
Model save
Browse files- README.md +74 -0
- adapter_config.json +34 -0
- adapter_model.safetensors +3 -0
- added_tokens.json +6 -0
- all_results.json +12 -0
- configuration.json +1 -0
- eval_results.json +7 -0
- merges.txt +0 -0
- runs/Sep18_15-21-27_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644108.dsw-83959-79687bc578-gqp55.2469751.0 +3 -0
- runs/Sep18_15-21-27_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644152.dsw-83959-79687bc578-gqp55.2469751.1 +3 -0
- runs/Sep18_15-27-00_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644432.dsw-83959-79687bc578-gqp55.2473061.0 +3 -0
- runs/Sep18_15-29-21_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644632.dsw-83959-79687bc578-gqp55.2474228.0 +3 -0
- special_tokens_map.json +20 -0
- tokenizer.json +0 -0
- tokenizer_config.json +52 -0
- train_results.json +8 -0
- trainer_log.jsonl +10 -0
- trainer_state.json +114 -0
- training_args.bin +3 -0
- training_eval_loss.png +0 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: Qwen/Qwen2-0.5B-Instruct
|
| 3 |
+
library_name: peft
|
| 4 |
+
license: apache-2.0
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- lora
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: test_0918_upload_3
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# test_0918_upload_3
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [Qwen/Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the None dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 1.9728
|
| 22 |
+
|
| 23 |
+
## Model description
|
| 24 |
+
|
| 25 |
+
More information needed
|
| 26 |
+
|
| 27 |
+
## Intended uses & limitations
|
| 28 |
+
|
| 29 |
+
More information needed
|
| 30 |
+
|
| 31 |
+
## Training and evaluation data
|
| 32 |
+
|
| 33 |
+
More information needed
|
| 34 |
+
|
| 35 |
+
## Training procedure
|
| 36 |
+
|
| 37 |
+
### Training hyperparameters
|
| 38 |
+
|
| 39 |
+
The following hyperparameters were used during training:
|
| 40 |
+
- learning_rate: 0.0001
|
| 41 |
+
- train_batch_size: 1
|
| 42 |
+
- eval_batch_size: 1
|
| 43 |
+
- seed: 42
|
| 44 |
+
- distributed_type: multi-GPU
|
| 45 |
+
- num_devices: 2
|
| 46 |
+
- total_train_batch_size: 2
|
| 47 |
+
- total_eval_batch_size: 2
|
| 48 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 49 |
+
- lr_scheduler_type: cosine
|
| 50 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 51 |
+
- num_epochs: 1
|
| 52 |
+
|
| 53 |
+
### Training results
|
| 54 |
+
|
| 55 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 56 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 57 |
+
| No log | 0.1111 | 1 | 2.5265 |
|
| 58 |
+
| No log | 0.2222 | 2 | 2.4336 |
|
| 59 |
+
| No log | 0.3333 | 3 | 2.3057 |
|
| 60 |
+
| No log | 0.4444 | 4 | 2.2072 |
|
| 61 |
+
| No log | 0.5556 | 5 | 2.1376 |
|
| 62 |
+
| No log | 0.6667 | 6 | 2.0650 |
|
| 63 |
+
| No log | 0.7778 | 7 | 2.0119 |
|
| 64 |
+
| No log | 0.8889 | 8 | 1.9691 |
|
| 65 |
+
| No log | 1.0 | 9 | 1.9728 |
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
### Framework versions
|
| 69 |
+
|
| 70 |
+
- PEFT 0.12.0
|
| 71 |
+
- Transformers 4.45.0.dev0
|
| 72 |
+
- Pytorch 2.4.0+cu121
|
| 73 |
+
- Datasets 2.18.0
|
| 74 |
+
- Tokenizers 0.19.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "Qwen/Qwen2-0.5B-Instruct",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"q_proj",
|
| 24 |
+
"o_proj",
|
| 25 |
+
"down_proj",
|
| 26 |
+
"gate_proj",
|
| 27 |
+
"v_proj",
|
| 28 |
+
"up_proj",
|
| 29 |
+
"k_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d2dd0b9c1d7fc3dc00348676b5562662738f0fabffb89472191457f2d6ab8a3
|
| 3 |
+
size 17640136
|
added_tokens.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|eot_id|>": 151646,
|
| 4 |
+
"<|im_end|>": 151645,
|
| 5 |
+
"<|im_start|>": 151644
|
| 6 |
+
}
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 1.804765224456787,
|
| 4 |
+
"eval_runtime": 0.0629,
|
| 5 |
+
"eval_samples_per_second": 31.789,
|
| 6 |
+
"eval_steps_per_second": 15.894,
|
| 7 |
+
"total_flos": 91033240862720.0,
|
| 8 |
+
"train_loss": 2.1809828016493054,
|
| 9 |
+
"train_runtime": 20.1377,
|
| 10 |
+
"train_samples_per_second": 0.894,
|
| 11 |
+
"train_steps_per_second": 0.447
|
| 12 |
+
}
|
configuration.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"framework": "pytorch", "task": "text-generation", "allow_remote": true}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 1.804765224456787,
|
| 4 |
+
"eval_runtime": 0.0629,
|
| 5 |
+
"eval_samples_per_second": 31.789,
|
| 6 |
+
"eval_steps_per_second": 15.894
|
| 7 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
runs/Sep18_15-21-27_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644108.dsw-83959-79687bc578-gqp55.2469751.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f742eeb35560adcef92ef085ecc9403cd9078760cc69aefae9de517cbf0489d
|
| 3 |
+
size 8050
|
runs/Sep18_15-21-27_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644152.dsw-83959-79687bc578-gqp55.2469751.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7e54050071141643ad080774fae191ca9d1e32738e553a3b8d37e3e59dd9172
|
| 3 |
+
size 354
|
runs/Sep18_15-27-00_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644432.dsw-83959-79687bc578-gqp55.2473061.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ef8a8bd93bd66676ee6124df2cd088c168e2fc1c0602d25a21780b2b67f5363
|
| 3 |
+
size 8050
|
runs/Sep18_15-29-21_dsw-83959-79687bc578-gqp55/events.out.tfevents.1726644632.dsw-83959-79687bc578-gqp55.2474228.0
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e7b7f635a0ed07adda43f624deac5d44a76bb683b51a0443ce3f22c4dd259de
|
| 3 |
+
size 7997
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|eot_id|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"151646": {
|
| 29 |
+
"content": "<|eot_id|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
}
|
| 36 |
+
},
|
| 37 |
+
"additional_special_tokens": [
|
| 38 |
+
"<|im_start|>",
|
| 39 |
+
"<|im_end|>"
|
| 40 |
+
],
|
| 41 |
+
"bos_token": null,
|
| 42 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% endif %}{% if system_message is defined %}{{ '<|start_header_id|>system<|end_header_id|>\n\n' + system_message + '<|eot_id|>' }}{% endif %}{% for message in loop_messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|start_header_id|>user<|end_header_id|>\n\n' + content + '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|eot_id|>' }}{% endif %}{% endfor %}",
|
| 43 |
+
"clean_up_tokenization_spaces": false,
|
| 44 |
+
"eos_token": "<|eot_id|>",
|
| 45 |
+
"errors": "replace",
|
| 46 |
+
"model_max_length": 32768,
|
| 47 |
+
"pad_token": "<|endoftext|>",
|
| 48 |
+
"padding_side": "right",
|
| 49 |
+
"split_special_tokens": false,
|
| 50 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 51 |
+
"unk_token": null
|
| 52 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 91033240862720.0,
|
| 4 |
+
"train_loss": 2.1809828016493054,
|
| 5 |
+
"train_runtime": 20.1377,
|
| 6 |
+
"train_samples_per_second": 0.894,
|
| 7 |
+
"train_steps_per_second": 0.447
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
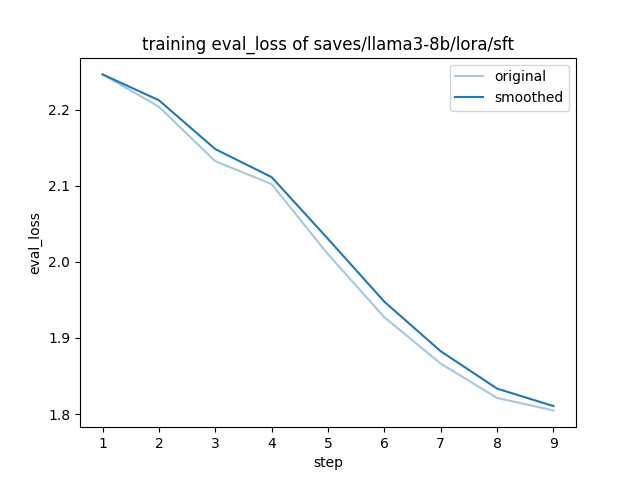
{"current_steps": 1, "total_steps": 9, "eval_loss": 2.526536226272583, "epoch": 0.1111111111111111, "percentage": 11.11, "elapsed_time": "0:00:00", "remaining_time": "0:00:07"}
|
| 2 |
+
{"current_steps": 2, "total_steps": 9, "eval_loss": 2.433619499206543, "epoch": 0.2222222222222222, "percentage": 22.22, "elapsed_time": "0:00:02", "remaining_time": "0:00:09"}
|
| 3 |
+
{"current_steps": 3, "total_steps": 9, "eval_loss": 2.3056671619415283, "epoch": 0.3333333333333333, "percentage": 33.33, "elapsed_time": "0:00:04", "remaining_time": "0:00:09"}
|
| 4 |
+
{"current_steps": 4, "total_steps": 9, "eval_loss": 2.2071735858917236, "epoch": 0.4444444444444444, "percentage": 44.44, "elapsed_time": "0:00:06", "remaining_time": "0:00:08"}
|
| 5 |
+
{"current_steps": 5, "total_steps": 9, "eval_loss": 2.137558698654175, "epoch": 0.5555555555555556, "percentage": 55.56, "elapsed_time": "0:00:08", "remaining_time": "0:00:06"}
|
| 6 |
+
{"current_steps": 6, "total_steps": 9, "eval_loss": 2.0649843215942383, "epoch": 0.6666666666666666, "percentage": 66.67, "elapsed_time": "0:00:10", "remaining_time": "0:00:05"}
|
| 7 |
+
{"current_steps": 7, "total_steps": 9, "eval_loss": 2.011927604675293, "epoch": 0.7777777777777778, "percentage": 77.78, "elapsed_time": "0:00:11", "remaining_time": "0:00:03"}
|
| 8 |
+
{"current_steps": 8, "total_steps": 9, "eval_loss": 1.9691121578216553, "epoch": 0.8888888888888888, "percentage": 88.89, "elapsed_time": "0:00:13", "remaining_time": "0:00:01"}
|
| 9 |
+
{"current_steps": 9, "total_steps": 9, "eval_loss": 1.9728047847747803, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "0:00:15", "remaining_time": "0:00:00"}
|
| 10 |
+
{"current_steps": 9, "total_steps": 9, "epoch": 1.0, "percentage": 100.0, "elapsed_time": "0:00:17", "remaining_time": "0:00:00"}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 1.0,
|
| 5 |
+
"eval_steps": 1,
|
| 6 |
+
"global_step": 9,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.1111111111111111,
|
| 13 |
+
"eval_loss": 2.2465293407440186,
|
| 14 |
+
"eval_runtime": 0.0671,
|
| 15 |
+
"eval_samples_per_second": 29.82,
|
| 16 |
+
"eval_steps_per_second": 14.91,
|
| 17 |
+
"step": 1
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 0.2222222222222222,
|
| 21 |
+
"eval_loss": 2.2040328979492188,
|
| 22 |
+
"eval_runtime": 0.0606,
|
| 23 |
+
"eval_samples_per_second": 33.007,
|
| 24 |
+
"eval_steps_per_second": 16.504,
|
| 25 |
+
"step": 2
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"epoch": 0.3333333333333333,
|
| 29 |
+
"eval_loss": 2.1323795318603516,
|
| 30 |
+
"eval_runtime": 0.096,
|
| 31 |
+
"eval_samples_per_second": 20.823,
|
| 32 |
+
"eval_steps_per_second": 10.411,
|
| 33 |
+
"step": 3
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 0.4444444444444444,
|
| 37 |
+
"eval_loss": 2.1022720336914062,
|
| 38 |
+
"eval_runtime": 0.0809,
|
| 39 |
+
"eval_samples_per_second": 24.732,
|
| 40 |
+
"eval_steps_per_second": 12.366,
|
| 41 |
+
"step": 4
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"epoch": 0.5555555555555556,
|
| 45 |
+
"eval_loss": 2.0100858211517334,
|
| 46 |
+
"eval_runtime": 0.0733,
|
| 47 |
+
"eval_samples_per_second": 27.273,
|
| 48 |
+
"eval_steps_per_second": 13.637,
|
| 49 |
+
"step": 5
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"epoch": 0.6666666666666666,
|
| 53 |
+
"eval_loss": 1.9271330833435059,
|
| 54 |
+
"eval_runtime": 0.0642,
|
| 55 |
+
"eval_samples_per_second": 31.137,
|
| 56 |
+
"eval_steps_per_second": 15.569,
|
| 57 |
+
"step": 6
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"epoch": 0.7777777777777778,
|
| 61 |
+
"eval_loss": 1.8663313388824463,
|
| 62 |
+
"eval_runtime": 0.0621,
|
| 63 |
+
"eval_samples_per_second": 32.192,
|
| 64 |
+
"eval_steps_per_second": 16.096,
|
| 65 |
+
"step": 7
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 0.8888888888888888,
|
| 69 |
+
"eval_loss": 1.8211396932601929,
|
| 70 |
+
"eval_runtime": 0.0608,
|
| 71 |
+
"eval_samples_per_second": 32.918,
|
| 72 |
+
"eval_steps_per_second": 16.459,
|
| 73 |
+
"step": 8
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 1.0,
|
| 77 |
+
"eval_loss": 1.804765224456787,
|
| 78 |
+
"eval_runtime": 0.0612,
|
| 79 |
+
"eval_samples_per_second": 32.679,
|
| 80 |
+
"eval_steps_per_second": 16.34,
|
| 81 |
+
"step": 9
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"epoch": 1.0,
|
| 85 |
+
"step": 9,
|
| 86 |
+
"total_flos": 91033240862720.0,
|
| 87 |
+
"train_loss": 2.1809828016493054,
|
| 88 |
+
"train_runtime": 20.1377,
|
| 89 |
+
"train_samples_per_second": 0.894,
|
| 90 |
+
"train_steps_per_second": 0.447
|
| 91 |
+
}
|
| 92 |
+
],
|
| 93 |
+
"logging_steps": 10,
|
| 94 |
+
"max_steps": 9,
|
| 95 |
+
"num_input_tokens_seen": 0,
|
| 96 |
+
"num_train_epochs": 1,
|
| 97 |
+
"save_steps": 1,
|
| 98 |
+
"stateful_callbacks": {
|
| 99 |
+
"TrainerControl": {
|
| 100 |
+
"args": {
|
| 101 |
+
"should_epoch_stop": false,
|
| 102 |
+
"should_evaluate": false,
|
| 103 |
+
"should_log": false,
|
| 104 |
+
"should_save": true,
|
| 105 |
+
"should_training_stop": true
|
| 106 |
+
},
|
| 107 |
+
"attributes": {}
|
| 108 |
+
}
|
| 109 |
+
},
|
| 110 |
+
"total_flos": 91033240862720.0,
|
| 111 |
+
"train_batch_size": 1,
|
| 112 |
+
"trial_name": null,
|
| 113 |
+
"trial_params": null
|
| 114 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d35adc3f09f1e82e58f5cfe7b47643b1e03f055a66610eace7d84c1320c474d1
|
| 3 |
+
size 5432
|
training_eval_loss.png
ADDED
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|