

update README
Browse files- README-cn.md +189 -79
- README.md +186 -76
README-cn.md
CHANGED
|
@@ -3,10 +3,9 @@ license: apache-2.0
|
|
| 3 |
language:
|
| 4 |
- zh
|
| 5 |
- en
|
| 6 |
-
library_name:
|
| 7 |
pipeline_tag: text-generation
|
| 8 |
tags:
|
| 9 |
-
- gguf
|
| 10 |
- minicpm
|
| 11 |
- minicpm5
|
| 12 |
- llama
|
|
@@ -15,10 +14,6 @@ tags:
|
|
| 15 |
- tool-calling
|
| 16 |
- on-device
|
| 17 |
- edge-ai
|
| 18 |
-
- quantized
|
| 19 |
-
- llama-cpp
|
| 20 |
-
- ollama
|
| 21 |
-
- lm-studio
|
| 22 |
datasets:
|
| 23 |
- openbmb/Ultra-FineWeb
|
| 24 |
- openbmb/Ultra-FineWeb-L3
|
|
@@ -27,37 +22,35 @@ datasets:
|
|
| 27 |
---
|
| 28 |
|
| 29 |
<div align="center">
|
| 30 |
-
<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/
|
| 31 |
</div>
|
| 32 |
|
| 33 |
<p align="center">
|
| 34 |
-
<a href="https://arxiv.org/pdf/2506.07900" target="_blank">MiniCPM
|
| 35 |
-
<a href="https://github.com/OpenBMB/MiniCPM
|
| 36 |
-
<a href="https://huggingface.co/openbmb/MiniCPM5-1B/blob/main/README.md" target="_blank">English</a> |
|
| 37 |
<a href="https://ultradata.openbmb.cn/" target="_blank">UltraData</a> |
|
| 38 |
-
<a href="https://github.com/OpenBMB/MiniCPM-Desk-Pet" target="_blank">MiniCPM 桌宠</a>
|
|
|
|
| 39 |
</p>
|
| 40 |
|
| 41 |
-
|
| 42 |
-
|
|
|
|
|
|
|
| 43 |
|
| 44 |
## 亮点
|
| 45 |
|
| 46 |
-
我们正式发布 **MiniCPM5-1B**,这是 **MiniCPM5** 系列的首个模型。它是一款面向端侧、本地部署和资源受限场景的 1B 稠密 Transformer,
|
| 47 |
|
| 48 |
🏆 **同尺寸开源模型 SOTA**:与同尺寸优秀开源模型相比,MiniCPM5-1B 在该对比范围内达到 SOTA 水平,优势主要体现在 Agentic 工具调用、代码生成和高难推理。
|
| 49 |
|
| 50 |
-

|
| 61 |
|
| 62 |
## 模型列表
|
| 63 |
|
|
@@ -75,8 +68,8 @@ MiniCPM5-1B 具有以下特性:
|
|
| 75 |
|
| 76 |
- **类型**:Causal Language Model
|
| 77 |
- **架构**:标准 `LlamaForCausalLM`
|
| 78 |
-
- **
|
| 79 |
-
- **
|
| 80 |
- **层数**:24
|
| 81 |
- **注意力头(GQA)**:16 个 Q heads / 2 个 KV heads
|
| 82 |
- **上下文长度**:131,072
|
|
@@ -89,88 +82,101 @@ MiniCPM5-1B 是 MiniCPM5 系列的首个模型,面向本地助手、coding age
|
|
| 89 |
|
| 90 |
我们选取 **LFM2.5-1.2B-Thinking**、**Qwen3-0.6B/think**、**Qwen3.5-0.8B/think** 等同尺寸优秀开源模型进行横向比较。这些模型本身已经很强;在这组对比中,MiniCPM5-1B 达到同尺寸开源模型 SOTA 水平,优势主要体现在工具调用、代码生成和高难推理上,也更适合承担本地 coding agent、工具助手和推理助手的角色。
|
| 91 |
|
| 92 |
-
、[Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3) 与 [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math)。
|
| 99 |
|
| 100 |
**后训练阶段**分为 **SFT**、**RL** 与 **OPD** 三步。我们先使用 **200B tokens deep-thinking SFT** 与 **200B tokens hybrid-thinking SFT** 建立深度思考、混合思考和通用对话能力,相关 SFT 数据已同步开源为 [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605)。随后针对数学、代码、闭卷问答和写作等方向训练专用 **RL teacher**,并通过 **On-Policy Distillation (OPD)** 将这些 teacher 的能力蒸馏回同一个发布模型。
|
| 101 |
|
| 102 |
-
 思路,并结合 [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016) 做了实现改进。我们在强化学习框架中使用反向 KL 散度作为优势估计值,替代原有的 verification-based advantage;同时在 response 序列的每个位置分别对学生模型和教师模型 logits 做双边 top-k 采样,取并集后计算反向 KL 散度,以平衡监督信号准确性和训练效率。OPD 直接复用各 RL teacher 训练时的同分布 prompt 作为蒸馏数据,无需额外构造语料。
|
| 113 |
|
| 114 |
-

|
| 117 |
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
仓库提供 MiniCPM5-1B 0517 checkpoint 的三种量化版本。三个文件都可被原版 `llama.cpp` / `Ollama` / `LM Studio` / `llama-cpp-python` / `llama-server` 直接加载,**无需任何 patch**。
|
| 121 |
-
|
| 122 |
-
| 文件 | 大小 | 量化 | 推荐场景 |
|
| 123 |
-
| --- | ---: | --- | --- |
|
| 124 |
-
| `MiniCPM5-1B-Q4_K_M.gguf` | 657 MB | Q4_K_M | 笔记本 / 边缘设备(推荐起步) |
|
| 125 |
-
| `MiniCPM5-1B-Q8_0.gguf` | 1.1 GB | Q8_0 | 接近 F16 质量、磁盘更友好 |
|
| 126 |
-
| `MiniCPM5-1B-F16.gguf` | 2.1 GB | F16 | 参考精度,可作为二次量化的源 |
|
| 127 |
|
| 128 |
## 快速上手
|
| 129 |
|
| 130 |
-
###
|
| 131 |
|
| 132 |
```bash
|
| 133 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 134 |
```
|
| 135 |
|
| 136 |
-
###
|
| 137 |
|
| 138 |
```bash
|
| 139 |
-
|
|
|
|
| 140 |
```
|
| 141 |
|
| 142 |
```bash
|
| 143 |
-
curl http://localhost:
|
| 144 |
-H "Content-Type: application/json" \
|
| 145 |
-d '{
|
| 146 |
-
"model": "MiniCPM5-1B",
|
| 147 |
-
"messages": [{"role":"user","content":"你是谁?可以简单介绍一下自己吗?"}],
|
| 148 |
-
"
|
| 149 |
-
"
|
| 150 |
-
"max_tokens": 256
|
| 151 |
}'
|
| 152 |
```
|
| 153 |
|
| 154 |
-
###
|
| 155 |
-
|
| 156 |
-
Ollama 和 LM Studio 都可以直接导入这些 GGUF 文件——选择上面任一文件并指定模型名即可,GGUF 内嵌的 chat template 会被原生识别。
|
| 157 |
-
|
| 158 |
-
### Think / No-Think 控制
|
| 159 |
-
|
| 160 |
-
MiniCPM5-1B 是 thinking 模型,chat template 通过 `chat_template_kwargs` 暴露 `enable_thinking` 开关:
|
| 161 |
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
| **强制 no-think** | `{"enable_thinking": false}` | 模板预填 `<think>
|
| 166 |
-
|
| 167 |
-
</think>
|
| 168 |
|
| 169 |
-
`
|
| 170 |
-
|
| 171 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
-
推荐 chat template 采样参数:
|
| 174 |
|
| 175 |
| 模式 | 推荐采样参数 | 启用方式 |
|
| 176 |
| --- | --- | --- |
|
|
@@ -179,7 +185,7 @@ MiniCPM5-1B 是 thinking 模型,chat template 通过 `chat_template_kwargs`
|
|
| 179 |
|
| 180 |
## 工具调用
|
| 181 |
|
| 182 |
-
工具调用
|
| 183 |
|
| 184 |
```bash
|
| 185 |
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000 \
|
|
@@ -194,28 +200,132 @@ MiniCPM5-1B 使用**标准 `LlamaForCausalLM` 架构**,主流推理引擎可
|
|
| 194 |
|
| 195 |
| 后端 | 模型格式 / 适用场景 | Cookbook | Agent Skill |
|
| 196 |
| --- | --- | --- | --- |
|
| 197 |
-
| Transformers | BF16 / FP16,本地 Python 推理,GPU + CPU | [transformers.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 198 |
-
| vLLM | BF16 / FP16 OpenAI server | [vllm.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 199 |
-
| SGLang | BF16 / FP16 OpenAI server,推荐用于 tool calling | [sglang.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 200 |
-
| llama.cpp | GGUF,CPU/GPU 本地推理 | [llama_cpp.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 201 |
-
| Ollama | GGUF,本地端侧运行 | [ollama.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 202 |
-
| LM Studio | GGUF,Mac 桌面应用与 OpenAI server | [lmstudio.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 203 |
-
| MLX | MLX / 4bit,Apple Silicon 本地推理 | [mlx.md](https://github.com/OpenBMB/MiniCPM/blob/
|
|
|
|
| 204 |
|
| 205 |
### 微调
|
| 206 |
|
| 207 |
| 框架 | 适用场景 | Cookbook | Agent Skill |
|
| 208 |
| --- | --- | --- | --- |
|
| 209 |
-
| TRL + PEFT | LoRA / SFT 微调 | [trl.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 210 |
-
| LLaMA-Factory | 微调 | [llamafactory.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 211 |
-
| ms-swift | 微调 | [ms_swift.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 212 |
-
| unsloth | 微调 | [unsloth.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 213 |
-
| xtuner | 微调 | [xtuner.md](https://github.com/OpenBMB/MiniCPM/blob/
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 214 |
|
| 215 |
## 桌宠
|
| 216 |
|
| 217 |
我们也发布了 **[OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)**,一个由 MiniCPM5-1B 本地驱动的桌宠应用。它支持 Apple Silicon / NVIDIA GPU / CPU 路线,可以与 Cursor、Claude Code、Codex 等 coding agent 联动,并支持 LoRA 人格切换。
|
| 218 |
|
|
|
|
|
|
|
| 219 |
## 局限性与负责任使用
|
| 220 |
|
| 221 |
MiniCPM5-1B 是一个基于训练数据统计规律生成文本的语言模型,可能生成不准确、有偏见或不安全的内容。在高风险场景中使用前,应对模型输出进行审查和验证。
|
|
|
|
| 3 |
language:
|
| 4 |
- zh
|
| 5 |
- en
|
| 6 |
+
library_name: transformers
|
| 7 |
pipeline_tag: text-generation
|
| 8 |
tags:
|
|
|
|
| 9 |
- minicpm
|
| 10 |
- minicpm5
|
| 11 |
- llama
|
|
|
|
| 14 |
- tool-calling
|
| 15 |
- on-device
|
| 16 |
- edge-ai
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
datasets:
|
| 18 |
- openbmb/Ultra-FineWeb
|
| 19 |
- openbmb/Ultra-FineWeb-L3
|
|
|
|
| 22 |
---
|
| 23 |
|
| 24 |
<div align="center">
|
| 25 |
+
<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/main/assets/minicpm_logo.png" width="500em" />
|
| 26 |
</div>
|
| 27 |
|
| 28 |
<p align="center">
|
| 29 |
+
<a href="https://arxiv.org/pdf/2506.07900" target="_blank">MiniCPM 技术报告</a> |
|
| 30 |
+
<a href="https://github.com/OpenBMB/MiniCPM" target="_blank">GitHub 仓库</a> |
|
|
|
|
| 31 |
<a href="https://ultradata.openbmb.cn/" target="_blank">UltraData</a> |
|
| 32 |
+
<a href="https://github.com/OpenBMB/MiniCPM-Desk-Pet" target="_blank">MiniCPM 桌宠</a> |
|
| 33 |
+
<a href="https://huggingface.co/spaces/openbmb/MiniCPM5-1B-Demo" target="_blank">在线 Demo</a>
|
| 34 |
</p>
|
| 35 |
|
| 36 |
+
<p align="center">
|
| 37 |
+
<a href="https://huggingface.co/openbmb/MiniCPM5-1B/blob/main/README.md" target="_blank">English</a> |
|
| 38 |
+
中文
|
| 39 |
+
</p>
|
| 40 |
|
| 41 |
## 亮点
|
| 42 |
|
| 43 |
+
我们正式发布 **MiniCPM5-1B**,这是 **MiniCPM5** 系列的首个模型。它是一款面向端侧、本地部署和资源受限场景的 1B 稠密 Transformer,能够达到同尺寸开源模型 SOTA 水平。
|
| 44 |
|
| 45 |
🏆 **同尺寸开源模型 SOTA**:与同尺寸优秀开源模型相比,MiniCPM5-1B 在该对比范围内达到 SOTA 水平,优势主要体现在 Agentic 工具调用、代码生成和高难推理。
|
| 46 |
|
| 47 |
+
|
| 48 |
|
| 49 |
🧠 **双模式推理**:内置 `<think>` chat template,可通过 `enable_thinking` 在思考模式和非思考模式之间切换。同一份权重既可以作为快速助手,也可以承担更复杂的推理任务。
|
| 50 |
|
| 51 |
🛠️ **部署 / 微调资源**:MiniCPM GitHub 仓库提供面向主要推理后端和微调框架的单页 cookbook,并配套 Agent Skills,方便复现部署和微调流程。
|
| 52 |
|
| 53 |
+
🐱 **桌宠**:我们也提供了由 MiniCPM5-1B 本地驱动的桌宠应用。
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
|
| 55 |
## 模型列表
|
| 56 |
|
|
|
|
| 68 |
|
| 69 |
- **类型**:Causal Language Model
|
| 70 |
- **架构**:标准 `LlamaForCausalLM`
|
| 71 |
+
- **参数数量**:1,080,632,832
|
| 72 |
+
- **非嵌入参数数量**:679,552,512
|
| 73 |
- **层数**:24
|
| 74 |
- **注意力头(GQA)**:16 个 Q heads / 2 个 KV heads
|
| 75 |
- **上下文长度**:131,072
|
|
|
|
| 82 |
|
| 83 |
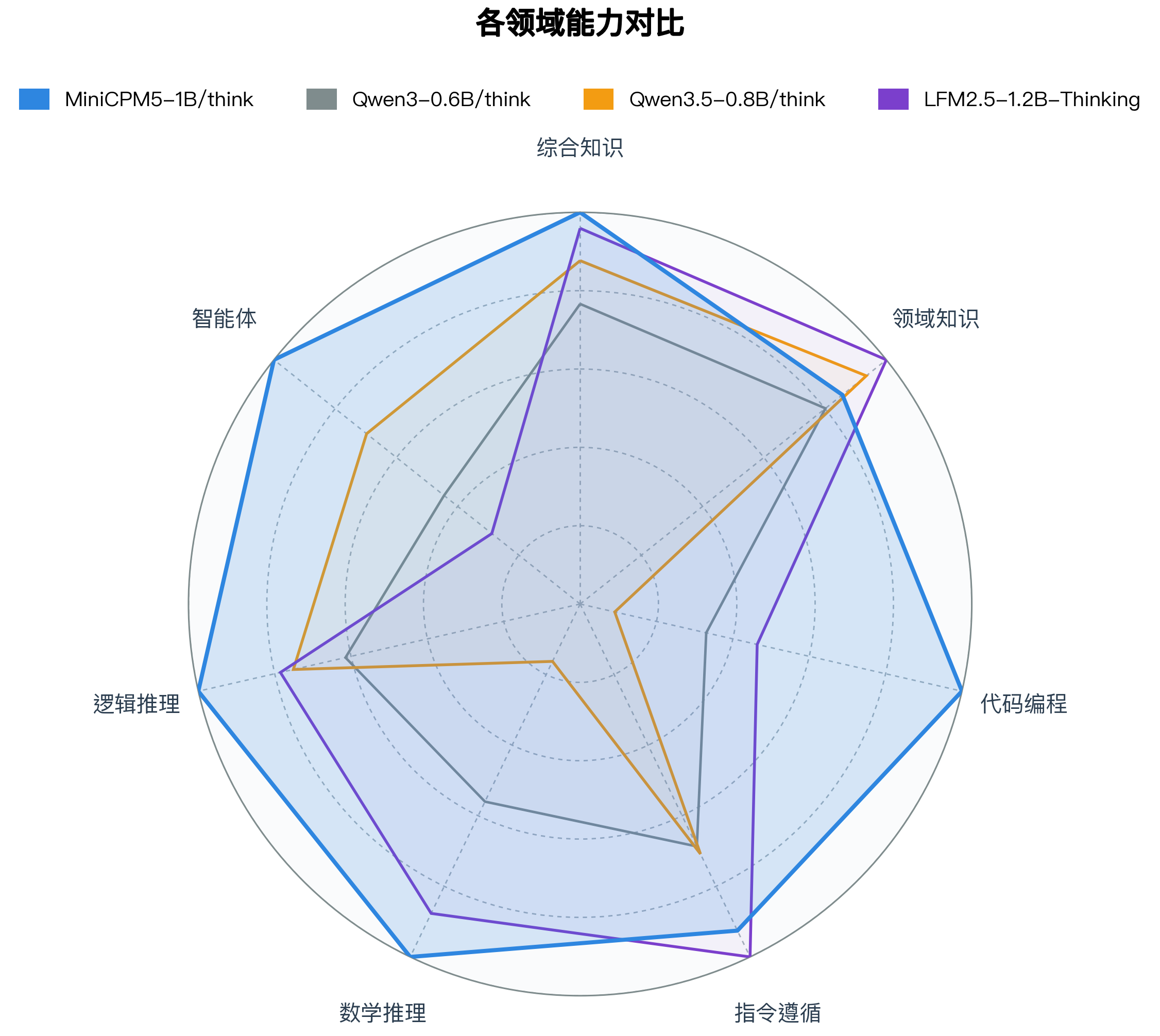
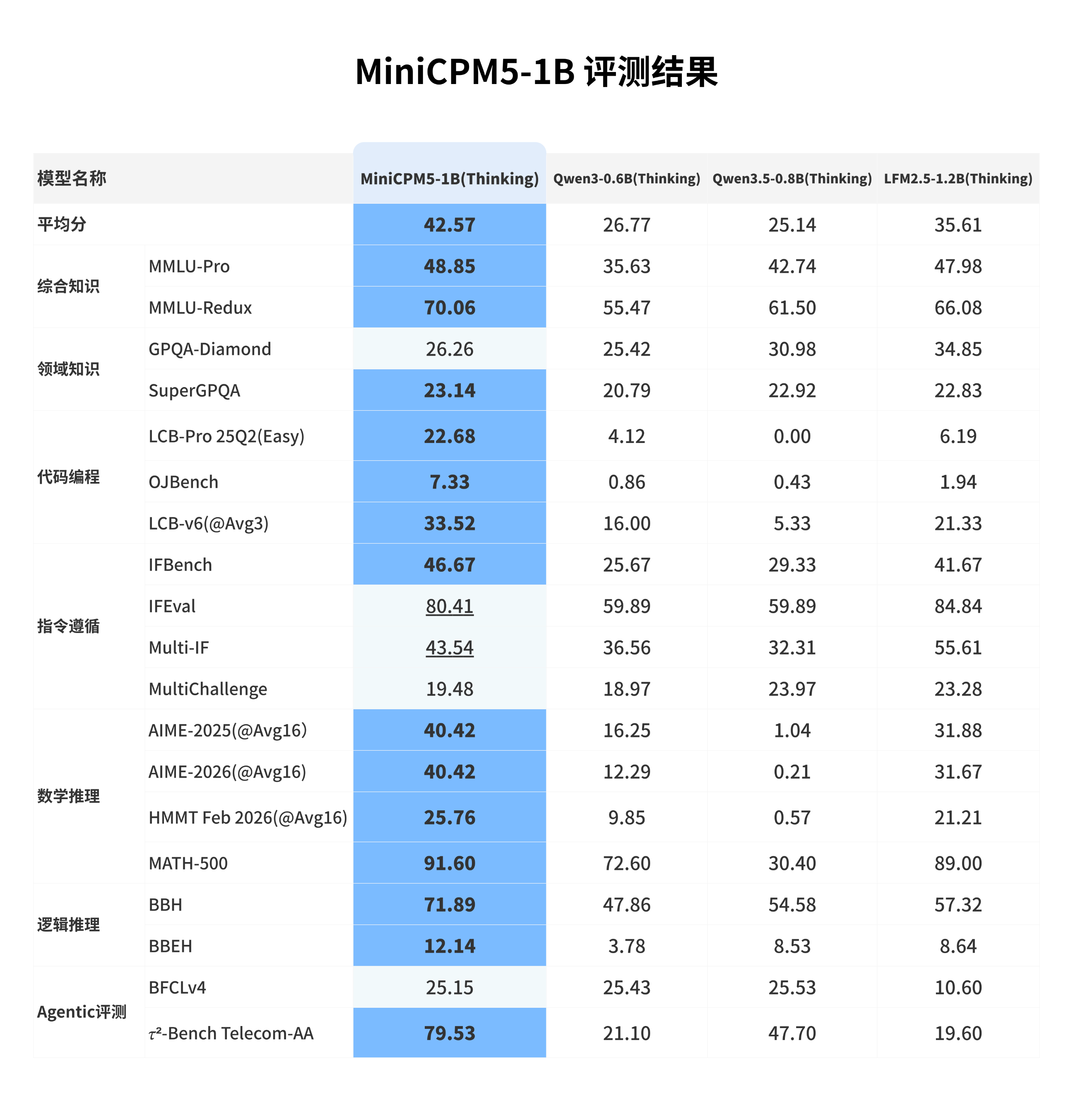
我们选取 **LFM2.5-1.2B-Thinking**、**Qwen3-0.6B/think**、**Qwen3.5-0.8B/think** 等同尺寸优秀开源模型进行横向比较。这些模型本身已经很强;在这组对比中,MiniCPM5-1B 达到同尺寸开源模型 SOTA 水平,优势主要体现在工具调用、代码生成和高难推理上,也更适合承担本地 coding agent、工具助手和推理助手的角色。
|
| 84 |
|
| 85 |
+
|
| 86 |
|
| 87 |
## 训练流程
|
| 88 |
|
| 89 |
+
MiniCPM5-1B 的训练过程是 **[UltraData 分级数据管理体系](https://arxiv.org/pdf/2602.09003)** 的一次完整实践,覆盖 base training、mid-training 与后训练三个阶段。
|
| 90 |
|
| 91 |
**Base training** 采用逐级推进的训练配方,包含 stable training 与 decay training,用于建立基础语言能力与训练稳定性。随后进入 **mid-training**,进一步强化目标能力并适配数据分布。训练语料来自我们同步开源的 [Ultra-FineWeb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb)、[Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3) 与 [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math)。
|
| 92 |
|
| 93 |
**后训练阶段**分为 **SFT**、**RL** 与 **OPD** 三步。我们先使用 **200B tokens deep-thinking SFT** 与 **200B tokens hybrid-thinking SFT** 建立深度思考、混合思考和通用对话能力,相关 SFT 数据已同步开源为 [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605)。随后针对数学、代码、闭卷问答和写作等方向训练专用 **RL teacher**,并通过 **On-Policy Distillation (OPD)** 将这些 teacher 的能力蒸馏回同一个发布模型。
|
| 94 |
|
| 95 |
+

|
| 96 |
|
| 97 |
### RL + OPD 带来了什么?
|
| 98 |
|
| 99 |
**RL + OPD** 是 MiniCPM5-1B 后训练中的关键环节。在数学、代码、指令跟随三类任务上,RL + OPD 将平均分提升 **↑16 分**,同时将回复触顶 max-tokens 预算的比例降低 **↓29 个百分点**。下方图示展示 Reasoning RL 两阶段流程、分数提升和超长率下降。
|
| 100 |
|
| 101 |
+
**RL** 阶段组合了推理、闭卷问答、写作、指令跟随、长上下文理解和通用对话等多类互补训练信号。Reasoning RL 基于 [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k),在遵循 [JustRL](https://arxiv.org/pdf/2512.16649) 极简配方的基础上,进一步加入了两阶段长度调度,逐步降低超长率并提升推理准确率。我们还使用 [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa)、[NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open)、[LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData)、合成可验证 RLVR 数据与 pair-wise RLHF 信号,提升可靠性、指令跟随和用户体验。
|
| 102 |
|
| 103 |
+

|
| 104 |
|
| 105 |
**OPD** 阶段参考 Thinking Machines Lab 的 [On-Policy Distillation](https://thinkingmachines.ai/blog/on-policy-distillation/) 思路,并结合 [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016) 做了实现改进。我们在强化学习框架中使用反向 KL 散度作为优势估计值,替代原有的 verification-based advantage;同时在 response 序列的每个位置分别对学生模型和教师模型 logits 做双边 top-k 采样,取并集后计算反向 KL 散度,以平衡监督信号准确性和训练效率。OPD 直接复用各 RL teacher 训练时的同分布 prompt 作为蒸馏数据,无需额外构造语料。
|
| 106 |
|
| 107 |
+

|
|
|
|
|
|
|
| 108 |
|
| 109 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
## 快速上手
|
| 112 |
|
| 113 |
+
### vLLM
|
| 114 |
|
| 115 |
```bash
|
| 116 |
+
pip install "vllm>=0.21"
|
| 117 |
+
vllm serve openbmb/MiniCPM5-1B --port 8000
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
```bash
|
| 121 |
+
curl http://localhost:8000/v1/chat/completions \
|
| 122 |
+
-H "Content-Type: application/json" \
|
| 123 |
+
-d '{
|
| 124 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 125 |
+
"messages": [{"role": "user", "content": "你是谁?可以简单介绍一下自己吗?"}],
|
| 126 |
+
"max_tokens": 128,
|
| 127 |
+
"temperature": 0.7
|
| 128 |
+
}'
|
| 129 |
```
|
| 130 |
|
| 131 |
+
### SGLang
|
| 132 |
|
| 133 |
```bash
|
| 134 |
+
pip install "sglang[srt]>=0.5.12"
|
| 135 |
+
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000
|
| 136 |
```
|
| 137 |
|
| 138 |
```bash
|
| 139 |
+
curl http://localhost:30000/v1/chat/completions \
|
| 140 |
-H "Content-Type: application/json" \
|
| 141 |
-d '{
|
| 142 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 143 |
+
"messages": [{"role": "user", "content": "你是谁?可以简单介绍一下自己吗?"}],
|
| 144 |
+
"max_tokens": 128,
|
| 145 |
+
"temperature": 0.7
|
|
|
|
| 146 |
}'
|
| 147 |
```
|
| 148 |
|
| 149 |
+
### Transformers
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 150 |
|
| 151 |
+
```bash
|
| 152 |
+
pip install -U "transformers>=5.6" accelerate torch
|
| 153 |
+
```
|
|
|
|
|
|
|
|
|
|
| 154 |
|
| 155 |
+
```python
|
| 156 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 157 |
+
|
| 158 |
+
model_id = "openbmb/MiniCPM5-1B"
|
| 159 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 160 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 161 |
+
model_id,
|
| 162 |
+
torch_dtype="auto",
|
| 163 |
+
device_map="auto",
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
messages = [{"role": "user", "content": "你是谁?可以简单介绍一下自己吗?"}]
|
| 167 |
+
inputs = tokenizer.apply_chat_template(
|
| 168 |
+
messages,
|
| 169 |
+
tokenize=True,
|
| 170 |
+
add_generation_prompt=True,
|
| 171 |
+
enable_thinking=False,
|
| 172 |
+
return_tensors="pt",
|
| 173 |
+
).to(model.device)
|
| 174 |
+
|
| 175 |
+
outputs = model.generate(inputs, max_new_tokens=128)
|
| 176 |
+
print(tokenizer.decode(outputs[0][inputs.shape[-1]:], skip_special_tokens=True))
|
| 177 |
+
```
|
| 178 |
|
| 179 |
+
推荐的 chat template 采样参数:
|
| 180 |
|
| 181 |
| 模式 | 推荐采样参数 | 启用方式 |
|
| 182 |
| --- | --- | --- |
|
|
|
|
| 185 |
|
| 186 |
## 工具调用
|
| 187 |
|
| 188 |
+
工具调用**推荐使用 SGLang**。MiniCPM5-1B 以 XML 格式产出工具调用,SGLang 内置的 `minicpm5` parser 会自动将其转换为 OpenAI 兼容的 `tool_calls` 字段。
|
| 189 |
|
| 190 |
```bash
|
| 191 |
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000 \
|
|
|
|
| 200 |
|
| 201 |
| 后端 | 模型格式 / 适用场景 | Cookbook | Agent Skill |
|
| 202 |
| --- | --- | --- | --- |
|
| 203 |
+
| Transformers | BF16 / FP16,本地 Python 推理,GPU + CPU | [transformers.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/transformers.md) | [minicpm5-deploy-transformers](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-transformers/SKILL.md) |
|
| 204 |
+
| vLLM | BF16 / FP16 OpenAI server | [vllm.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/vllm.md) | [minicpm5-deploy-vllm](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-vllm/SKILL.md) |
|
| 205 |
+
| SGLang | BF16 / FP16 OpenAI server,推荐用于 tool calling | [sglang.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/sglang.md) | [minicpm5-deploy-sglang](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-sglang/SKILL.md) |
|
| 206 |
+
| llama.cpp | GGUF,CPU/GPU 本地推理 | [llama_cpp.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/llama_cpp.md) | [minicpm5-deploy-llama-cpp](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-llama-cpp/SKILL.md) |
|
| 207 |
+
| Ollama | GGUF,本地端侧运行 | [ollama.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/ollama.md) | [minicpm5-deploy-ollama](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-ollama/SKILL.md) |
|
| 208 |
+
| LM Studio | GGUF,Mac 桌面应用与 OpenAI server | [lmstudio.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/lmstudio.md) | [minicpm5-deploy-lmstudio](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-lmstudio/SKILL.md) |
|
| 209 |
+
| MLX | MLX / 4bit,Apple Silicon 本地推理 | [mlx.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/mlx.md) | [minicpm5-deploy-mlx](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-mlx/SKILL.md) |
|
| 210 |
+
| ArcLight | GGUF 本地端侧 / CPU / 桌面 / 服务器 | [arclight.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/arclight.md) | [minicpm5-deploy-arclight](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-arclight/SKILL.md) |
|
| 211 |
|
| 212 |
### 微调
|
| 213 |
|
| 214 |
| 框架 | 适用场景 | Cookbook | Agent Skill |
|
| 215 |
| --- | --- | --- | --- |
|
| 216 |
+
| TRL + PEFT | LoRA / SFT 微调 | [trl.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/trl.md) | [minicpm5-finetune-trl](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-trl/SKILL.md) |
|
| 217 |
+
| LLaMA-Factory | 微调 | [llamafactory.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/llamafactory.md) | [minicpm5-finetune-llamafactory](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-llamafactory/SKILL.md) |
|
| 218 |
+
| ms-swift | 微调 | [ms_swift.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/ms_swift.md) | [minicpm5-finetune-ms-swift](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-ms-swift/SKILL.md) |
|
| 219 |
+
| unsloth | 微调 | [unsloth.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/unsloth.md) | [minicpm5-finetune-unsloth](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-unsloth/SKILL.md) |
|
| 220 |
+
| xtuner | 微调 | [xtuner.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/xtuner.md) | [minicpm5-finetune-xtuner](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-xtuner/SKILL.md) |
|
| 221 |
+
|
| 222 |
+
### 其他支持的框架
|
| 223 |
+
|
| 224 |
+
除上文列出的部署与微调框架外,MiniCPM5-1B 也支持通过 FlagOS 进行多芯片部署。
|
| 225 |
+
|
| 226 |
+
#### FlagOS 介绍
|
| 227 |
+
|
| 228 |
+
为解决不同 AI 芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了 FlagOS 开源社区。
|
| 229 |
+
|
| 230 |
+
FlagOS 社区致力于打造面向多种 AI 芯片的统一、开源的系统软件栈,包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,构建「模型-系统-芯片」三层贯通的开放技术生态,通过“一次开发跨芯迁移”释放硬件计算潜力,打破不同芯片软件栈之间生态隔离,有效降低开发者的迁移成本。FlagOS 社区构建人工智能软硬件生态,突破单一闭源垄断,推动AI硬件技术大范围落地发展,立足中国、拥抱全球合作。
|
| 231 |
+
|
| 232 |
+
官网速递:[https://flagos.io](https://flagos.io/)
|
| 233 |
+
|
| 234 |
+
<details>
|
| 235 |
+
<summary>FlagOS 多 AI 芯片支持与使用方式</summary>
|
| 236 |
+
|
| 237 |
+
#### FlagOS 多 AI 芯片支持
|
| 238 |
+
|
| 239 |
+
基于 FlagOS 极短时间内适配 MiniCPM5-1B 到 9 种不同的 AI 芯片,得益于众智 FlagOS 的多芯片统一 AI 系统软件栈的能力。目前,在 FlagOS 团队构建的面向多架构人工智能芯片的大模型自动迁移、适配与发布平台 FlagRelease 上,已发布 MiniCPM5-1B 的多芯片版本。细节如下:
|
| 240 |
+
|
| 241 |
+
|Vendor|ModelScope|Huggingface|
|
| 242 |
+
|---|---|---|
|
| 243 |
+
|Nvidia|[MiniCPM5-1B-nvidia-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 244 |
+
|Hygon|[MiniCPM5-1B-hygon-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|[MiniCPM5-1B-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|
|
| 245 |
+
|Metax|[MiniCPM5-1B-metax-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-metax-FlagOS)|[MiniCPM5-1B-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-metax-FlagOS)|
|
| 246 |
+
|Iluvatar|[MiniCPM5-1B-iluvatar-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|[MiniCPM5-1B-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|
|
| 247 |
+
|Zhenwu|[MiniCPM5-1B-zhenwu-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|[MiniCPM5-1B-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|
|
| 248 |
+
|Mthreads|[MiniCPM5-1B-mthreads-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|[MiniCPM5-1B-mthreads-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|
|
| 249 |
+
|Kunlunxin|[MiniCPM5-1B-kunlunxin-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|[MiniCPM5-1B-kunlunxin-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|
|
| 250 |
+
|Ascend|[MiniCPM5-1B-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|[MiniCPM5-1B-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|
|
| 251 |
+
|ARM-v9|[MiniCPM5-1B-Armv9-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|[MiniCPM5-1B-Armv9-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|
|
| 252 |
+
|
| 253 |
+
#### FlagOS 使用方式
|
| 254 |
+
|
| 255 |
+
##### 使用 FlagOS 在 Nvidia 体验性能加速
|
| 256 |
+
|
| 257 |
+
###### From FlagRelease(**推荐**)
|
| 258 |
+
|
| 259 |
+
FlagRelease是FlagOS团队构建的一套面向多架构人工智能芯片的大模型自动迁移、适配与发布平台,已发布MiniCPM-1B的多芯片版本。FlagRelase已内置相关软件包,无需用户安装。
|
| 260 |
+
|
| 261 |
+
###### FlagRelease 镜像关键版本信息
|
| 262 |
+
|
| 263 |
+
###### FlagRelease 使用速递
|
| 264 |
+
|
| 265 |
+
|Vendor|ModelScope|Huggingface|
|
| 266 |
+
|---|---|---|
|
| 267 |
+
|Nvidia|[MiniCPM5-1B-nvidia-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 268 |
+
|Hygon|[MiniCPM5-1B-hygon-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|[MiniCPM5-1B-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|
|
| 269 |
+
|Metax|[MiniCPM5-1B-metax-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-metax-FlagOS)|[MiniCPM5-1B-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-metax-FlagOS)|
|
| 270 |
+
|Iluvatar|[MiniCPM5-1B-iluvatar-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|[MiniCPM5-1B-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|
|
| 271 |
+
|Zhenwu|[MiniCPM5-1B-zhenwu-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|[MiniCPM5-1B-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|
|
| 272 |
+
|Mthreads|[MiniCPM5-1B-mthreads-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|[MiniCPM5-1B-mthreads-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|
|
| 273 |
+
|Kunlunxin|[MiniCPM5-1B-kunlunxin-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|[MiniCPM5-1B-kunlunxin-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|
|
| 274 |
+
|Ascend|[MiniCPM5-1B-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|[MiniCPM5-1B-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|
|
| 275 |
+
|ARM-v9|[MiniCPM5-1B-Armv9-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|[MiniCPM5-1B-Armv9-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|
|
| 276 |
+
|
| 277 |
+
###### 从零开始
|
| 278 |
+
|
| 279 |
+
- 依赖Python3.12, GLIBC_2.39, GLIBCXX_3.4.33, CXXABI_1.3.15 环境
|
| 280 |
+
|
| 281 |
+
###### Vllm 版本
|
| 282 |
+
|
| 283 |
+
###### 安装 FlagOS 算子库
|
| 284 |
+
|
| 285 |
+
官方仓库:https://github.com/flagos-ai/FlagGems
|
| 286 |
+
|
| 287 |
+
```PowerShell
|
| 288 |
+
pip install flag-gems==4.2.1rc0
|
| 289 |
+
pip install triton==3.5.1
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
###### 开启加速
|
| 293 |
+
|
| 294 |
+
通过在vllm执行推理的源码中增加flagGems的导入即可开启flagGems加速
|
| 295 |
+
|
| 296 |
+
```Bash
|
| 297 |
+
import flag_gems
|
| 298 |
+
flag_gems.enable(record=True, once=True, path="/root/gems.txt")
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
```Bash
|
| 302 |
+
vllm serve ${model_path} \
|
| 303 |
+
--trust-remote-code \
|
| 304 |
+
--dtype bfloat16 \
|
| 305 |
+
--enforce-eager \
|
| 306 |
+
--port ${Port} \
|
| 307 |
+
--served-model-name ${model_name} \
|
| 308 |
+
--gpu-memory-utilization 0.85
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
##### 使用 FlagOS 统一多芯片后端插件
|
| 312 |
+
|
| 313 |
+
**[vllm-plugin-FL](https://github.com/flagos-ai/vllm-plugin-FL)** 是一个为 **vLLM** 推理/服务框架构建的插件,它基于 **FlagOS 的统一多芯片后端**开发,旨在扩展 vLLM 在多种硬件环境下的功能和性能表现。
|
| 314 |
+
|
| 315 |
+
###### vllm-plugin-FL 使用
|
| 316 |
+
|
| 317 |
+
|厂商|从零开始|从 FlagRelease 开始||
|
| 318 |
+
|---|---|---|---|
|
| 319 |
+
|英伟达|[vllm-plugin-FL/MiniCPM5-1B](https://github.com/flagos-ai/vllm-plugin-FL/blob/main/examples/minicpm/README.md)|[MiniCPM5-1B-ModelScope](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 320 |
+
|
| 321 |
+
</details>
|
| 322 |
|
| 323 |
## 桌宠
|
| 324 |
|
| 325 |
我们也发布了 **[OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)**,一个由 MiniCPM5-1B 本地驱动的桌宠应用。它支持 Apple Silicon / NVIDIA GPU / CPU 路线,可以与 Cursor、Claude Code、Codex 等 coding agent 联动,并支持 LoRA 人格切换。
|
| 326 |
|
| 327 |
+
<a href="https://youtu.be/Ee0slMW8SEk"><img src="https://img.youtube.com/vi/Ee0slMW8SEk/0.jpg" alt="MiniCPM Desk Pet video demo" width="720"></a>
|
| 328 |
+
|
| 329 |
## 局限性与负责任使用
|
| 330 |
|
| 331 |
MiniCPM5-1B 是一个基于训练数据统计规律生成文本的语言模型,可能生成不准确、有偏见或不安全的内容。在高风险场景中使用前,应对模型输出进行审查和验证。
|
README.md
CHANGED
|
@@ -3,10 +3,9 @@ license: apache-2.0
|
|
| 3 |
language:
|
| 4 |
- en
|
| 5 |
- zh
|
| 6 |
-
library_name:
|
| 7 |
pipeline_tag: text-generation
|
| 8 |
tags:
|
| 9 |
-
- gguf
|
| 10 |
- minicpm
|
| 11 |
- minicpm5
|
| 12 |
- llama
|
|
@@ -15,10 +14,6 @@ tags:
|
|
| 15 |
- tool-calling
|
| 16 |
- on-device
|
| 17 |
- edge-ai
|
| 18 |
-
- quantized
|
| 19 |
-
- llama-cpp
|
| 20 |
-
- ollama
|
| 21 |
-
- lm-studio
|
| 22 |
datasets:
|
| 23 |
- openbmb/Ultra-FineWeb
|
| 24 |
- openbmb/Ultra-FineWeb-L3
|
|
@@ -27,37 +22,35 @@ datasets:
|
|
| 27 |
---
|
| 28 |
|
| 29 |
<div align="center">
|
| 30 |
-
<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/
|
| 31 |
</div>
|
| 32 |
|
| 33 |
<p align="center">
|
| 34 |
-
<a href="https://arxiv.org/pdf/2506.07900" target="_blank">MiniCPM
|
| 35 |
-
<a href="https://github.com/OpenBMB/MiniCPM
|
| 36 |
-
<a href="https://huggingface.co/openbmb/MiniCPM5-1B/blob/main/README-cn.md" target="_blank">中文</a> |
|
| 37 |
<a href="https://ultradata.openbmb.cn/" target="_blank">UltraData</a> |
|
| 38 |
-
<a href="https://github.com/OpenBMB/MiniCPM-Desk-Pet" target="_blank">MiniCPM Desk Pet</a>
|
|
|
|
| 39 |
</p>
|
| 40 |
|
| 41 |
-
|
| 42 |
-
|
|
|
|
|
|
|
| 43 |
|
| 44 |
## Highlights
|
| 45 |
|
| 46 |
-
We are releasing **MiniCPM5-1B**, the first model in the **MiniCPM5** series. It is a dense 1B Transformer built for on-device, local deployment, and resource-constrained scenarios, reaching 1B-class open-source SOTA
|
| 47 |
|
| 48 |
🏆 **1B-class open-source SOTA**: compared with strong open-source models in the same size class, MiniCPM5-1B reaches SOTA within this comparison set. Its advantage is most visible in agentic tool use, code generation, and difficult reasoning.
|
| 49 |
|
| 50 |
-

|
| 61 |
|
| 62 |
## Model List
|
| 63 |
|
|
@@ -89,86 +82,99 @@ MiniCPM5-1B is the first checkpoint in the MiniCPM5 series. It is designed for l
|
|
| 89 |
|
| 90 |
We compare MiniCPM5-1B with strong open-source models in the same size class, including **LFM2.5-1.2B-Thinking**, **Qwen3-0.6B/think** and **Qwen3.5-0.8B/think**. These are capable baselines; within this comparison set, MiniCPM5-1B reaches 1B-class open-source SOTA, with its advantage most visible in tool use, code generation, and difficult reasoning. This makes it a practical choice for local coding agents, tool assistants, and reasoning assistants.
|
| 91 |
|
| 92 |
-
, [Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3), and [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math).
|
| 99 |
|
| 100 |
During **post-training**, we proceed in three steps: **SFT**, **RL**, and **OPD**. We first use **200B tokens of deep-thinking SFT** and **200B tokens of hybrid-thinking SFT** to establish deep-thinking, hybrid-thinking, and general chat abilities; the SFT data is released as [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605). We then train specialized **RL teachers** for math, code, closed-book QA, writing, and related domains, and use **On-Policy Distillation (OPD)** to distill these teachers back into one release model.
|
| 101 |
|
| 102 |
-
 and incorporates implementation improvements from [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016). In the RL framework, we use reverse KL divergence as the advantage estimate, replacing the original verification-based advantage. At each response position, we take top-k logits from both the student and teacher models, compute reverse KL on the union of the two token sets, and balance the accuracy of the RKL signal with training efficiency. OPD reuses the in-domain prompts used to train each RL teacher as distillation data, so no additional data curation is required.
|
| 113 |
|
| 114 |
-

|
| 117 |
-
|
| 118 |
-
## GGUF Files
|
| 119 |
-
|
| 120 |
-
This repository ships three quantizations of the MiniCPM5-1B 0517 checkpoint. All three are ready to use with vanilla `llama.cpp` / `Ollama` / `LM Studio` / `llama-cpp-python` / `llama-server` — no patches required.
|
| 121 |
|
| 122 |
-
|
| 123 |
-
| --- | ---: | --- | --- |
|
| 124 |
-
| `MiniCPM5-1B-Q4_K_M.gguf` | 657 MB | Q4_K_M | Laptops / edge devices (start here) |
|
| 125 |
-
| `MiniCPM5-1B-Q8_0.gguf` | 1.1 GB | Q8_0 | Near-F16 quality with smaller footprint |
|
| 126 |
-
| `MiniCPM5-1B-F16.gguf` | 2.1 GB | F16 | Reference precision; source for further quantization |
|
| 127 |
|
| 128 |
## Quickstart
|
| 129 |
|
| 130 |
-
###
|
| 131 |
|
| 132 |
```bash
|
| 133 |
-
|
|
|
|
| 134 |
```
|
| 135 |
|
| 136 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 137 |
|
| 138 |
```bash
|
| 139 |
-
|
|
|
|
| 140 |
```
|
| 141 |
|
| 142 |
```bash
|
| 143 |
-
curl http://localhost:
|
| 144 |
-H "Content-Type: application/json" \
|
| 145 |
-d '{
|
| 146 |
-
"model": "MiniCPM5-1B",
|
| 147 |
-
"messages": [{"role":"user","content":"Who are you? Please briefly introduce yourself."}],
|
| 148 |
-
"
|
| 149 |
-
"
|
| 150 |
-
"max_tokens": 256
|
| 151 |
}'
|
| 152 |
```
|
| 153 |
|
| 154 |
-
###
|
| 155 |
-
|
| 156 |
-
Both Ollama and LM Studio can import the GGUF files directly — point them at any of the three files above and pick a model name; the bundled chat template is recognized natively.
|
| 157 |
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
| Mode | `chat_template_kwargs` | Behaviour |
|
| 163 |
-
| --- | --- | --- |
|
| 164 |
-
| **Auto** (default) | omit | Model decides whether to use `<think>` |
|
| 165 |
-
| **Force no-think** | `{"enable_thinking": false}` | Template prefills `<think>
|
| 166 |
-
|
| 167 |
-
</think>
|
| 168 |
|
| 169 |
-
`
|
| 170 |
-
|
| 171 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
Recommended chat template sampling:
|
| 174 |
|
|
@@ -194,28 +200,132 @@ MiniCPM5-1B uses the **standard `LlamaForCausalLM` architecture**, so mainstream
|
|
| 194 |
|
| 195 |
| Backend | Model format / use case | Cookbook | Agent Skill |
|
| 196 |
| --- | --- | --- | --- |
|
| 197 |
-
| Transformers | BF16 / FP16 local Python inference, GPU + CPU | [transformers.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 198 |
-
| vLLM | BF16 / FP16 OpenAI server | [vllm.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 199 |
-
| SGLang | BF16 / FP16 OpenAI server, recommended for tool calling | [sglang.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 200 |
-
| llama.cpp | GGUF local inference, CPU/GPU | [llama_cpp.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 201 |
-
| Ollama | GGUF local on-device runtime | [ollama.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 202 |
-
| LM Studio | GGUF Mac desktop app and OpenAI server | [lmstudio.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 203 |
-
| MLX | MLX / 4bit local inference on Apple Silicon | [mlx.md](https://github.com/OpenBMB/MiniCPM/blob/
|
|
|
|
| 204 |
|
| 205 |
### Fine-tuning
|
| 206 |
|
| 207 |
| Framework | Use case | Cookbook | Agent Skill |
|
| 208 |
| --- | --- | --- | --- |
|
| 209 |
-
| TRL + PEFT | LoRA / SFT fine-tuning | [trl.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 210 |
-
| LLaMA-Factory | Fine-tuning | [llamafactory.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 211 |
-
| ms-swift | Fine-tuning | [ms_swift.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 212 |
-
| unsloth | Fine-tuning | [unsloth.md](https://github.com/OpenBMB/MiniCPM/blob/
|
| 213 |
-
| xtuner | Fine-tuning | [xtuner.md](https://github.com/OpenBMB/MiniCPM/blob/
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 214 |
|
| 215 |
## Desktop Pet
|
| 216 |
|
| 217 |
We also ship **[OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)**, a desktop pet driven locally by MiniCPM5-1B. It supports Apple Silicon / NVIDIA GPU / CPU paths, can work with coding agents such as Cursor, Claude Code, and Codex, and supports LoRA persona switching.
|
| 218 |
|
|
|
|
|
|
|
| 219 |
## Limitations and Responsible Use
|
| 220 |
|
| 221 |
MiniCPM5-1B is a language model that generates content based on learned statistical patterns from training data. It may produce inaccurate, biased, or unsafe outputs, and generated content should be reviewed and verified before use in high-stakes settings.
|
|
|
|
| 3 |
language:
|
| 4 |
- en
|
| 5 |
- zh
|
| 6 |
+
library_name: transformers
|
| 7 |
pipeline_tag: text-generation
|
| 8 |
tags:
|
|
|
|
| 9 |
- minicpm
|
| 10 |
- minicpm5
|
| 11 |
- llama
|
|
|
|
| 14 |
- tool-calling
|
| 15 |
- on-device
|
| 16 |
- edge-ai
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
datasets:
|
| 18 |
- openbmb/Ultra-FineWeb
|
| 19 |
- openbmb/Ultra-FineWeb-L3
|
|
|
|
| 22 |
---
|
| 23 |
|
| 24 |
<div align="center">
|
| 25 |
+
<img src="https://raw.githubusercontent.com/OpenBMB/MiniCPM/main/assets/minicpm_logo.png" width="500em" />
|
| 26 |
</div>
|
| 27 |
|
| 28 |
<p align="center">
|
| 29 |
+
<a href="https://arxiv.org/pdf/2506.07900" target="_blank">MiniCPM Tech Report</a> |
|
| 30 |
+
<a href="https://github.com/OpenBMB/MiniCPM" target="_blank">GitHub Repo</a> |
|
|
|
|
| 31 |
<a href="https://ultradata.openbmb.cn/" target="_blank">UltraData</a> |
|
| 32 |
+
<a href="https://github.com/OpenBMB/MiniCPM-Desk-Pet" target="_blank">MiniCPM Desk Pet</a> |
|
| 33 |
+
<a href="https://huggingface.co/spaces/openbmb/MiniCPM5-1B-Demo" target="_blank">Online Demo</a>
|
| 34 |
</p>
|
| 35 |
|
| 36 |
+
<p align="center">
|
| 37 |
+
English |
|
| 38 |
+
<a href="https://huggingface.co/openbmb/MiniCPM5-1B/blob/main/README-cn.md" target="_blank">中文</a>
|
| 39 |
+
</p>
|
| 40 |
|
| 41 |
## Highlights
|
| 42 |
|
| 43 |
+
We are releasing **MiniCPM5-1B**, the first model in the **MiniCPM5** series. It is a dense 1B Transformer built for on-device, local deployment, and resource-constrained scenarios, reaching 1B-class open-source SOTA.
|
| 44 |
|
| 45 |
🏆 **1B-class open-source SOTA**: compared with strong open-source models in the same size class, MiniCPM5-1B reaches SOTA within this comparison set. Its advantage is most visible in agentic tool use, code generation, and difficult reasoning.
|
| 46 |
|
| 47 |
+

|
| 48 |
|
| 49 |
+
🧠 **Hybrid Reasoning**: built-in `<think>` chat template, switch via `enable_thinking`. The same checkpoint serves as both a fast assistant and a deliberate reasoner.
|
| 50 |
|
| 51 |
🛠️ **Deployment / Fine-tuning Resources**: the MiniCPM GitHub repo provides single-page cookbooks and Agent Skills for major inference backends and fine-tuning frameworks.
|
| 52 |
|
| 53 |
+
🐱 **Desktop Pet**: a local-LLM desktop pet driven by MiniCPM5-1B.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
|
| 55 |
## Model List
|
| 56 |
|
|
|
|
| 82 |
|
| 83 |
We compare MiniCPM5-1B with strong open-source models in the same size class, including **LFM2.5-1.2B-Thinking**, **Qwen3-0.6B/think** and **Qwen3.5-0.8B/think**. These are capable baselines; within this comparison set, MiniCPM5-1B reaches 1B-class open-source SOTA, with its advantage most visible in tool use, code generation, and difficult reasoning. This makes it a practical choice for local coding agents, tool assistants, and reasoning assistants.
|
| 84 |
|
| 85 |
+

|
| 86 |
|
| 87 |
## Training Recipe
|
| 88 |
|
| 89 |
+
The training of MiniCPM5-1B is a full-stack practice of **[UltraData Tiered Data Management](https://arxiv.org/pdf/2602.09003)**, covering three stages: base training, mid-training, and post-training.
|
| 90 |
|
| 91 |
During **base training**, the model goes through stable training and decay training to build core language capability and training stability. It then enters **mid-training** to further strengthen target capabilities and adapt to the target data distribution. The training corpus is released alongside the model as [Ultra-FineWeb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb), [Ultra-FineWeb-L3](https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3), and [UltraData-Math](https://huggingface.co/datasets/openbmb/UltraData-Math).
|
| 92 |
|
| 93 |
During **post-training**, we proceed in three steps: **SFT**, **RL**, and **OPD**. We first use **200B tokens of deep-thinking SFT** and **200B tokens of hybrid-thinking SFT** to establish deep-thinking, hybrid-thinking, and general chat abilities; the SFT data is released as [UltraData-SFT-2605](https://huggingface.co/datasets/openbmb/UltraData-SFT-2605). We then train specialized **RL teachers** for math, code, closed-book QA, writing, and related domains, and use **On-Policy Distillation (OPD)** to distill these teachers back into one release model.
|
| 94 |
|
| 95 |
+

|
| 96 |
|
| 97 |
### What does RL + OPD bring?
|
| 98 |
|
| 99 |
**RL + OPD** is a key part of MiniCPM5-1B post-training. On math, code and instruction-following tasks, RL + OPD raises the average score by **↑16 points** while cutting the share of responses that hit the max-tokens budget by **↓29 percentage points**. The figures below show the two-stage Reasoning RL pipeline, score gains, and the drop in overlong responses.
|
| 100 |
|
| 101 |
+
**RL** combines complementary training signals for reasoning, closed-book QA, writing, instruction following, long-context understanding, and general dialogue. Reasoning RL is based on [DAPO-Math-17k](https://huggingface.co/datasets/BytedTsinghua-SIA/DAPO-Math-17k), follows the minimalist recipe of [JustRL](https://arxiv.org/pdf/2512.16649), and further adds a two-stage length schedule to reduce overlong responses while improving reasoning accuracy. We also use [TriviaQA](https://huggingface.co/datasets/mandarjoshi/trivia_qa), [NQ-Open](https://huggingface.co/datasets/google-research-datasets/nq_open), [LongWriter-Zero-RLData](https://huggingface.co/datasets/THU-KEG/LongWriter-Zero-RLData), synthesized verifiable RLVR data, and pair-wise RLHF signals to improve reliability, instruction following, and user experience.
|
| 102 |
|
| 103 |
+

|
| 104 |
|
| 105 |
**OPD** builds on Thinking Machines Lab's [On-Policy Distillation](https://thinkingmachines.ai/blog/on-policy-distillation/) and incorporates implementation improvements from [Rethinking On-Policy Distillation](https://arxiv.org/pdf/2604.13016). In the RL framework, we use reverse KL divergence as the advantage estimate, replacing the original verification-based advantage. At each response position, we take top-k logits from both the student and teacher models, compute reverse KL on the union of the two token sets, and balance the accuracy of the RKL signal with training efficiency. OPD reuses the in-domain prompts used to train each RL teacher as distillation data, so no additional data curation is required.
|
| 106 |
|
| 107 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 108 |
|
| 109 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
## Quickstart
|
| 112 |
|
| 113 |
+
### vLLM
|
| 114 |
|
| 115 |
```bash
|
| 116 |
+
pip install "vllm>=0.21"
|
| 117 |
+
vllm serve openbmb/MiniCPM5-1B --port 8000
|
| 118 |
```
|
| 119 |
|
| 120 |
+
```bash
|
| 121 |
+
curl http://localhost:8000/v1/chat/completions \
|
| 122 |
+
-H "Content-Type: application/json" \
|
| 123 |
+
-d '{
|
| 124 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 125 |
+
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
|
| 126 |
+
"max_tokens": 128,
|
| 127 |
+
"temperature": 0.7
|
| 128 |
+
}'
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
### SGLang
|
| 132 |
|
| 133 |
```bash
|
| 134 |
+
pip install "sglang[srt]>=0.5.12"
|
| 135 |
+
python -m sglang.launch_server --model-path openbmb/MiniCPM5-1B --port 30000
|
| 136 |
```
|
| 137 |
|
| 138 |
```bash
|
| 139 |
+
curl http://localhost:30000/v1/chat/completions \
|
| 140 |
-H "Content-Type: application/json" \
|
| 141 |
-d '{
|
| 142 |
+
"model": "openbmb/MiniCPM5-1B",
|
| 143 |
+
"messages": [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}],
|
| 144 |
+
"max_tokens": 128,
|
| 145 |
+
"temperature": 0.7
|
|
|
|
| 146 |
}'
|
| 147 |
```
|
| 148 |
|
| 149 |
+
### Transformers
|
|
|
|
|
|
|
| 150 |
|
| 151 |
+
```bash
|
| 152 |
+
pip install -U "transformers>=5.6" accelerate torch
|
| 153 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 154 |
|
| 155 |
+
```python
|
| 156 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 157 |
+
|
| 158 |
+
model_id = "openbmb/MiniCPM5-1B"
|
| 159 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 160 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 161 |
+
model_id,
|
| 162 |
+
torch_dtype="auto",
|
| 163 |
+
device_map="auto",
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
messages = [{"role": "user", "content": "Who are you? Please briefly introduce yourself."}]
|
| 167 |
+
inputs = tokenizer.apply_chat_template(
|
| 168 |
+
messages,
|
| 169 |
+
tokenize=True,
|
| 170 |
+
add_generation_prompt=True,
|
| 171 |
+
enable_thinking=False,
|
| 172 |
+
return_tensors="pt",
|
| 173 |
+
).to(model.device)
|
| 174 |
+
|
| 175 |
+
outputs = model.generate(inputs, max_new_tokens=128)
|
| 176 |
+
print(tokenizer.decode(outputs[0][inputs.shape[-1]:], skip_special_tokens=True))
|
| 177 |
+
```
|
| 178 |
|
| 179 |
Recommended chat template sampling:
|
| 180 |
|
|
|
|
| 200 |
|
| 201 |
| Backend | Model format / use case | Cookbook | Agent Skill |
|
| 202 |
| --- | --- | --- | --- |
|
| 203 |
+
| Transformers | BF16 / FP16 local Python inference, GPU + CPU | [transformers.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/transformers.md) | [minicpm5-deploy-transformers](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-transformers/SKILL.md) |
|
| 204 |
+
| vLLM | BF16 / FP16 OpenAI server | [vllm.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/vllm.md) | [minicpm5-deploy-vllm](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-vllm/SKILL.md) |
|
| 205 |
+
| SGLang | BF16 / FP16 OpenAI server, recommended for tool calling | [sglang.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/sglang.md) | [minicpm5-deploy-sglang](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-sglang/SKILL.md) |
|
| 206 |
+
| llama.cpp | GGUF local inference, CPU/GPU | [llama_cpp.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/llama_cpp.md) | [minicpm5-deploy-llama-cpp](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-llama-cpp/SKILL.md) |
|
| 207 |
+
| Ollama | GGUF local on-device runtime | [ollama.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/ollama.md) | [minicpm5-deploy-ollama](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-ollama/SKILL.md) |
|
| 208 |
+
| LM Studio | GGUF Mac desktop app and OpenAI server | [lmstudio.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/lmstudio.md) | [minicpm5-deploy-lmstudio](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-lmstudio/SKILL.md) |
|
| 209 |
+
| MLX | MLX / 4bit local inference on Apple Silicon | [mlx.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/mlx.md) | [minicpm5-deploy-mlx](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-mlx/SKILL.md) |
|
| 210 |
+
| ArcLight | GGUF local on-device, CPU, Desktop & Server | [arclight.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/deployment/arclight.md) | [minicpm5-deploy-arclight](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-deploy-arclight/SKILL.md) |
|
| 211 |
|
| 212 |
### Fine-tuning
|
| 213 |
|
| 214 |
| Framework | Use case | Cookbook | Agent Skill |
|
| 215 |
| --- | --- | --- | --- |
|
| 216 |
+
| TRL + PEFT | LoRA / SFT fine-tuning | [trl.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/trl.md) | [minicpm5-finetune-trl](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-trl/SKILL.md) |
|
| 217 |
+
| LLaMA-Factory | Fine-tuning | [llamafactory.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/llamafactory.md) | [minicpm5-finetune-llamafactory](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-llamafactory/SKILL.md) |
|
| 218 |
+
| ms-swift | Fine-tuning | [ms_swift.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/ms_swift.md) | [minicpm5-finetune-ms-swift](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-ms-swift/SKILL.md) |
|
| 219 |
+
| unsloth | Fine-tuning | [unsloth.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/unsloth.md) | [minicpm5-finetune-unsloth](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-unsloth/SKILL.md) |
|
| 220 |
+
| xtuner | Fine-tuning | [xtuner.md](https://github.com/OpenBMB/MiniCPM/blob/main/docs/finetune/xtuner.md) | [minicpm5-finetune-xtuner](https://github.com/OpenBMB/MiniCPM/blob/main/skills/minicpm5-finetune-xtuner/SKILL.md) |
|
| 221 |
+
|
| 222 |
+
### Other Supported Frameworks
|
| 223 |
+
|
| 224 |
+
In addition to the deployment and fine-tuning frameworks listed above, MiniCPM5-1B is also supported by FlagOS for multi-chip deployment.
|
| 225 |
+
|
| 226 |
+
#### FlagOS Overview
|
| 227 |
+
|
| 228 |
+
To enable large-scale deployment across different AI chips, Beijing Zhiyuan Research Institute, together with numerous research institutions, chip manufacturers, system vendors, and algorithm and software organizations both domestically and internationally, jointly initiated and established the FlagOS Open Source Community.
|
| 229 |
+
|
| 230 |
+
The FlagOS community is dedicated to building a unified, open-source system software stack for various AI chips, encompassing core open-source projects such as a large-scale operator library, a unified AI compiler, parallel training and inference frameworks, and a unified communication library. It aims to create an open technology ecosystem connecting the “model-system-chip” layers. By enabling “develop once, deploy across chips”, FlagOS unlocks the computational potential of hardware, breaks down the ecosystem silos between different chip software stacks, and effectively reduces migration costs for developers.The FlagOS community fosters an AI hardware and software ecosystem, overcomes single-vendor closed-source monopolies, promotes widespread deployment of AI hardware technologies, and is committed to rooted in China while embracing global collaboration.
|
| 231 |
+
|
| 232 |
+
Official website express: [https://flagos.io](https://flagos.io/)
|
| 233 |
+
|
| 234 |
+
<details>
|
| 235 |
+
<summary>FlagOS multi-chip support and usage</summary>
|
| 236 |
+
|
| 237 |
+
#### FlagOS: Supporting Multiple AI Chips
|
| 238 |
+
|
| 239 |
+
Thanks to FlagOS’s unified multi-chip AI system software stack, MiniCPM5-1B was adapted to 4–5 different AI chips in an extremely short time. Currently, the multi-chip version of MiniCPM5-1B has been released on FlagRelease, FlagOS’s platform for automatic migration, adaptation, and deployment of large models across multi-architecture AI chips. Details are as follows:
|
| 240 |
+
|
| 241 |
+
|Vendor|ModelScope|Huggingface|
|
| 242 |
+
|---|---|---|
|
| 243 |
+
|Nvidia|[MiniCPM5-1B-nvidia-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 244 |
+
|Hygon|[MiniCPM5-1B-hygon-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|[MiniCPM5-1B-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|
|
| 245 |
+
|Metax|[MiniCPM5-1B-metax-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-metax-FlagOS)|[MiniCPM5-1B-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-metax-FlagOS)|
|
| 246 |
+
|Iluvatar|[MiniCPM5-1B-iluvatar-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|[MiniCPM5-1B-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|
|
| 247 |
+
|Zhenwu|[MiniCPM5-1B-zhenwu-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|[MiniCPM5-1B-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|
|
| 248 |
+
|Mthreads|[MiniCPM5-1B-mthreads-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|[MiniCPM5-1B-mthreads-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|
|
| 249 |
+
|Kunlunxin|[MiniCPM5-1B-kunlunxin-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|[MiniCPM5-1B-kunlunxin-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|
|
| 250 |
+
|Ascend|[MiniCPM5-1B-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|[MiniCPM5-1B-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|
|
| 251 |
+
|ARM-v9|[MiniCPM5-1B-Armv9-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|[MiniCPM5-1B-Armv9-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|
|
| 252 |
+
|
| 253 |
+
#### FlagOS Usage
|
| 254 |
+
|
| 255 |
+
##### FlagOS Performance Acceleration on Nvidia
|
| 256 |
+
|
| 257 |
+
###### From FlagRelease (**Recommendation**)
|
| 258 |
+
|
| 259 |
+
FlagRelease is a platform developed by the FlagOS team for automatic migration, adaptation, and deployment of large models across multi-architecture AI chips. The multi-chip version of MiniCPM5-1B has already been released on FlagRelease. All necessary software packages are pre-installed on the platform, so users do not need to install anything.
|
| 260 |
+
|
| 261 |
+
###### FlagRelease Image Key Versions
|
| 262 |
+
|
| 263 |
+
###### FlagRelease Quick Start
|
| 264 |
+
|
| 265 |
+
|Vendor|ModelScope|Huggingface|
|
| 266 |
+
|---|---|---|
|
| 267 |
+
|Nvidia|[MiniCPM5-1B-nvidia-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 268 |
+
|Hygon|[MiniCPM5-1B-hygon-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|[MiniCPM5-1B-hygon-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-hygon-FlagOS)|
|
| 269 |
+
|Metax|[MiniCPM5-1B-metax-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-metax-FlagOS)|[MiniCPM5-1B-metax-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-metax-FlagOS)|
|
| 270 |
+
|Iluvatar|[MiniCPM5-1B-iluvatar-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|[MiniCPM5-1B-iluvatar-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-iluvatar-FlagOS)|
|
| 271 |
+
|Zhenwu|[MiniCPM5-1B-zhenwu-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|[MiniCPM5-1B-zhenwu-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-zhenwu-FlagOS)|
|
| 272 |
+
|Mthreads|[MiniCPM5-1B-mthreads-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|[MiniCPM5-1B-mthreads-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-mthreads-FlagOS)|
|
| 273 |
+
|Kunlunxin|[MiniCPM5-1B-kunlunxin-FlagOS](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|[MiniCPM5-1B-kunlunxin-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-kunlunxin-FlagOS)|
|
| 274 |
+
|Ascend|[MiniCPM5-1B-ascend-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|[MiniCPM5-1B-ascend-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-ascend-FlagOS)|
|
| 275 |
+
|ARM-v9|[MiniCPM5-1B-Armv9-FlagOS](https://modelscope.cn/models/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|[MiniCPM5-1B-Armv9-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-Armv9-FlagOS)|
|
| 276 |
+
|
| 277 |
+
###### From Scratch
|
| 278 |
+
|
| 279 |
+
- Dependencies: Python 3.12, GLIBC 2.39, GLIBCXX 3.4.33, CXXABI 1.3.15
|
| 280 |
+
|
| 281 |
+
###### Vllm Version
|
| 282 |
+
|
| 283 |
+
###### Installing the FlagOS Operator Library
|
| 284 |
+
|
| 285 |
+
Official Repository: https://github.com/flagos-ai/FlagGems
|
| 286 |
+
|
| 287 |
+
```PowerShell
|
| 288 |
+
pip install flag-gems==4.2.1rc0
|
| 289 |
+
pip install triton==3.5.1
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
###### Activating Acceleration
|
| 293 |
+
|
| 294 |
+
You can enable flagGems acceleration by adding the import of flagGems in the source code of vllm where inference is performed.
|
| 295 |
+
|
| 296 |
+
```Bash
|
| 297 |
+
import flag_gems
|
| 298 |
+
flag_gems.enable(record=True, once=True, path="/root/gems.txt")
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
```PowerShell
|
| 302 |
+
vllm serve ${model_path} \
|
| 303 |
+
--trust-remote-code \
|
| 304 |
+
--dtype bfloat16 \
|
| 305 |
+
--enforce-eager \
|
| 306 |
+
--port ${Port} \
|
| 307 |
+
--served-model-name ${model_name} \
|
| 308 |
+
--gpu-memory-utilization 0.85
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
##### Using FlagOS Unified Multi-Chip Backend Plugin
|
| 312 |
+
|
| 313 |
+
[**vllm-plugin-FL**](https://github.com/flagos-ai/vllm-plugin-FL) is a plugin built for the vLLM inference/service framework. Developed on top of FlagOS’s unified multi-chip backend, it is designed to extend vLLM’s capabilities and performance across a variety of hardware environments.
|
| 314 |
+
|
| 315 |
+
###### Using vllm-plugin-FL
|
| 316 |
+
|
| 317 |
+
|Vendor|From Scratch|From FlagRelease||
|
| 318 |
+
|---|---|---|---|
|
| 319 |
+
|Nvidia|[vllm-plugin-FL/MiniCPM5-1B](https://github.com/flagos-ai/vllm-plugin-FL/blob/main/examples/minicpm/README.md)|[MiniCPM5-1B-ModelScope](https://www.modelscope.cn/models/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|[MiniCPM5-1B-nvidia-FlagOS](https://huggingface.co/FlagRelease/MiniCPM5-1B-nvidia-FlagOS)|
|
| 320 |
+
|
| 321 |
+
</details>
|
| 322 |
|
| 323 |
## Desktop Pet
|
| 324 |
|
| 325 |
We also ship **[OpenBMB/MiniCPM-Desk-Pet](https://github.com/OpenBMB/MiniCPM-Desk-Pet)**, a desktop pet driven locally by MiniCPM5-1B. It supports Apple Silicon / NVIDIA GPU / CPU paths, can work with coding agents such as Cursor, Claude Code, and Codex, and supports LoRA persona switching.
|
| 326 |
|
| 327 |
+
<a href="https://youtu.be/Ee0slMW8SEk"><img src="https://img.youtube.com/vi/Ee0slMW8SEk/0.jpg" alt="MiniCPM Desk Pet video demo" width="720"></a>
|
| 328 |
+
|
| 329 |
## Limitations and Responsible Use
|
| 330 |
|
| 331 |
MiniCPM5-1B is a language model that generates content based on learned statistical patterns from training data. It may produce inaccurate, biased, or unsafe outputs, and generated content should be reviewed and verified before use in high-stakes settings.
|