=10)
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
This is using the official SOAP implementation [here](https://github.com/nikhilvyas/SOAP/blob/bbce86e890d3b697380f4376acb600c2d6c3d203/soap.py).
|
| 73 |
+
|
| 74 |
+
Based on conversations with the authors, it is likely that a future SOAP implementation will significantly reduce the wallclock overhead.
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
## [Muon](8d6193f4-27fc-4e68-899f-af70019a4d54.txt)
|
| 78 |
+
```
|
| 79 |
+
Muon(raw_model.transformer.h.parameters(), lr=0.02, momentum=0.95)
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
## Openness
|
| 84 |
+
|
| 85 |
+
These training logs are reproducible (just cut out the part besides the code, and run it using the `run.sh` in the top-level folder). They take 12-25 minutes to run.
|
| 86 |
+
|
| 87 |
+
I tried to do a good job sweeping the hyperparameters for each optimizer, but I can easily have missed something, or just not have performed enough runs.
|
| 88 |
+
|
| 89 |
+
Therefore, I am interested in any better hyperparameter settings which other researchers can find, for any of the optimizers.
|
| 90 |
+
If you post or send me your own reproducible log with one of these optimizers, I will be very happy to boost it in any way I can.
|
| 91 |
+
|
| 92 |
+
## Appendix: Negative results
|
| 93 |
+
|
| 94 |
+
I believe it was Shazeer who said something like "negative results in machine learning are not worth much, because your inability to make something work doesn't prove that it can't work"
|
| 95 |
+
|
| 96 |
+
Given that disclaimer, here are some optimizers that I tried to make work, but was unable to get a significant boost over Adam with:
|
| 97 |
+
* Sophia
|
| 98 |
+
* Lion
|
| 99 |
+
* AdamWScheduleFree
|
| 100 |
+
* AdEmaMix (actually this was slightly better than Adam, just not enough to get near competing with the three Shampoo-like optimizers)
|
| 101 |
+
|
| 102 |
+
Of course, this is just for NanoGPT speedrunning (short train duration); it's quite possible they work better at longer training duration or for larger models.
|
| 103 |
+
|
records/track_1_short/2024-10-29_Optimizers/e21a2838-a0f2-46f2-a247-db0021165682.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun81w.png
ADDED

|
Git LFS Details
|
records/track_1_short/2024-10-29_Optimizers/nanogpt_speedrun82w.png
ADDED

|
Git LFS Details
|
records/track_1_short/2024-11-03_UntieEmbed/README.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# New record 11/03/24
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
New NanoGPT training speed record: 3.28 FineWeb val loss in 10.8 minutes on 8xH100
|
| 5 |
+
|
| 6 |
+
Previous record: 12.0 minutes
|
| 7 |
+
Changelog:
|
| 8 |
+
- untied embed and head weights
|
| 9 |
+
- added RMSNorm after embed
|
| 10 |
+
- init head to zero
|
| 11 |
+
|
| 12 |
+
Driven by @Grad62304977
|
| 13 |
+
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
Technically, this is somewhat of an "any%" record, since untying the embedding and lm_head adds 39M parameters.
|
| 17 |
+
|
| 18 |
+
However, it doesn't change the number of active parameters or the inference throughput. Future records will stay constrained to 124M active parameters.
|
| 19 |
+
|
| 20 |
+
---
|
| 21 |
+
|
| 22 |
+
Like the last architectural change, this record was driven by @Grad62304977. I just finetuned some things and did bookkeeping.
|
| 23 |
+
|
| 24 |
+
---
|
| 25 |
+
|
| 26 |
+
Shoutout to @cloneofsimo whose scaling guide already suggests initializing the head to zero. This works quite well and is a significant fraction of the record.
|
| 27 |
+
|
records/track_1_short/2024-11-03_UntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-04_50Bruns/3d715d41-453a-40d6-9506-421ba69766b2.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-04_50Bruns/4fbe61ec-f79a-4c19-836d-46d599deecce.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-04_50Bruns/530f3ee1-8862-4d21-be2b-da10eb05e6a9.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-04_50Bruns/69c33fc9-eabb-4a38-aa08-6922914eb405.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-04_50Bruns/README.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 50B-token runs
|
| 2 |
+
|
| 3 |
+
This folder contains four runs generated by extending the 11/03/24 speedrun record to 50B FineWeb tokens.
|
| 4 |
+
The goal is to test how the speedrun generalizes to long durations, and especially how well Muon does.
|
| 5 |
+
|
| 6 |
+
We compare two things:
|
| 7 |
+
1. We compare Muon to Adam as the optimizer for the transformer body. (The head and embedding are always optimized by Adam.)
|
| 8 |
+
2. We compare training on 5 epochs of 10B tokens to training on 50B tokens. (Surprisingly this does about the same)
|
| 9 |
+
|
| 10 |
+
The four resulting runs are as follows:
|
| 11 |
+
|
| 12 |
+
* [Muon 50B tokens](./530f3ee1-8862-4d21-be2b-da10eb05e6a9.txt) (HellaSwag=35.82)
|
| 13 |
+
* [Adam 50B tokens](./69c33fc9-eabb-4a38-aa08-6922914eb405.txt) (HellaSwag=34.26)
|
| 14 |
+
* [Muon 5x10B tokens](./4fbe61ec-f79a-4c19-836d-46d599deecce.txt) (HellaSwag=36.17)
|
| 15 |
+
* [Adam 5x10B tokens](./3d715d41-453a-40d6-9506-421ba69766b2.txt) (HellaSwag=34.05)
|
| 16 |
+
|
| 17 |
+
To get a sense of what a good HellaSwag score would be for this scale of model, here are some baselines:
|
| 18 |
+
* Karpathy's baseline llm.c training (trained for 10B FineWeb tokens): 29.9
|
| 19 |
+
* OpenAI GPT-2 (124M): 29.4
|
| 20 |
+
* OpenAI GPT-3 (124M) (trained for 300B WebText tokens): 33.7
|
| 21 |
+
* Huggingface SmolLM2-135M (trained for 2T FineWeb/DCLM/etc tokens): 42.1
|
| 22 |
+
|
| 23 |
+
Note: I'm a little concerned that the learning rate schedule (WSD) and weight decay (zero), which are tuned for the speedrun duration,
|
| 24 |
+
might become undertuned/suboptimal for trainings of this duration.
|
| 25 |
+
It does look like the gap between Muon/Adam is too large to be closed by something like this, and the HellaSwag scores look quite reasonable, but you never know.
|
| 26 |
+
|
records/track_1_short/2024-11-06_ShortcutsTweaks/042f9e87-07e6-4504-bb04-4ec59a380211.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
records/track_1_short/2024-11-06_ShortcutsTweaks/05b29e54-0be0-4a0f-a1e2-7d5317daedd3.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|