
upd Model family in readme
Browse files- .gitattributes +1 -0
- README.md +10 -10
- diagrams/diagram_01.png +0 -0
- diagrams/diagram_02.png +2 -2
.gitattributes
CHANGED
|
@@ -35,3 +35,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
diagrams/diagram_02.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
diagrams/diagram_02.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
diagrams/diagram_01.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -19,7 +19,7 @@ Retains the full visual tower — this is a **VLM-capable** model (image + text
|
|
| 19 |
Primary use-case: Unsloth LoRA fine-tuning when you need image understanding in the
|
| 20 |
fine-tuned result.
|
| 21 |
|
| 22 |
-
> If you only need text fine-tuning, use
|
| 23 |
> [techwithsergiu/Qwen3.5-text-2B-bnb-4bit](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B-bnb-4bit)
|
| 24 |
> instead — same backbone, visual tower removed, lighter VRAM footprint.
|
| 25 |
|
|
@@ -33,16 +33,16 @@ fine-tuned result.
|
|
| 33 |
|
| 34 |

|
| 35 |
|
| 36 |
-
| Model |
|
| 37 |
|---|---|---|
|
| 38 |
-
| [Qwen/Qwen3.5-2B](https://huggingface.co/Qwen/Qwen3.5-2B) | f16 |
|
| 39 |
-
| **techwithsergiu/Qwen3.5-2B-bnb-4bit** | BNB NF4 |
|
| 40 |
-
| [techwithsergiu/Qwen3.5-text-2B](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B) | bf16 |
|
| 41 |
-
| [techwithsergiu/Qwen3.5-text-2B-bnb-4bit](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B-bnb-4bit) | BNB NF4 |
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
|
| 47 |
## Fine-tuning
|
| 48 |
|
|
|
|
| 19 |
Primary use-case: Unsloth LoRA fine-tuning when you need image understanding in the
|
| 20 |
fine-tuned result.
|
| 21 |
|
| 22 |
+
> If you only need text fine-tuning, use
|
| 23 |
> [techwithsergiu/Qwen3.5-text-2B-bnb-4bit](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B-bnb-4bit)
|
| 24 |
> instead — same backbone, visual tower removed, lighter VRAM footprint.
|
| 25 |
|
|
|
|
| 33 |
|
| 34 |

|
| 35 |
|
| 36 |
+
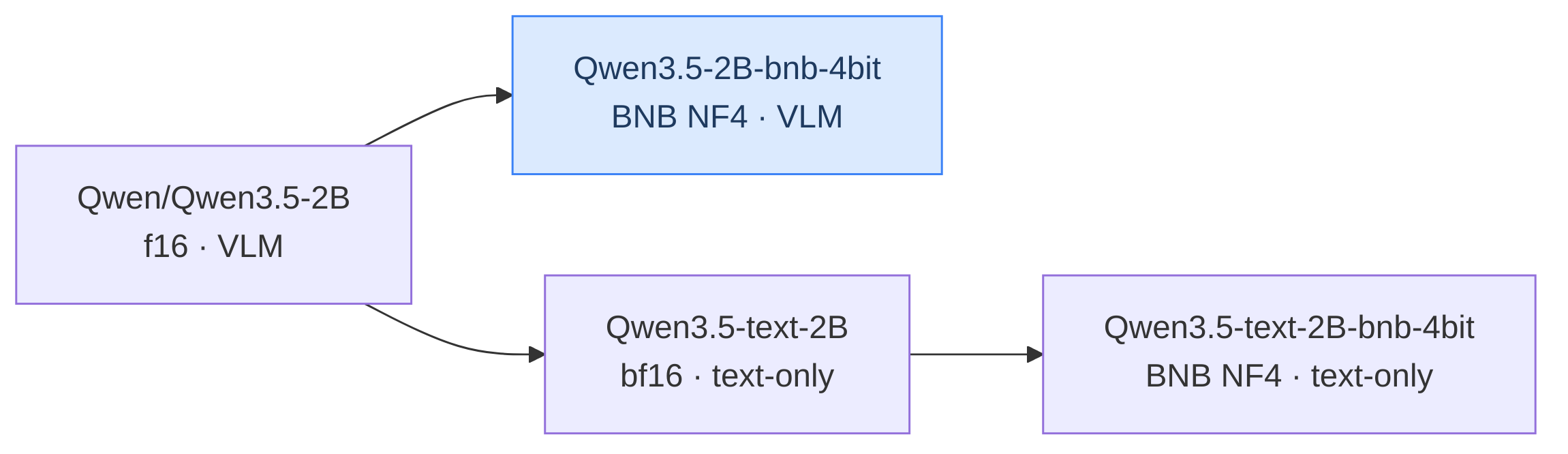
| Model | Type | Base model |
|
| 37 |
|---|---|---|
|
| 38 |
+
| [Qwen/Qwen3.5-2B](https://huggingface.co/Qwen/Qwen3.5-2B) | f16 · VLM · source | — |
|
| 39 |
+
| **[techwithsergiu/Qwen3.5-2B-bnb-4bit](https://huggingface.co/techwithsergiu/Qwen3.5-2B-bnb-4bit)** | BNB NF4 · VLM | Qwen/Qwen3.5-2B |
|
| 40 |
+
| [techwithsergiu/Qwen3.5-text-2B](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B) | bf16 · text-only | Qwen/Qwen3.5-2B |
|
| 41 |
+
| [techwithsergiu/Qwen3.5-text-2B-bnb-4bit](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B-bnb-4bit) | BNB NF4 · text-only | Qwen3.5-text-2B |
|
| 42 |
+
| [techwithsergiu/Qwen3.5-text-2B-GGUF](https://huggingface.co/techwithsergiu/Qwen3.5-text-2B-GGUF) | GGUF quants | Qwen3.5-text-2B |
|
| 43 |
+
|
| 44 |
+
The visual tower is a fixed ~0.65 GB bf16 overhead shared across all model sizes.
|
| 45 |
+
BNB-quantized models are roughly 40% of the original f16 size (exact ratio varies by size).
|
| 46 |
|
| 47 |
## Fine-tuning
|
| 48 |
|
diagrams/diagram_01.png
CHANGED
|

|
Git LFS Details
|
diagrams/diagram_02.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|