

minor update
Browse files- README-cn.md +1 -1
- README.md +1 -1
README-cn.md
CHANGED
|
@@ -98,7 +98,7 @@ MiniCPM5-1B 的训练过程是 **[UltraData 分级数据管理体系](https://ar
|
|
| 98 |
|
| 99 |
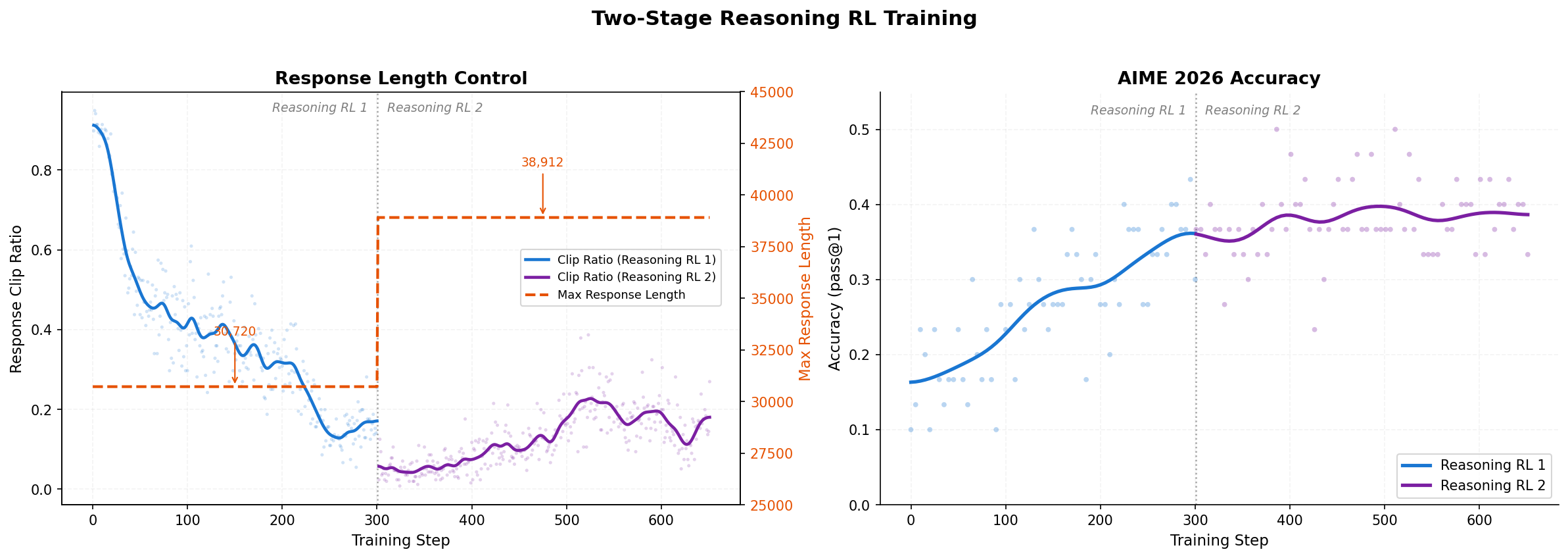
**RL + OPD** 是 MiniCPM5-1B 后训练中的关键环节。在数学、代码、指令跟随三类任务上,RL + OPD 将平均分提升 **↑16 分**,同时将回复触顶 max-tokens 预算的比例降低 **↓29 个百分点**。下方图示展示 Reasoning RL 两阶段流程、分数提升和超长率下降。
|
| 100 |
|
| 101 |
-
**RL** 阶段组合了多类互补训练信号。Reasoning RL
|
| 102 |
|
| 103 |
|
| 104 |
|
|
|
|
| 98 |
|
| 99 |
**RL + OPD** 是 MiniCPM5-1B 后训练中的关键环节。在数学、代码、指令跟随三类任务上,RL + OPD 将平均分提升 **↑16 分**,同时将回复触顶 max-tokens 预算的比例降低 **↓29 个百分点**。下方图示展示 Reasoning RL 两阶段流程、分数提升和超长率下降。
|
| 100 |
|
| 101 |
+
**RL** 阶段组合了推理、闭卷问答、写作、指令跟随、长上下文理解和通用对话等多类互补训练信号。Reasoning RL 基于 [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k) 采用两阶段长度调度,逐步降低超长率并提升推理准确率。我们还使用 [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa)、[NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open)、[LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData)、合成可验证 RLVR 数据与 pair-wise RLHF 信号,提升可靠性、指令跟随和用户体验。
|
| 102 |
|
| 103 |

|
| 104 |
|
README.md
CHANGED
|
@@ -98,7 +98,7 @@ During **post-training**, we proceed in three steps: **SFT**, **RL**, and **OPD*
|
|
| 98 |
|
| 99 |
**RL + OPD** is a key part of MiniCPM5-1B post-training. On math, code and instruction-following tasks, RL + OPD raises the average score by **↑16 points** while cutting the share of responses that hit the max-tokens budget by **↓29 percentage points**. The figures below show the two-stage Reasoning RL pipeline, score gains, and the drop in overlong responses.
|
| 100 |
|
| 101 |
-
**RL** combines
|
| 102 |
|
| 103 |

|
| 104 |
|
|
|
|
| 98 |
|
| 99 |
**RL + OPD** is a key part of MiniCPM5-1B post-training. On math, code and instruction-following tasks, RL + OPD raises the average score by **↑16 points** while cutting the share of responses that hit the max-tokens budget by **↓29 percentage points**. The figures below show the two-stage Reasoning RL pipeline, score gains, and the drop in overlong responses.
|
| 100 |
|
| 101 |
+
**RL** combines complementary training signals for reasoning, closed-book QA, writing, instruction following, long-context understanding, and general dialogue. Reasoning RL is based on [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k) and uses a two-stage length schedule to reduce overlong responses while improving reasoning accuracy. We also use [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa), [NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open), [LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData), synthesized verifiable RLVR data, and pair-wise RLHF signals to improve reliability, instruction following, and user experience.
|
| 102 |
|
| 103 |

|
| 104 |
|