MiniCPM 论文 | GitHub 仓库 | English | UltraData | MiniCPM 桌宠
> 本仓库托管 **MiniCPM5-1B** 的 GGUF(llama.cpp)版本,包括 **F16**、**Q8_0** 和 **Q4_K_M** 三种精度。BF16 Hugging Face 权重与完整模型卡请参考 [MiniCPM5-1B](https://huggingface.co/openbmb/MiniCPM5-1B)。 ## 亮点 我们正式发布 **MiniCPM5-1B**,这是 **MiniCPM5** 系列的首个模型。它是一款面向端侧、本地部署和资源受限场景的 1B 稠密 Transformer,在基准评测中达到同尺寸开源模型 SOTA 水平。 🏆 **同尺寸开源模型 SOTA**:与同尺寸优秀开源模型相比,MiniCPM5-1B 在该对比范围内达到 SOTA 水平,优势主要体现在 Agentic 工具调用、代码生成和高难推理。 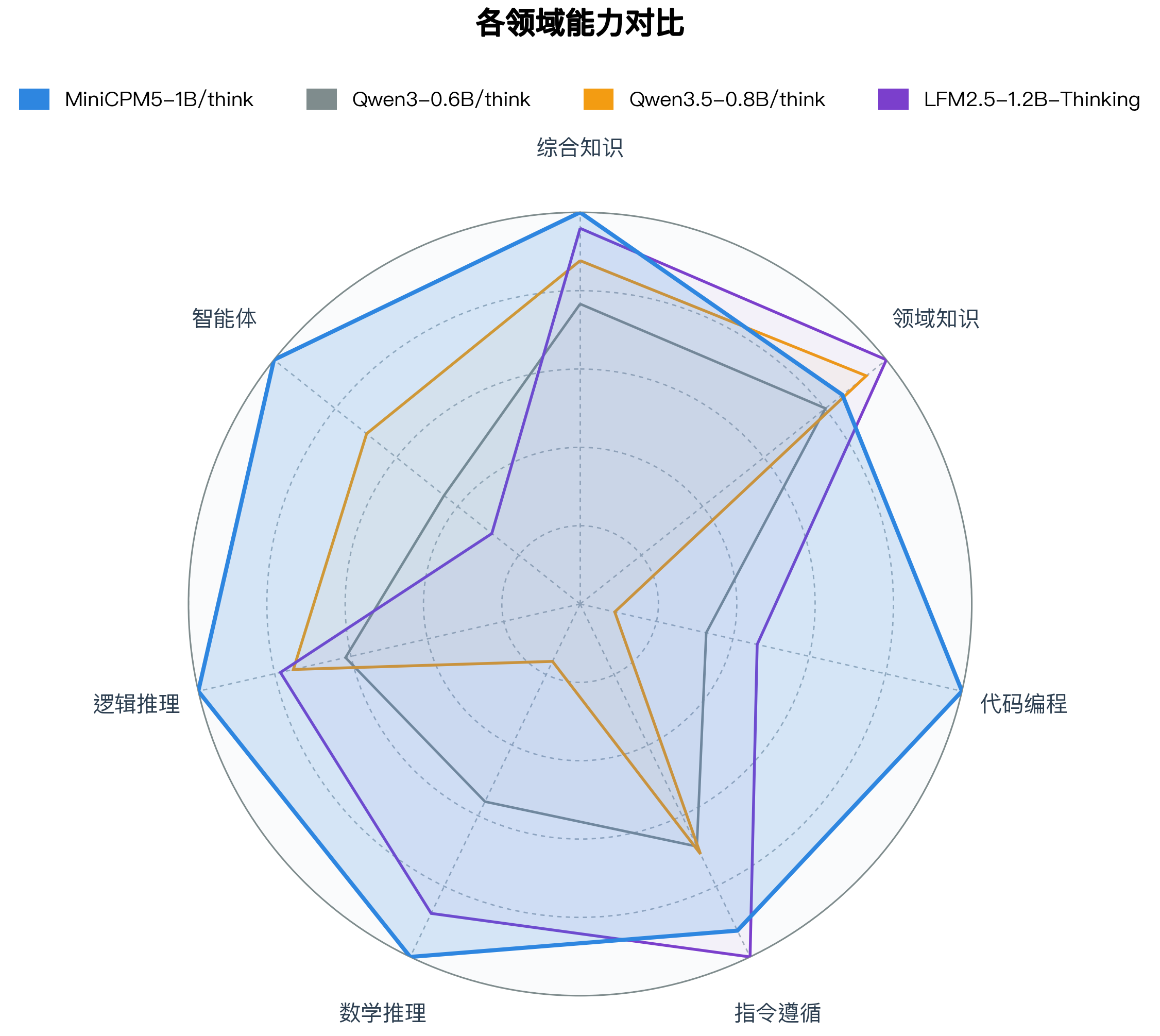 🧠 **双模式推理**:内置 ` **项目仓库**: [OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)
## 模型列表
你可以按运行环境选择对应模型格式:
- **[MiniCPM5-1B](https://huggingface.co/openbmb/MiniCPM5-1B)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B) · BF16 正式版(经 RL + OPD 后训练)
- **[MiniCPM5-1B-SFT](https://huggingface.co/openbmb/MiniCPM5-1B-SFT)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-SFT) · BF16 SFT 单独 checkpoint(RL / OPD 之前)
- **[MiniCPM5-1B-Base](https://huggingface.co/openbmb/MiniCPM5-1B-Base)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-Base) · BF16 base checkpoint(仅预训练)
- **[MiniCPM5-1B-GGUF](https://huggingface.co/openbmb/MiniCPM5-1B-GGUF)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-GGUF) · GGUF,适用于 llama.cpp / Ollama / LM Studio **👈 当前页面**
- **[MiniCPM5-1B-MLX](https://huggingface.co/openbmb/MiniCPM5-1B-MLX)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-MLX) · MLX / 4bit,适用于 Apple Silicon
## 模型信息
MiniCPM5-1B 具有以下特性:
- **类型**:Causal Language Model
- **架构**:标准 `LlamaForCausalLM`
- **Number of Parameters**: 1,080,632,832
- **Number of Non-Embedding Parameters**: 679,552,512
- **层数**:24
- **注意力头(GQA)**:16 个 Q heads / 2 个 KV heads
- **上下文长度**:131,072
## 简介
MiniCPM5-1B 是 MiniCPM5 系列的首个模型,面向本地助手、coding agent、工具调用流程以及需要紧凑模型的推理场景。它在较小部署成本下提供原生长上下文能力,并通过同一份权重支持 Think / No Think 两种对话模式。
## 评测结果
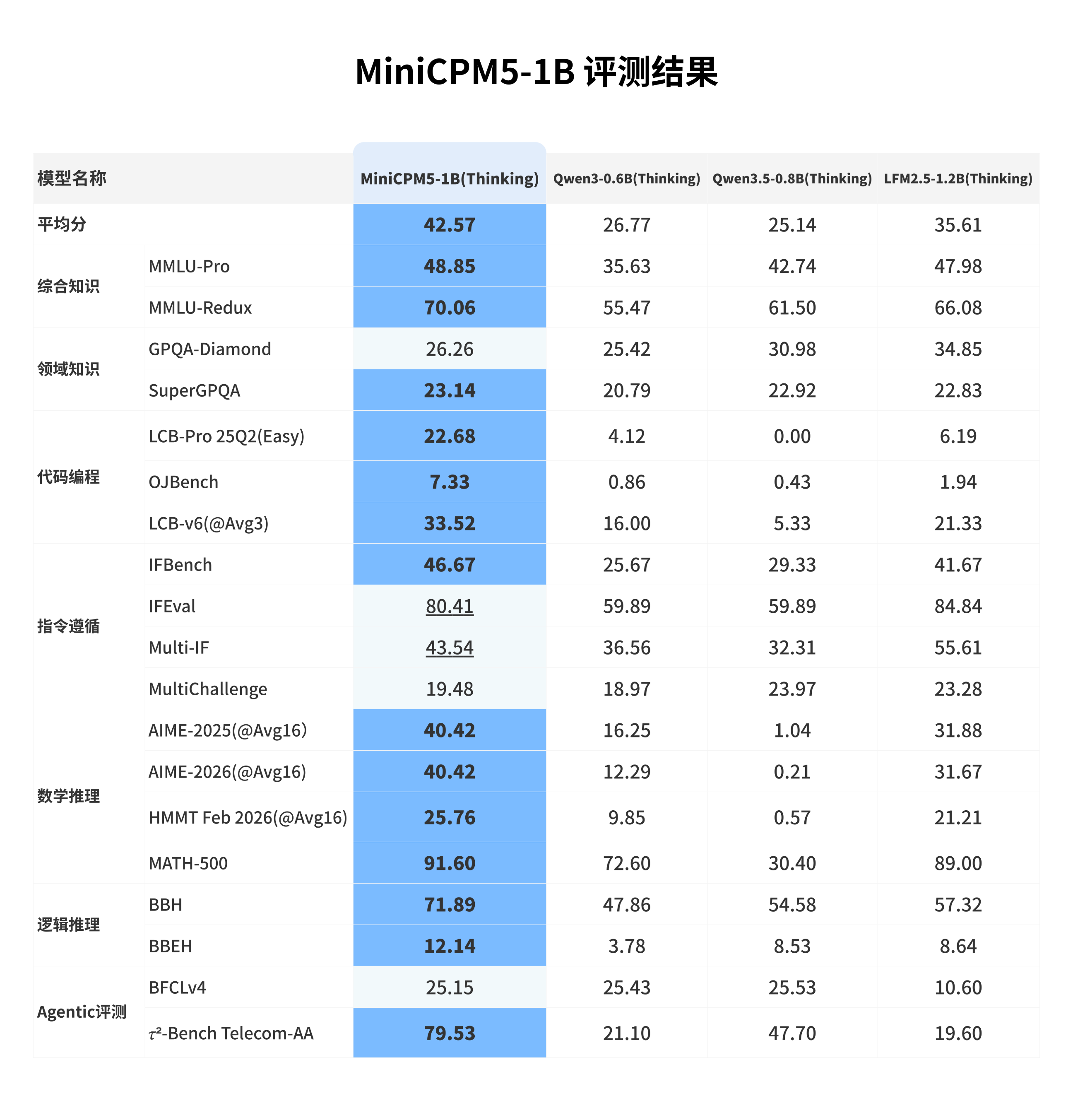
我们选取 **LFM2.5-1.2B-Thinking**、**Qwen3-0.6B/think**、**Qwen3.5-0.8B/think** 等同尺寸优秀开源模型进行横向比较。这些模型本身已经很强;在这组对比中,MiniCPM5-1B 达到同尺寸开源模型 SOTA 水平,优势主要体现在工具调用、代码生成和高难推理上,也更适合承担本地 coding agent、工具助手和推理助手的角色。
## 训练流程
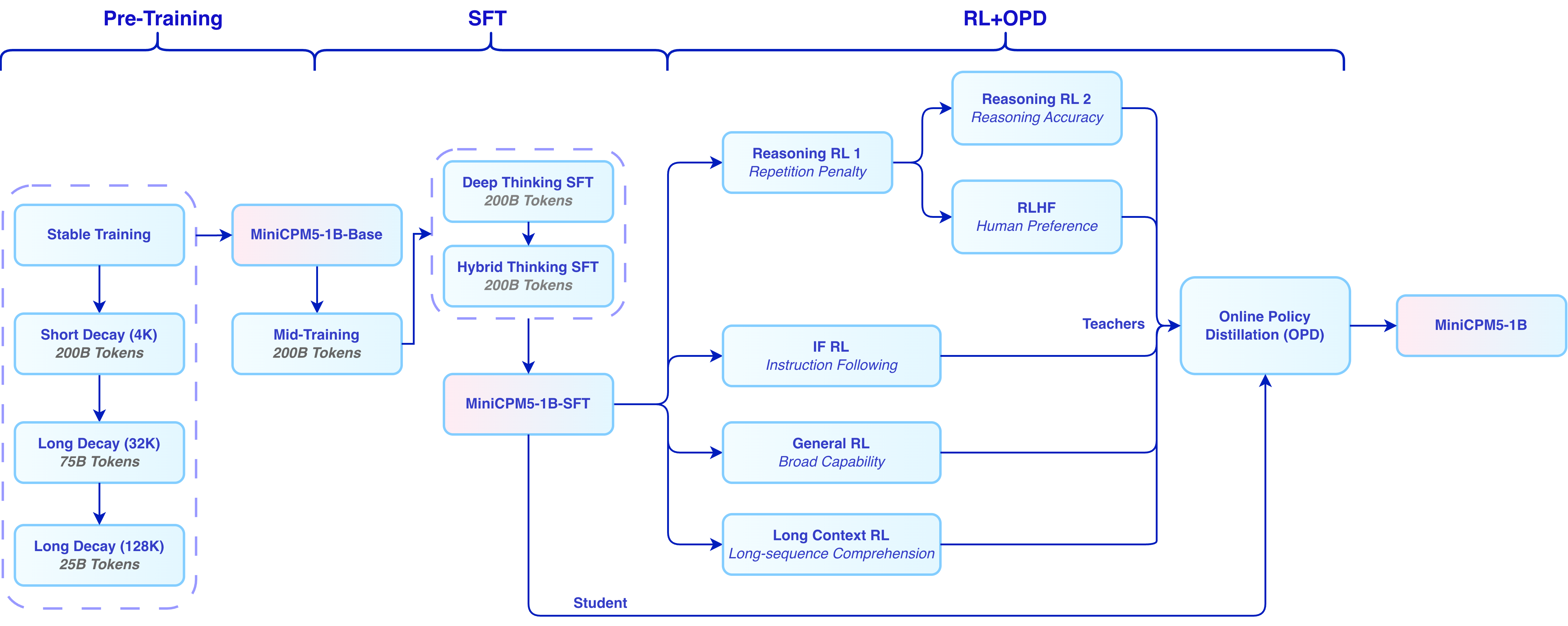
MiniCPM5-1B 的训练过程是 **[UltraData 分级数据管理体系](https://ultradata.openbmb.cn/)** 的一次完整实践,覆盖 base training、mid-training 与后训练三个阶段。
**Base training** 采用逐级推进的训练配方,包含 stable training 与 decay training,用于建立基础语言能力与训练稳定性。随后进入 **mid-training**,进一步强化目标能力并适配数据分布。训练语料来自我们同步开源的 [Ultra-FineWeb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb)、[Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3) 与 [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math)。
**后训练阶段**分为 **SFT**、**RL** 与 **OPD** 三步。我们先使用 **200B tokens deep-thinking SFT** 与 **200B tokens hybrid-thinking SFT** 建立深度思考、混合思考和通用对话能力,相关 SFT 数据已同步开源为 [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605)。随后针对数学、代码、闭卷问答和写作等方向训练专用 **RL teacher**,并通过 **On-Policy Distillation (OPD)** 将这些 teacher 的能力蒸馏回同一个发布模型。
### RL + OPD 带来了什么?
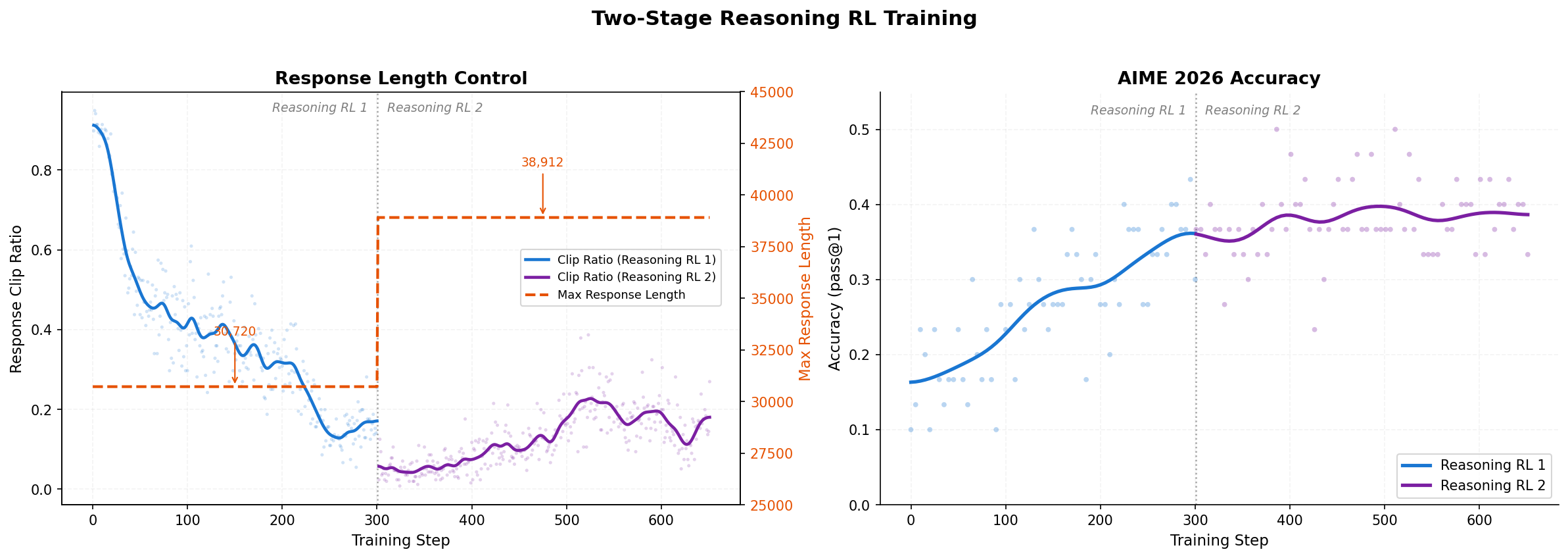
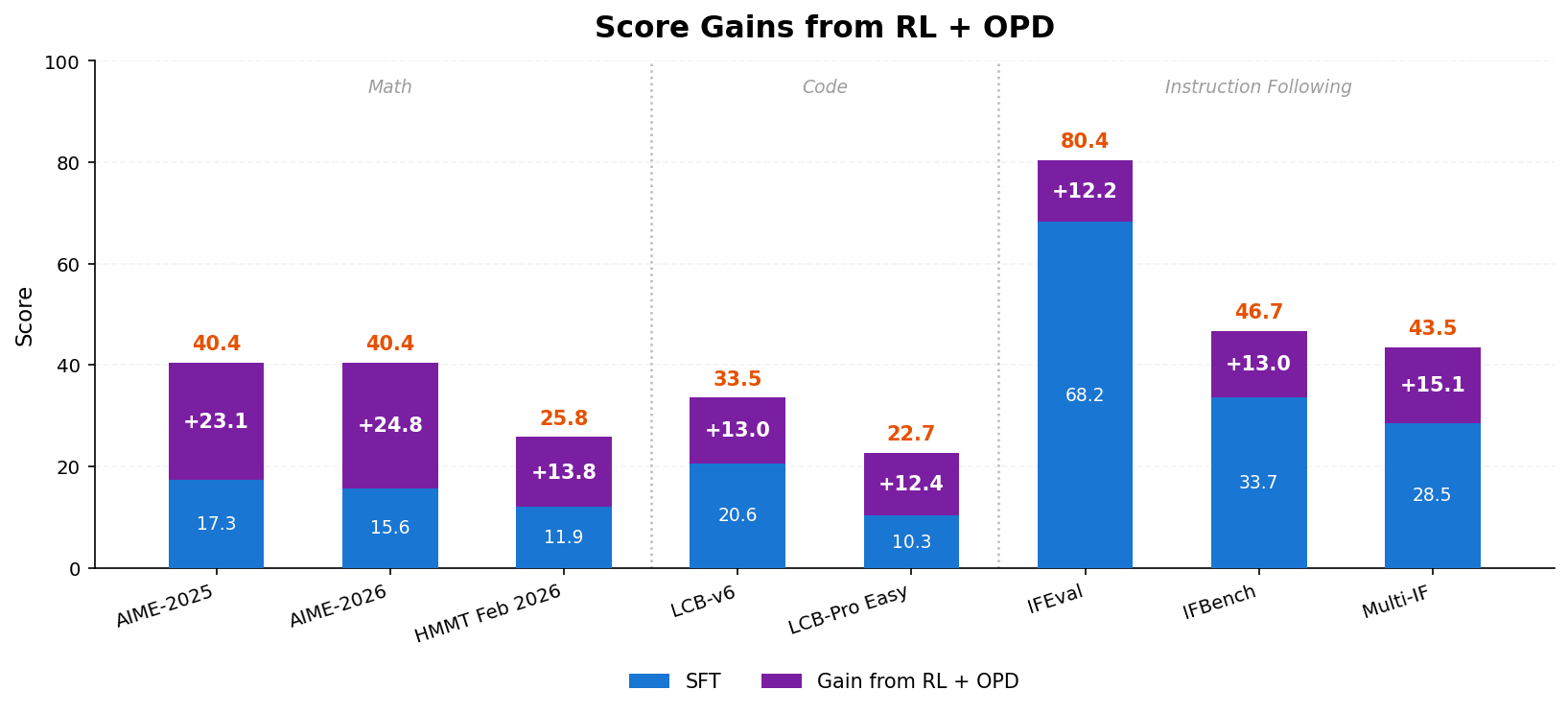
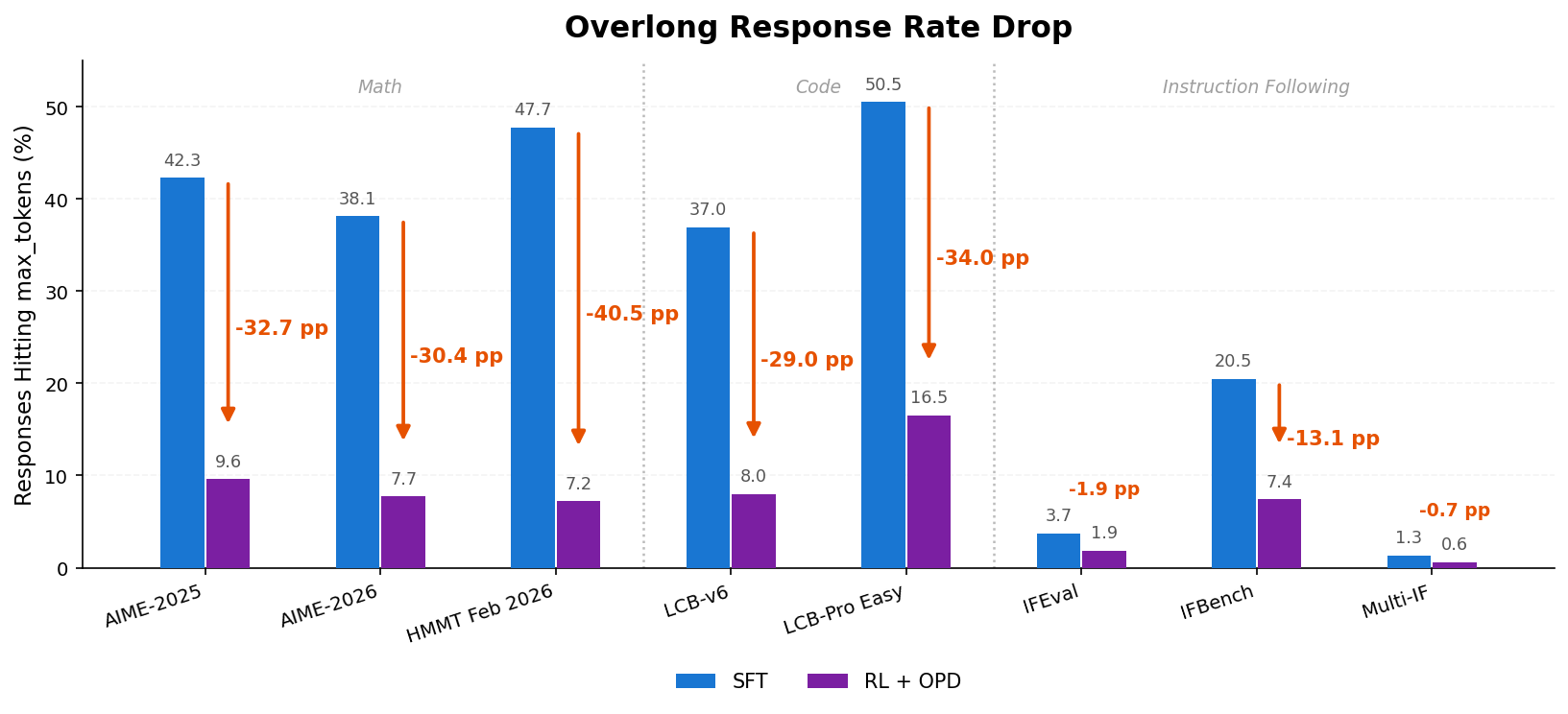
**RL + OPD** 是 MiniCPM5-1B 后训练中的关键环节。在数学、代码、指令跟随三类任务上,RL + OPD 将平均分提升 **↑16 分**,同时将回复触顶 max-tokens 预算的比例降低 **↓29 个百分点**。下方图示展示 Reasoning RL 两阶段流程、分数提升和超长率下降。
**RL** 阶段组合了多类互补训练信号。Reasoning RL 使用 [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k) 强化数学推理;闭卷问答使用 [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa) 和 [NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open),并通过系统提示引导模型在不确定时承认不知道,而不是随机猜测。写作能力来自 [LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData);指令跟随和长上下文理解则使用从通用语料合成的可验证 RLVR 数据。通用对话部分基于 anchor responses 构造 pair-wise RLHF 信号,由 Generative Reward Model 进行偏好判断。
**OPD** 阶段参考 Thinking Machines Lab 的 [On-Policy Distillation](https://thinkingmachines.ai/blog/on-policy-distillation/) 思路,并结合 [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016) 做了实现改进。我们在强化学习框架中使用反向 KL 散度作为优势估计值,替代原有的 verification-based advantage;同时在 response 序列的每个位置分别对学生模型和教师模型 logits 做双边 top-k 采样,取并集后计算反向 KL 散度,以平衡监督信号准确性和训练效率。OPD 直接复用各 RL teacher 训练时的同分布 prompt 作为蒸馏数据,无需额外构造语料。
## GGUF 文件
仓库提供 MiniCPM5-1B 0517 checkpoint 的三种量化版本。三个文件都可被原版 `llama.cpp` / `Ollama` / `LM Studio` / `llama-cpp-python` / `llama-server` 直接加载,**无需任何 patch**。
| 文件 | 大小 | 量化 | 推荐场景 |
| --- | ---: | --- | --- |
| `MiniCPM5-1B-Q4_K_M.gguf` | 657 MB | Q4_K_M | 笔记本 / 边缘设备(推荐起步) |
| `MiniCPM5-1B-Q8_0.gguf` | 1.1 GB | Q8_0 | 接近 F16 质量、磁盘更友好 |
| `MiniCPM5-1B-F16.gguf` | 2.1 GB | F16 | 参考精度,可作为二次量化的源 |
## 快速上手
### llama.cpp(CLI)
```bash
llama-cli -m MiniCPM5-1B-Q4_K_M.gguf -n 2048 --temp 0.7 --top-p 0.8 -c 8192
```
### llama.cpp(OpenAI 兼容 HTTP 服务)
```bash
llama-server -m MiniCPM5-1B-Q4_K_M.gguf --port 8080 -c 8192 --jinja
```
```bash
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "MiniCPM5-1B",
"messages": [{"role":"user","content":"你是谁?可以简单介绍一下自己吗?"}],
"temperature": 0.7,
"top_p": 0.8,
"max_tokens": 256
}'
```
### Ollama / LM Studio
Ollama 和 LM Studio 都可以直接导入这些 GGUF 文件——选择上面任一文件并指定模型名即可,GGUF 内嵌的 chat template 会被原生识别。
### Think / No-Think 控制
MiniCPM5-1B 是 thinking 模型,chat template 通过 `chat_template_kwargs` 暴露 `enable_thinking` 开关:
| 模式 | `chat_template_kwargs` | 行为 |
| --- | --- | --- |
| **自主**(默认) | 不传 | 模型自行判断是否进入 `
**项目仓库**: [OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)
## 模型列表
你可以按运行环境选择对应模型格式:
- **[MiniCPM5-1B](https://huggingface.co/openbmb/MiniCPM5-1B)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B) · BF16 正式版(经 RL + OPD 后训练)
- **[MiniCPM5-1B-SFT](https://huggingface.co/openbmb/MiniCPM5-1B-SFT)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-SFT) · BF16 SFT 单独 checkpoint(RL / OPD 之前)
- **[MiniCPM5-1B-Base](https://huggingface.co/openbmb/MiniCPM5-1B-Base)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-Base) · BF16 base checkpoint(仅预训练)
- **[MiniCPM5-1B-GGUF](https://huggingface.co/openbmb/MiniCPM5-1B-GGUF)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-GGUF) · GGUF,适用于 llama.cpp / Ollama / LM Studio **👈 当前页面**
- **[MiniCPM5-1B-MLX](https://huggingface.co/openbmb/MiniCPM5-1B-MLX)** · [ModelScope](https://www.modelscope.cn/models/OpenBMB/MiniCPM5-1B-MLX) · MLX / 4bit,适用于 Apple Silicon
## 模型信息
MiniCPM5-1B 具有以下特性:
- **类型**:Causal Language Model
- **架构**:标准 `LlamaForCausalLM`
- **Number of Parameters**: 1,080,632,832
- **Number of Non-Embedding Parameters**: 679,552,512
- **层数**:24
- **注意力头(GQA)**:16 个 Q heads / 2 个 KV heads
- **上下文长度**:131,072
## 简介
MiniCPM5-1B 是 MiniCPM5 系列的首个模型,面向本地助手、coding agent、工具调用流程以及需要紧凑模型的推理场景。它在较小部署成本下提供原生长上下文能力,并通过同一份权重支持 Think / No Think 两种对话模式。
## 评测结果
我们选取 **LFM2.5-1.2B-Thinking**、**Qwen3-0.6B/think**、**Qwen3.5-0.8B/think** 等同尺寸优秀开源模型进行横向比较。这些模型本身已经很强;在这组对比中,MiniCPM5-1B 达到同尺寸开源模型 SOTA 水平,优势主要体现在工具调用、代码生成和高难推理上,也更适合承担本地 coding agent、工具助手和推理助手的角色。

## 训练流程
MiniCPM5-1B 的训练过程是 **[UltraData 分级数据管理体系](https://ultradata.openbmb.cn/)** 的一次完整实践,覆盖 base training、mid-training 与后训练三个阶段。
**Base training** 采用逐级推进的训练配方,包含 stable training 与 decay training,用于建立基础语言能力与训练稳定性。随后进入 **mid-training**,进一步强化目标能力并适配数据分布。训练语料来自我们同步开源的 [Ultra-FineWeb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb)、[Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3) 与 [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math)。
**后训练阶段**分为 **SFT**、**RL** 与 **OPD** 三步。我们先使用 **200B tokens deep-thinking SFT** 与 **200B tokens hybrid-thinking SFT** 建立深度思考、混合思考和通用对话能力,相关 SFT 数据已同步开源为 [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605)。随后针对数学、代码、闭卷问答和写作等方向训练专用 **RL teacher**,并通过 **On-Policy Distillation (OPD)** 将这些 teacher 的能力蒸馏回同一个发布模型。

### RL + OPD 带来了什么?
**RL + OPD** 是 MiniCPM5-1B 后训练中的关键环节。在数学、代码、指令跟随三类任务上,RL + OPD 将平均分提升 **↑16 分**,同时将回复触顶 max-tokens 预算的比例降低 **↓29 个百分点**。下方图示展示 Reasoning RL 两阶段流程、分数提升和超长率下降。
**RL** 阶段组合了多类互补训练信号。Reasoning RL 使用 [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k) 强化数学推理;闭卷问答使用 [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa) 和 [NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open),并通过系统提示引导模型在不确定时承认不知道,而不是随机猜测。写作能力来自 [LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData);指令跟随和长上下文理解则使用从通用语料合成的可验证 RLVR 数据。通用对话部分基于 anchor responses 构造 pair-wise RLHF 信号,由 Generative Reward Model 进行偏好判断。

**OPD** 阶段参考 Thinking Machines Lab 的 [On-Policy Distillation](https://thinkingmachines.ai/blog/on-policy-distillation/) 思路,并结合 [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016) 做了实现改进。我们在强化学习框架中使用反向 KL 散度作为优势估计值,替代原有的 verification-based advantage;同时在 response 序列的每个位置分别对学生模型和教师模型 logits 做双边 top-k 采样,取并集后计算反向 KL 散度,以平衡监督信号准确性和训练效率。OPD 直接复用各 RL teacher 训练时的同分布 prompt 作为蒸馏数据,无需额外构造语料。


## GGUF 文件
仓库提供 MiniCPM5-1B 0517 checkpoint 的三种量化版本。三个文件都可被原版 `llama.cpp` / `Ollama` / `LM Studio` / `llama-cpp-python` / `llama-server` 直接加载,**无需任何 patch**。
| 文件 | 大小 | 量化 | 推荐场景 |
| --- | ---: | --- | --- |
| `MiniCPM5-1B-Q4_K_M.gguf` | 657 MB | Q4_K_M | 笔记本 / 边缘设备(推荐起步) |
| `MiniCPM5-1B-Q8_0.gguf` | 1.1 GB | Q8_0 | 接近 F16 质量、磁盘更友好 |
| `MiniCPM5-1B-F16.gguf` | 2.1 GB | F16 | 参考精度,可作为二次量化的源 |
## 快速上手
### llama.cpp(CLI)
```bash
llama-cli -m MiniCPM5-1B-Q4_K_M.gguf -n 2048 --temp 0.7 --top-p 0.8 -c 8192
```
### llama.cpp(OpenAI 兼容 HTTP 服务)
```bash
llama-server -m MiniCPM5-1B-Q4_K_M.gguf --port 8080 -c 8192 --jinja
```
```bash
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "MiniCPM5-1B",
"messages": [{"role":"user","content":"你是谁?可以简单介绍一下自己吗?"}],
"temperature": 0.7,
"top_p": 0.8,
"max_tokens": 256
}'
```
### Ollama / LM Studio
Ollama 和 LM Studio 都可以直接导入这些 GGUF 文件——选择上面任一文件并指定模型名即可,GGUF 内嵌的 chat template 会被原生识别。
### Think / No-Think 控制
MiniCPM5-1B 是 thinking 模型,chat template 通过 `chat_template_kwargs` 暴露 `enable_thinking` 开关:
| 模式 | `chat_template_kwargs` | 行为 |
| --- | --- | --- |
| **自主**(默认) | 不传 | 模型自行判断是否进入 `