

Add model card README
Browse files
README.md
CHANGED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
library_name: transformers
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
tags:
|
| 9 |
+
- minicpm
|
| 10 |
+
- minicpm5
|
| 11 |
+
- llama
|
| 12 |
+
- text-generation
|
| 13 |
+
- long-context
|
| 14 |
+
- tool-calling
|
| 15 |
+
- on-device
|
| 16 |
+
- edge-ai
|
| 17 |
+
datasets:
|
| 18 |
+
- openbmb/Ultra-FineWeb-L3
|
| 19 |
+
- openbmb/UltraData-SFT-2605
|
| 20 |
+
---
|
| 21 |
+
|
| 22 |
+
<div align="center">
|
| 23 |
+
<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/minicpm5/assets/minicpm_logo.png" width="500em" />
|
| 24 |
+
</div>
|
| 25 |
+
|
| 26 |
+
<p align="center">
|
| 27 |
+
<a href="https://arxiv.org/pdf/2506.07900" target="_blank">MiniCPM Paper</a> |
|
| 28 |
+
<a href="https://github.com/OpenBMB/MiniCPM/tree/minicpm5" target="_blank">GitHub Repo</a> |
|
| 29 |
+
<a href="https://huggingface.co/openbmb/MiniCPM5-1B/blob/main/README-cn.md" target="_blank">中文</a> |
|
| 30 |
+
<a href="https://ultradata.openbmb.cn/" target="_blank">UltraData</a> |
|
| 31 |
+
<a href="https://github.com/OpenBMB/MiniCPM-Desk-Pet" target="_blank">MiniCPM Desk Pet</a>
|
| 32 |
+
</p>
|
| 33 |
+
|
| 34 |
+
> This model card is shared across the **MiniCPM5-1B family** (final release, SFT-only, and base checkpoints, plus their GGUF / MLX / AWQ / GPTQ variants). The current model is marked in the [Model List](#model-list) below.
|
| 35 |
+
|
| 36 |
+
## Highlights
|
| 37 |
+
|
| 38 |
+
We are releasing **MiniCPM5-1B**, the first model in the **MiniCPM5** series. It is a dense 1B Transformer built for on-device, local deployment, and resource-constrained scenarios, reaching 1B-class open-source SOTA on public evaluations. The model uses the standard `LlamaForCausalLM` architecture, supports native 128K context, and is released in BF16, GGUF, MLX, AWQ, and GPTQ variants.
|
| 39 |
+
|
| 40 |
+
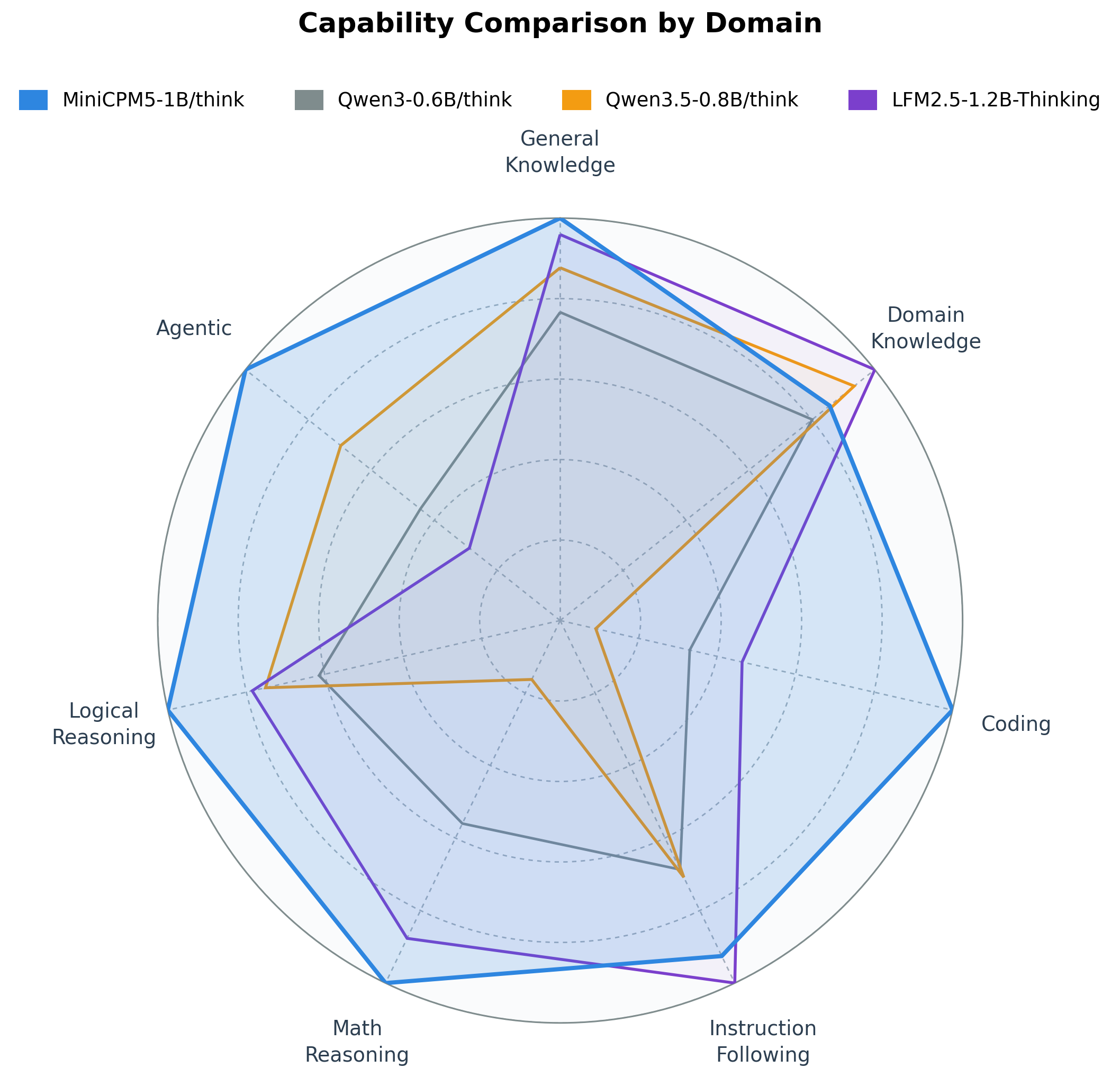
🏆 **1B-class open-source SOTA**: compared with strong open-source models in the same size class, MiniCPM5-1B reaches SOTA within this comparison set. Its advantage is most visible in agentic tool use, code generation, and difficult reasoning.
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
🧠 **Dual Mode Reasoning**: built-in `<think>` chat template, switch via `enable_thinking`. The same checkpoint serves as both a fast assistant and a deliberate reasoner.
|
| 45 |
+
|
| 46 |
+
🛠️ **Deployment / Fine-tuning Resources**: the MiniCPM GitHub repo provides single-page cookbooks and Agent Skills for major inference backends and fine-tuning frameworks.
|
| 47 |
+
|
| 48 |
+
🐱 **Desktop Pet**: a local-LLM desktop pet driven by MiniCPM5-1B. Click the cover below to open the demo video.
|
| 49 |
+
|
| 50 |
+
[<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/minicpm5/assets/minicpm5/minicpm5_desktop_pet_cover.png" alt="MiniCPM Desk Pet" width="720">](https://github.com/OpenBMB/MiniCPM/raw/minicpm5/assets/minicpm5/minicpm5_desktop_pet_demo.mp4)
|
| 51 |
+
|
| 52 |
+
## Model List
|
| 53 |
+
|
| 54 |
+
Use this directory to choose the model format that matches your runtime:
|
| 55 |
+
|
| 56 |
+
- **[MiniCPM5-1B](https://huggingface.co/openbmb/MiniCPM5-1B)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B) · BF16 final release (post-trained with RL + OPD) **👈 you are here**
|
| 57 |
+
- **[MiniCPM5-1B-SFT](https://huggingface.co/openbmb/MiniCPM5-1B-SFT)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-SFT) · BF16 SFT-only checkpoint (before RL / OPD)
|
| 58 |
+
- **[MiniCPM5-1B-Base](https://huggingface.co/openbmb/MiniCPM5-1B-Base)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-Base) · BF16 base checkpoint (pre-training only)
|
| 59 |
+
- **[MiniCPM5-1B-GGUF](https://huggingface.co/openbmb/MiniCPM5-1B-GGUF)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-GGUF) · GGUF for llama.cpp / Ollama / LM Studio
|
| 60 |
+
- **[MiniCPM5-1B-MLX](https://huggingface.co/openbmb/MiniCPM5-1B-MLX)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-MLX) · MLX / 4bit for Apple Silicon
|
| 61 |
+
- **[MiniCPM5-1B-AWQ](https://huggingface.co/openbmb/MiniCPM5-1B-AWQ)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-AWQ) · AWQ-Marlin Int4 for vLLM
|
| 62 |
+
- **[MiniCPM5-1B-GPTQ](https://huggingface.co/openbmb/MiniCPM5-1B-GPTQ)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-GPTQ) · GPTQ-Marlin Int4 for vLLM
|
| 63 |
+
|
| 64 |
+
## Model Information
|
| 65 |
+
|
| 66 |
+
| Item | Description |
|
| 67 |
+
| --- | --- |
|
| 68 |
+
| Model name | MiniCPM5-1B |
|
| 69 |
+
| Model type | Dense decoder-only language model |
|
| 70 |
+
| Architecture | Standard `LlamaForCausalLM` |
|
| 71 |
+
| Parameters | ~1.0B total parameters |
|
| 72 |
+
| Layers | 24 Transformer layers |
|
| 73 |
+
| Attention | GQA, 16 query heads / 2 KV heads |
|
| 74 |
+
| Context length | Native 128K context (`max_position_embeddings = 131,072`) |
|
| 75 |
+
| RoPE | `rope_theta = 5e6`, no extra RoPE scaling required |
|
| 76 |
+
| Chat modes | Think / No Think via `enable_thinking` |
|
| 77 |
+
| Main scenarios | Local assistants, coding agents, tool assistants, reasoning assistants, and resource-constrained deployment |
|
| 78 |
+
| License | Apache-2.0 |
|
| 79 |
+
|
| 80 |
+
## Introduction
|
| 81 |
+
|
| 82 |
+
MiniCPM5-1B is a compact dense decoder-only Transformer trained to improve output quality at the 1B scale. It keeps the standard `LlamaForCausalLM` architecture (24 layers, GQA 8:1, native 128K context, ~1.0B total params) so it runs on mainstream inference engines (Transformers, vLLM, SGLang, llama.cpp, MLX, Ollama, LM Studio) without custom kernels.
|
| 83 |
+
|
| 84 |
+
For full architecture details and per-component parameter breakdown, see the [Transformers deployment cookbook](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/transformers.md).
|
| 85 |
+
|
| 86 |
+
## Evaluation Results
|
| 87 |
+
|
| 88 |
+
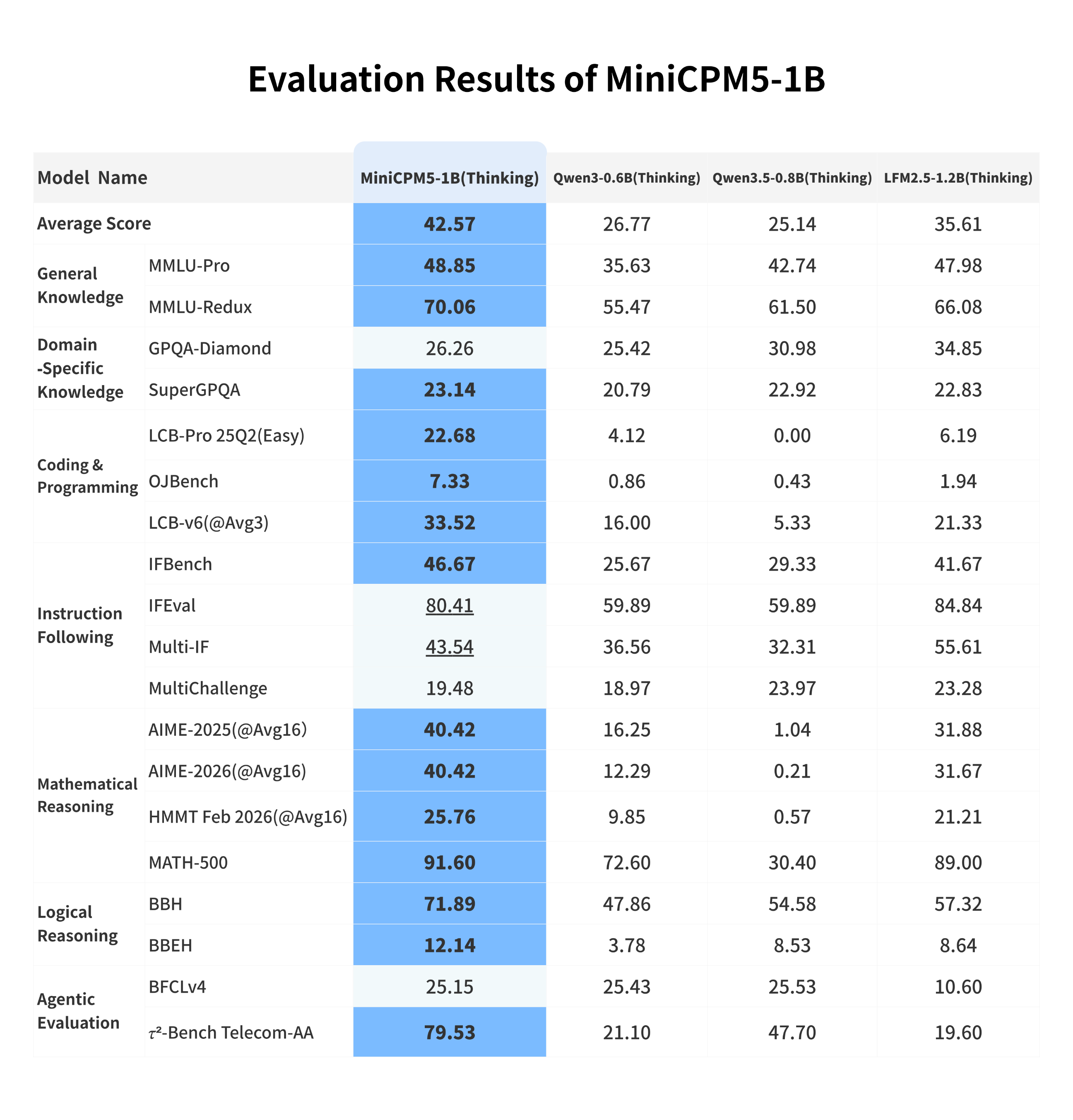
We compare MiniCPM5-1B with strong open-source models in the same size class, including **LFM2.5-1.2B-Thinking**, **Qwen3-0.6B/think** and **Qwen3.5-0.8B/think**. These are capable baselines; within this comparison set, MiniCPM5-1B reaches 1B-class open-source SOTA, with its advantage most visible in tool use, code generation, and difficult reasoning. This makes it a practical choice for local coding agents, tool assistants, and reasoning assistants.
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## Training Recipe
|
| 93 |
+
|
| 94 |
+
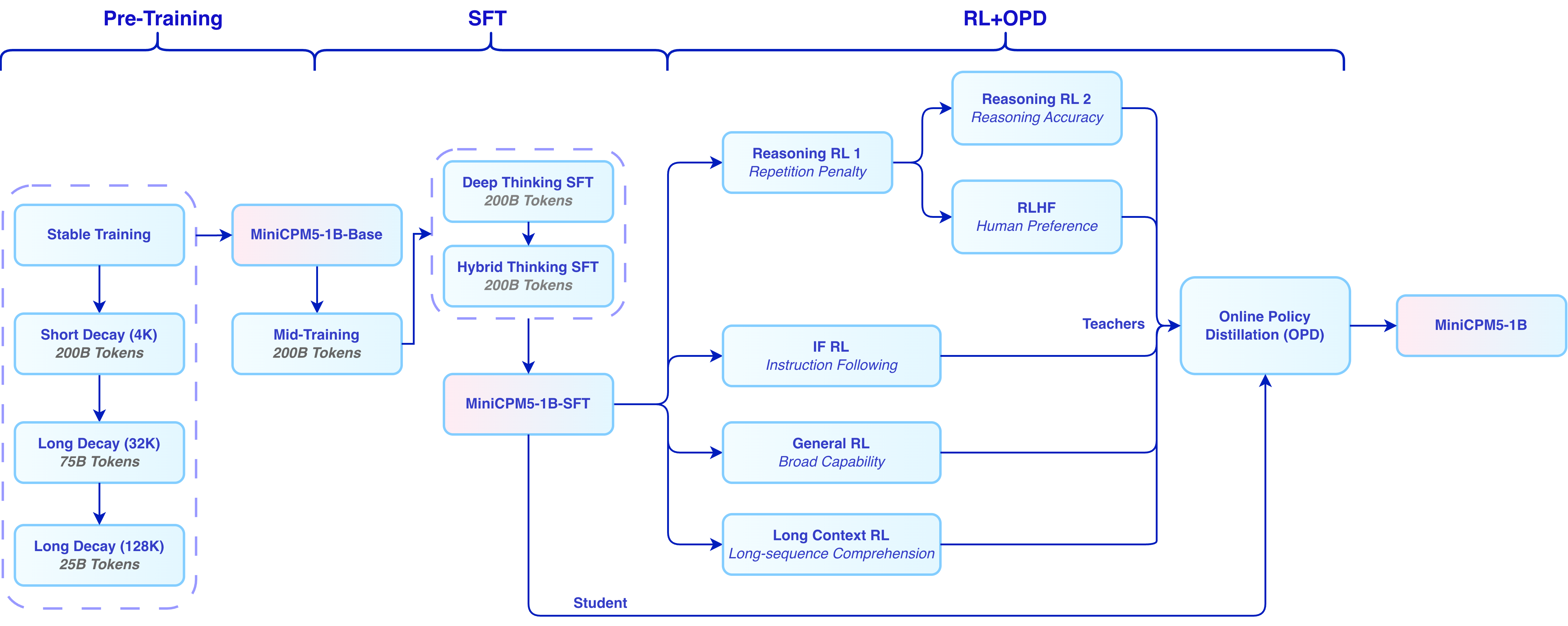
The training of MiniCPM5-1B is a full-stack practice of **[UltraData Tiered Data Management](https://ultradata.openbmb.cn/)**, covering three stages: base training, mid-training, and post-training.
|
| 95 |
+
|
| 96 |
+
During **base training**, the model goes through stable training and decay training to build core language capability and training stability. It then enters **mid-training** to further strengthen target capabilities and adapt to the target data distribution. The training corpus is released alongside the model as [Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3).
|
| 97 |
+
|
| 98 |
+
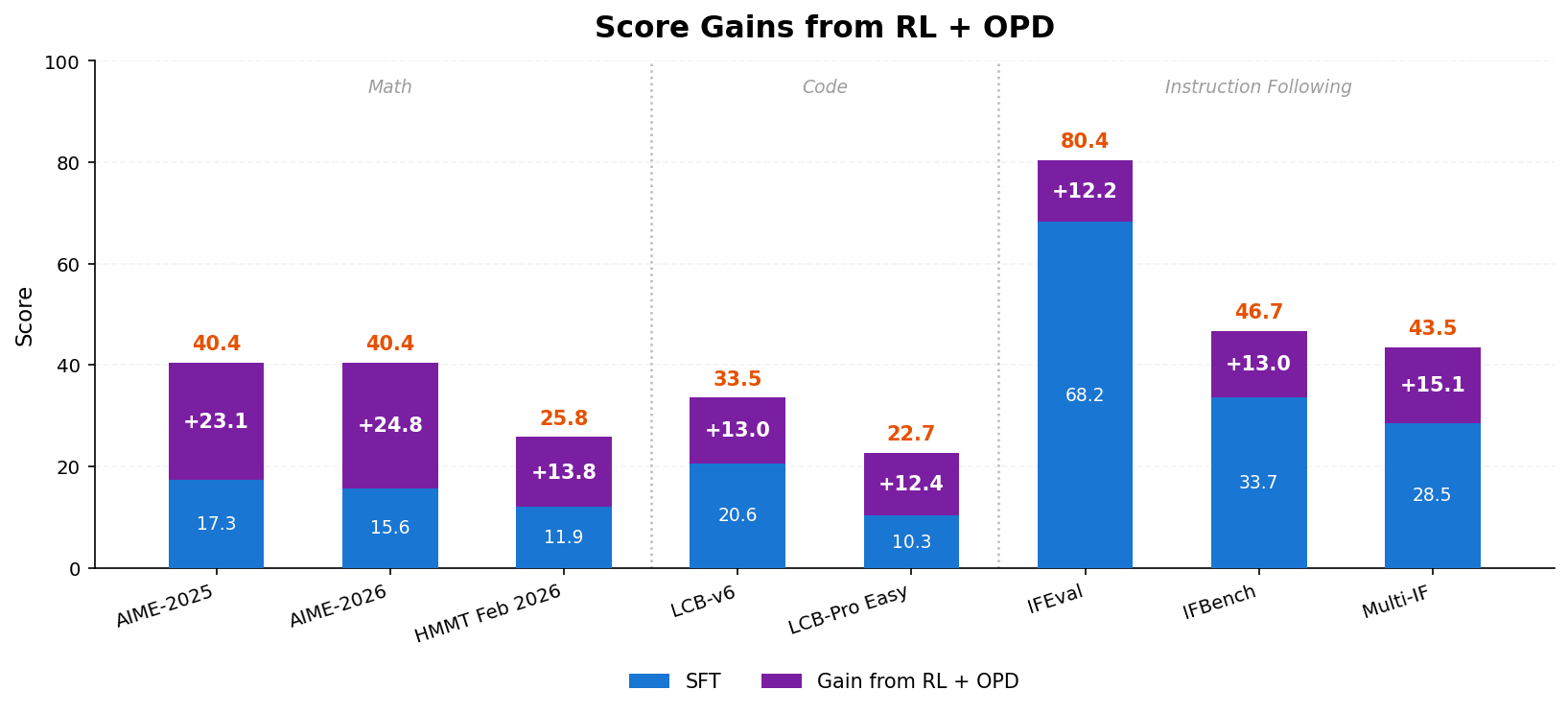
During **post-training**, we proceed in three steps: **SFT**, **RL**, and **OPD**. We first use **200B tokens of deep-thinking SFT** and **200B tokens of hybrid-thinking SFT** to establish deep-thinking, hybrid-thinking, and general chat abilities; the SFT data is released as [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605). We then train specialized **RL teachers** for math, code, closed-book QA, writing, and related domains, and use **On-Policy Distillation (OPD)** to distill these teachers back into one release model.
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
### What does RL + OPD bring?
|
| 103 |
+
|
| 104 |
+
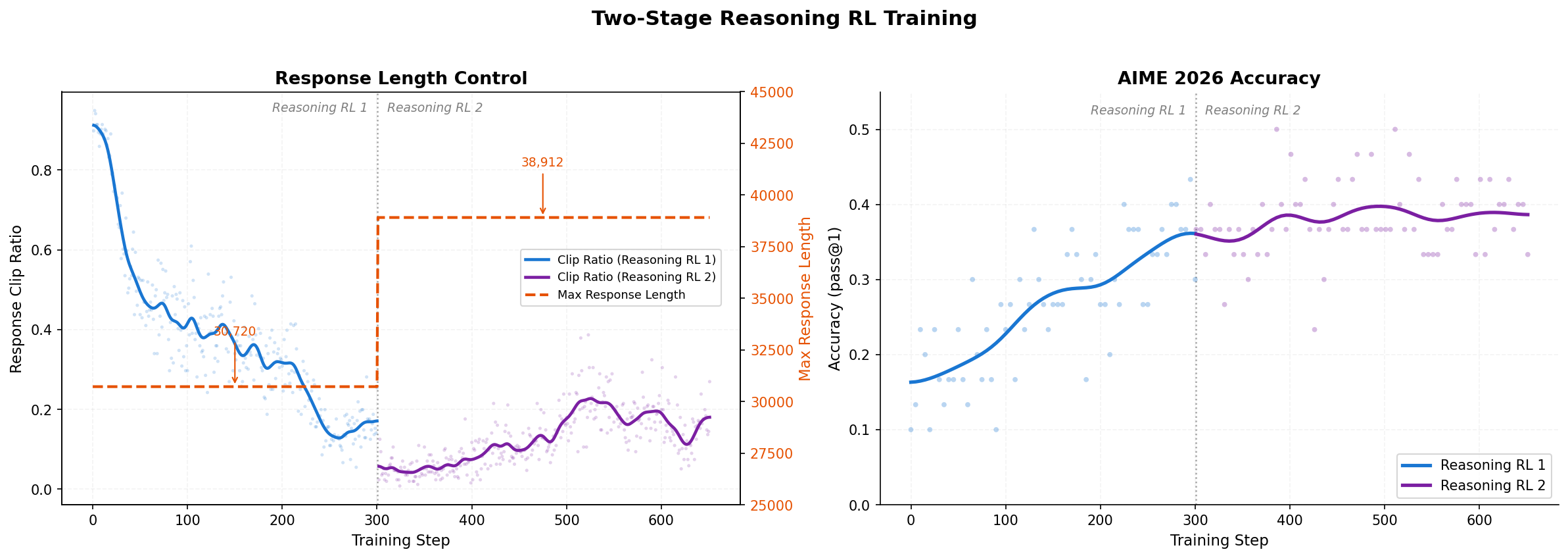
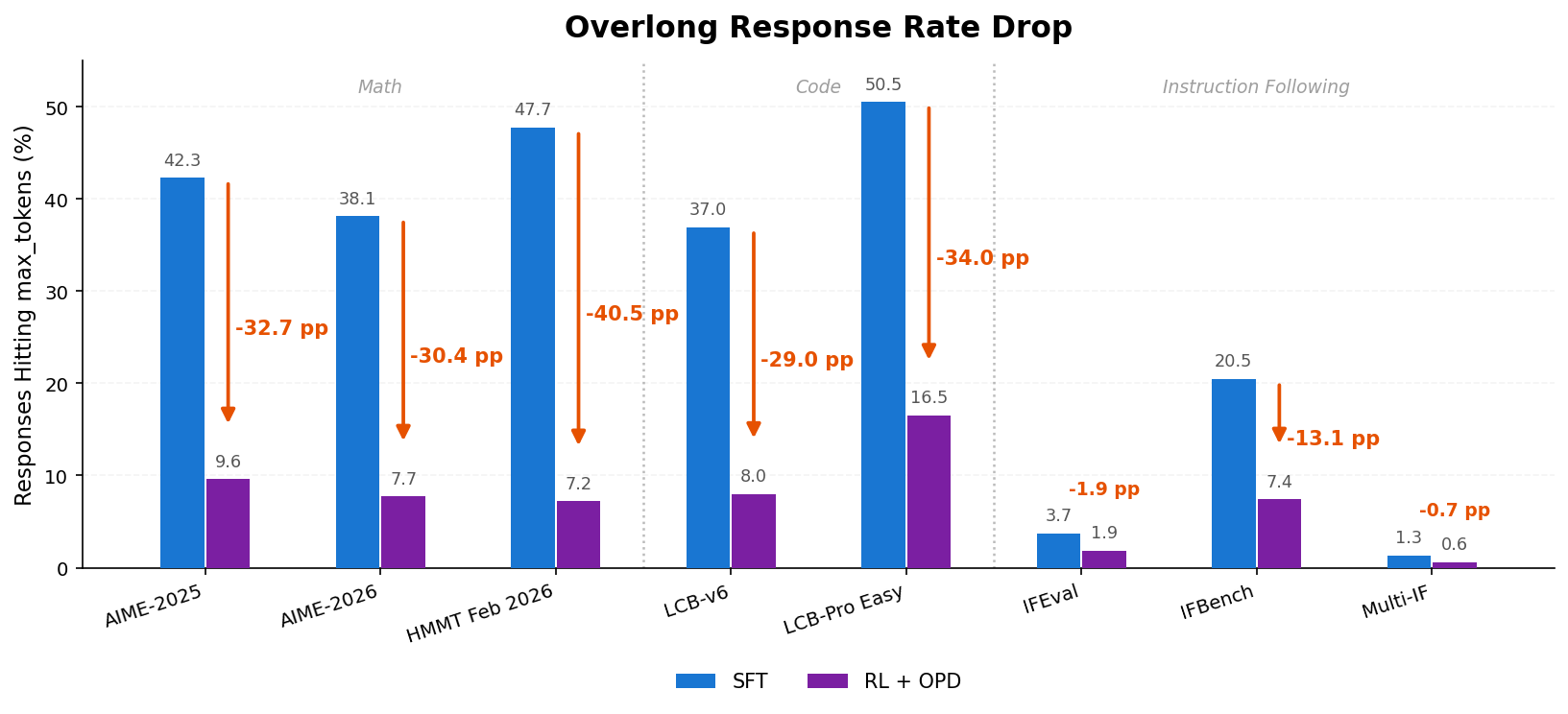
**RL + OPD** is a key part of MiniCPM5-1B post-training. On math, code and instruction-following tasks, RL + OPD raises the average score by **↑16 points** while cutting the share of responses that hit the max-tokens budget by **↓29 percentage points**. The figures below show the two-stage Reasoning RL pipeline, score gains, and the drop in overlong responses.
|
| 105 |
+
|
| 106 |
+
**RL** combines several complementary training signals. Reasoning RL uses [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k) to strengthen mathematical reasoning. Closed-book QA uses [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa) and [NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open), with a system prompt that encourages the model to acknowledge uncertainty instead of guessing. Writing is trained with [LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData); instruction following and long-context comprehension use verifiable RLVR data synthesized from general corpora. For general dialogue, we build pair-wise RLHF signals from anchor responses and use a Generative Reward Model for preference judgment.
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
**OPD** builds on Thinking Machines Lab's [On-Policy Distillation](https://thinkingmachines.ai/blog/on-policy-distillation/) and incorporates implementation improvements from [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016). In the RL framework, we use reverse KL divergence as the advantage estimate, replacing the original verification-based advantage. At each response position, we take top-k logits from both the student and teacher models, compute reverse KL on the union of the two token sets, and balance the accuracy of the RKL signal with training efficiency. OPD reuses the in-domain prompts used to train each RL teacher as distillation data, so no additional data curation is required.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## Quickstart
|
| 117 |
+
|
| 118 |
+
### vLLM
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
pip install "vllm>=0.21"
|
| 122 |
+
vllm serve openbmb/MiniCPM5-1B --port 8000
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
```bash
|
| 126 |
+
curl http://localhost:8000/v1/chat/completions \
|
| 127 |
+
-H "Content-Type: application/json" \
|
| 128 |
+
-d '{
|
| 129 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 130 |
+
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
|
| 131 |
+
"max_tokens": 128,
|
| 132 |
+
"temperature": 0.7
|
| 133 |
+
}'
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
### SGLang
|
| 137 |
+
|
| 138 |
+
```bash
|
| 139 |
+
pip install "sglang[srt]>=0.5.12"
|
| 140 |
+
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
curl http://localhost:30000/v1/chat/completions \
|
| 145 |
+
-H "Content-Type: application/json" \
|
| 146 |
+
-d '{
|
| 147 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 148 |
+
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
|
| 149 |
+
"max_tokens": 128,
|
| 150 |
+
"temperature": 0.7
|
| 151 |
+
}'
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
### Transformers
|
| 155 |
+
|
| 156 |
+
```bash
|
| 157 |
+
pip install -U "transformers>=5.6" accelerate torch
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
```python
|
| 161 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 162 |
+
|
| 163 |
+
model_id = "openbmb/MiniCPM5-1B"
|
| 164 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 165 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 166 |
+
model_id,
|
| 167 |
+
torch_dtype="auto",
|
| 168 |
+
device_map="auto",
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
messages = [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}]
|
| 172 |
+
inputs = tokenizer.apply_chat_template(
|
| 173 |
+
messages,
|
| 174 |
+
tokenize=True,
|
| 175 |
+
add_generation_prompt=True,
|
| 176 |
+
enable_thinking=False,
|
| 177 |
+
return_tensors="pt",
|
| 178 |
+
).to(model.device)
|
| 179 |
+
|
| 180 |
+
outputs = model.generate(inputs, max_new_tokens=128)
|
| 181 |
+
print(tokenizer.decode(outputs[0][inputs.shape[-1]:], skip_special_tokens=True))
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
Recommended chat template sampling:
|
| 185 |
+
|
| 186 |
+
| Mode | Recommended params | Enable |
|
| 187 |
+
| --- | --- | --- |
|
| 188 |
+
| **Think** | `temperature=0.9, top_p=0.95` | `enable_thinking=True` |
|
| 189 |
+
| **No Think** | `temperature=0.7, top_p=0.95` | `enable_thinking=False` |
|
| 190 |
+
|
| 191 |
+
## Tool Calling
|
| 192 |
+
|
| 193 |
+
For tool / function calling, **SGLang is the recommended backend**. MiniCPM5-1B emits XML-style tool calls and SGLang's built-in `minicpm5` parser converts them to OpenAI-compatible `tool_calls` natively:
|
| 194 |
+
|
| 195 |
+
```bash
|
| 196 |
+
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000 \
|
| 197 |
+
--tool-call-parser minicpm5 # or: --tool-call-parser auto
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
## GitHub Cookbooks and Agent Skills
|
| 201 |
+
|
| 202 |
+
MiniCPM5-1B uses the **standard `LlamaForCausalLM` architecture**, so mainstream inference engines can load it directly: **no custom kernels, no model-code fork**. For step-by-step deployment and fine-tuning instructions, use the GitHub cookbooks below. Agent Skills are linked as GitHub resources for users working with Cursor / Claude Code style coding agents.
|
| 203 |
+
|
| 204 |
+
| Backend / framework | Model format / use case | Cookbook | Agent Skill |
|
| 205 |
+
| --- | --- | --- | --- |
|
| 206 |
+
| Transformers | BF16 / FP16 local Python inference, GPU + CPU | [transformers.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/transformers.md) | [minicpm5-deploy-transformers](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-transformers/SKILL.md) |
|
| 207 |
+
| vLLM | BF16 / FP16 OpenAI server; supports AWQ / GPTQ-Marlin Int4 quantized weights | [vllm.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/vllm.md); quantized: [awq.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/awq.md) / [gptq.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/gptq.md) | [minicpm5-deploy-vllm](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-vllm/SKILL.md); quantized: [awq](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-awq/SKILL.md) / [gptq](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-gptq/SKILL.md) |
|
| 208 |
+
| SGLang | BF16 / FP16 OpenAI server, recommended for tool calling | [sglang.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/sglang.md) | [minicpm5-deploy-sglang](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-sglang/SKILL.md) |
|
| 209 |
+
| llama.cpp | GGUF local inference, CPU/GPU | [llama_cpp.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/llama_cpp.md) | [minicpm5-deploy-llama-cpp](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-llama-cpp/SKILL.md) |
|
| 210 |
+
| Ollama | GGUF local on-device runtime | [ollama.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/ollama.md) | [minicpm5-deploy-ollama](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-ollama/SKILL.md) |
|
| 211 |
+
| LM Studio | GGUF Mac desktop app and OpenAI server | [lmstudio.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/lmstudio.md) | [minicpm5-deploy-lmstudio](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-lmstudio/SKILL.md) |
|
| 212 |
+
| MLX | MLX / 4bit local inference on Apple Silicon | [mlx.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/deployment/mlx.md) | [minicpm5-deploy-mlx](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-deploy-mlx/SKILL.md) |
|
| 213 |
+
| TRL + PEFT | LoRA / SFT fine-tuning | [trl.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/finetune/trl.md) | [minicpm5-finetune-trl](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-finetune-trl/SKILL.md) |
|
| 214 |
+
| LLaMA-Factory | Fine-tuning | [llamafactory.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/finetune/llamafactory.md) | [minicpm5-finetune-llamafactory](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-finetune-llamafactory/SKILL.md) |
|
| 215 |
+
| ms-swift | Fine-tuning | [ms_swift.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/finetune/ms_swift.md) | [minicpm5-finetune-ms-swift](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-finetune-ms-swift/SKILL.md) |
|
| 216 |
+
| unsloth | Fine-tuning | [unsloth.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/finetune/unsloth.md) | [minicpm5-finetune-unsloth](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-finetune-unsloth/SKILL.md) |
|
| 217 |
+
| xtuner | Fine-tuning | [xtuner.md](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/docs/finetune/xtuner.md) | [minicpm5-finetune-xtuner](https://github.com/OpenBMB/MiniCPM/blob/minicpm5/skills/minicpm5-finetune-xtuner/SKILL.md) |
|
| 218 |
+
|
| 219 |
+
## Desktop Pet
|
| 220 |
+
|
| 221 |
+
We also ship **[OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)**, a desktop pet driven locally by MiniCPM5-1B. It supports Apple Silicon / NVIDIA GPU / CPU paths, can work with coding agents such as Cursor, Claude Code, and Codex, and supports LoRA persona switching.
|
| 222 |
+
|
| 223 |
+
## Limitations and Responsible Use
|
| 224 |
+
|
| 225 |
+
MiniCPM5-1B is a language model that generates content based on learned statistical patterns from training data. It may produce inaccurate, biased, or unsafe outputs, and generated content should be reviewed and verified before use in high-stakes settings.
|
| 226 |
+
|
| 227 |
+
Users are responsible for evaluating outputs, applying appropriate safeguards, and complying with applicable laws, regulations, and platform policies.
|
| 228 |
+
|
| 229 |
+
## License
|
| 230 |
+
|
| 231 |
+
This repository and MiniCPM model weights are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
|
| 232 |
+
|
| 233 |
+
## Citation
|
| 234 |
+
|
| 235 |
+
Please cite our paper if you find our work valuable:
|
| 236 |
+
|
| 237 |
+
```bibtex
|
| 238 |
+
@article{minicpm4,
|
| 239 |
+
title={Minicpm4: Ultra-efficient llms on end devices},
|
| 240 |
+
author={MiniCPM, Team},
|
| 241 |
+
journal={arXiv preprint arXiv:2506.07900},
|
| 242 |
+
year={2025}
|
| 243 |
+
}
|
| 244 |
+
```
|