
Upload model
Browse files- .gitattributes +8 -0
- LICENSE +43 -0
- README.md +10 -0
- __pycache__/miner.cpython-312.pyc +0 -0
- chat_template.jinja +74 -0
- chute_config.yml +27 -0
- config.json +43 -0
- emergent-tts-emotions-win-rate.png +3 -0
- generation_config.json +16 -0
- higgs_audio_tokenizer_architecture.png +3 -0
- higgs_audio_v2_architecture_combined.png +3 -0
- higgs_audio_v2_open_source_delay_pattern.png +0 -0
- miner.py +170 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors +3 -0
- model.safetensors.index.json +404 -0
- open_source_repo_demo.mp4 +3 -0
- processor_config.json +22 -0
- special_tokens_map.json +16 -0
- tokenizer.json +3 -0
- tokenizer_config.json +16 -0
- vocence_config.yaml +18 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,11 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model-00001-of-00003.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model-00002-of-00003.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
model-00003-of-00003.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
emergent-tts-emotions-win-rate.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
higgs_audio_tokenizer_architecture.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
higgs_audio_v2_architecture_combined.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
open_source_repo_demo.mp4 filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BOSON HIGGS AUDIO 2 COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Boson Higgs Audio 2 Version Release Date: June 20, 2025
|
| 4 |
+
|
| 5 |
+
This License Agreement (the “Agreement”) is entered into by and between Licensee (as defined below) and Boson AI USA, Inc. (“Boson”) and is based upon the Meta Llama 3 Community License Agreement as of April 18, 2024 (the “Meta License Agreement”), which can be found at https://llama.meta.com/llama3/license/. The terms and conditions of the Meta License Agreement are hereby incorporated herein by reference and Unless stated otherwise below, its terms apply. The Higgs Audio 2 model developed by Boson AI USA, Inc. (“Higgs Materials”) is an audio model derived from Meta Llama 3 software and algorithms.
|
| 6 |
+
|
| 7 |
+
“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Higgs Materials set forth herein and the Meta License Agreement.
|
| 8 |
+
|
| 9 |
+
“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering into this Agreement on their behalf.
|
| 10 |
+
|
| 11 |
+
“Higgs Audio 2” means the foundational large audio language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing developed by Boson AI distributed at https://github.com/boson-ai/boson-multimodal or otherwise.
|
| 12 |
+
“Higgs Materials” means, collectively, Boson’s proprietary modification of Meta Llama 3 and Documentation (and any portion thereof) made available under this Agreement.
|
| 13 |
+
|
| 14 |
+
“Boson” or “we” means Boson AI USA, Inc.
|
| 15 |
+
|
| 16 |
+
By clicking “I Accept” below or by using or distributing any portion or element of the Higgs Materials, you agree to be bound by this Agreement.
|
| 17 |
+
|
| 18 |
+
1. License Rights and Redistribution.
|
| 19 |
+
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Boson’s intellectual property or other rights owned by Boson embodied in the Higgs Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Higgs Materials.
|
| 20 |
+
b. Redistribution and Use.
|
| 21 |
+
i. If you distribute or make available the Higgs Materials (or any derivative works thereof), or a product or service that uses any of them, including another AI model, you shall (A) provide a copy of this Agreement and the of Meta License ’s Llama 3 agreement with any such Higgs Materials; and (B) prominently display “Built with Higgs Materials licensed from Boson AI USA, Inc., Copyright Boson AI USA, Inc., All Rights Reserved and Meta Llama 3 licensed under the Meta Llama 3 Community License, Copyright Meta Platforms, Inc., All Right Reserved". based on Meta Llama 3” on a related website, user interface, blogpost, about page, or product documentation. If you use the Higgs Materials to create, modify, enhance, train, fine tune, or otherwise improve an AI model or similar software, which is distributed or made available, you shall also include “Higgs Audio 2” at the beginning of any such AI model or software name.
|
| 22 |
+
ii. Even if you receive Higgs Materials, or any modifications, enhancements or derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will apply to you.
|
| 23 |
+
iii. You must retain in all copies of the Llama Materials that you distribute and as set forth above, include the following attribution notice within a “Notice” text file distributed as a part of such copies:
|
| 24 |
+
“Meta Llama 3 is licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”
|
| 25 |
+
“Boson Higgs Audio 2 is licensed under the Boson Community License, Copyright © Boson AI USA, Inc. All Rights Reserved.”
|
| 26 |
+
iv. Your use of the Higgs Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference into this Agreement.
|
| 27 |
+
v. You will not use the Higgs Materials or any output or results of the Higgs Materials to improve any other large language model (excluding Boson Higgs Audio 2 or derivative works thereof).
|
| 28 |
+
vi. You hereby acknowledge that Boson is the owner of the Higgs Materials and under no circumstance shall you bring any legal action, claim, charge, demand challenging such ownership rights of Boson.
|
| 29 |
+
|
| 30 |
+
2. Additional Commercial Terms. If the annual active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 100,000 annual active users in the preceding calendar year, you must request an expanded license from Boson AI, which Boson AI may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Boson AI otherwise expressly grants you such rights.
|
| 31 |
+
|
| 32 |
+
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE Higgs Materials AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITH ALL FAULTS, WITHOUT WARRANTIES OF ANY KIND EXPRESS, IMPLIED, BASED UPON CUSTOM AND USAGE OR COURSE OF DEALING, AND BOSON AI DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE HIGGS MATERIALS AND ASSUME ANY AND ALL RISKS ASSOCIATED WITH YOUR USE OF THE HIGGS MATERIALS AND ANY OUTPUT AND RESULTS.
|
| 33 |
+
|
| 34 |
+
4. Limitation of Liability. IN NO EVENT WILL BOSON AI OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF BOSON, META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 35 |
+
|
| 36 |
+
5. Intellectual Property.
|
| 37 |
+
a. No trademark licenses are granted under this Agreement, or in connection with the Higgs Materials., nNeither Boson nor Licensee may use any name or mark owned by, or associated with, the other party hereto or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Higgs Materials or as set forth in this Section 5(a). Boson hereby grants you a license to use “Higgs Audio 2” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. All goodwill arising out of your use of the Mark will inure to the benefit of Meta and Boson AI.
|
| 38 |
+
b. Subject to Boson’s ownership of the Higgs Materials and derivatives made by or for Boson AI, with respect to any derivative works and modifications of the Higgs Materials that are made by you, as between you and Boson AI, you are and will be the owner of such derivative works and modifications.
|
| 39 |
+
c. If you institute litigation or other proceedings against Boson AI, Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Higgs Materials or Boson Higgs Audio 2 outputs or results, or any portion thereof any of the foregoing, constitutes infringement of the intellectual property or other rights owned or licensable by you, then any licenses granted to you hereunder this Agreement shall immediately terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Boson AI from and against any claim, charge, demand, cause of action by any third party arising out of or related to your use or distribution of the Higgs Materials.
|
| 40 |
+
|
| 41 |
+
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Higgs Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Boson AI may terminate this Agreement if you are in breach of any term or condition of this Agreement by providing you with written notice. Upon your receipt of written notice of termination of this Agreement, you shall delete the Higgs Materials from any computer, server or IT device and cease use of the Higgs Materials in all respects. Sections 1(b)(vi), 3, 4 and 7 shall survive the termination of this Agreement.
|
| 42 |
+
|
| 43 |
+
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The federal courts in the Northern District of California and the state courts in Santa Clara County, California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
|
README.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
- de
|
| 7 |
+
- ko
|
| 8 |
+
pipeline_tag: text-to-speech
|
| 9 |
+
library_name: transformers
|
| 10 |
+
---
|
__pycache__/miner.cpython-312.pyc
ADDED
|
Binary file (9.35 kB). View file
|
|
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{{- bos_token }}
|
| 2 |
+
{#- This block extracts the system message, so we can slot it into the right place. #}
|
| 3 |
+
{%- if messages[0]['role'] == 'system' %}
|
| 4 |
+
{%- if messages[0]['content'] is string %}
|
| 5 |
+
{%- set system_message = messages[0]['content']|trim %}
|
| 6 |
+
{%- elif messages[0]['content'] is iterable and messages[0]['content'][0]['type'] == 'text' %}
|
| 7 |
+
{%- set system_message = messages[0]['content'][0]['text']|trim %}
|
| 8 |
+
{%- else %}
|
| 9 |
+
{{- raise_exception("System message content must be a string or contain text type!") }}
|
| 10 |
+
{%- endif %}
|
| 11 |
+
{%- set messages = messages[1:] %}
|
| 12 |
+
{%- else %}
|
| 13 |
+
{{- raise_exception("A system message is required but not provided!") }}
|
| 14 |
+
{%- endif %}
|
| 15 |
+
|
| 16 |
+
{#- System message #}
|
| 17 |
+
{{- "<|start_header_id|>system<|end_header_id|>\n\n" }}
|
| 18 |
+
{{- system_message }}
|
| 19 |
+
|
| 20 |
+
{#- Check for scene message and handle it specially #}
|
| 21 |
+
{%- if messages and messages[0]['role'] == 'scene' %}
|
| 22 |
+
{{- "\n\n<|scene_desc_start|>\n" }}
|
| 23 |
+
{%- if messages[0]['content'] is string %}
|
| 24 |
+
{{- messages[0]['content'] | trim }}
|
| 25 |
+
{%- elif messages[0]['content'] is iterable %}
|
| 26 |
+
{%- for content_item in messages[0]['content'] %}
|
| 27 |
+
{%- if content_item['type'] == 'text' %}
|
| 28 |
+
{%- set text_content = content_item['text'] | trim %}
|
| 29 |
+
{{- text_content }}
|
| 30 |
+
{%- if loop.first and not loop.last %}
|
| 31 |
+
{{- "\n\n" }}
|
| 32 |
+
{%- endif %}
|
| 33 |
+
{%- if not loop.first and not loop.last and messages[0]['content'][loop.index]['type'] != 'audio' %}
|
| 34 |
+
{{- "\n" }}
|
| 35 |
+
{%- endif %}
|
| 36 |
+
{%- elif content_item['type'] == 'audio' %}
|
| 37 |
+
{{- ' <|audio_out_bos|><|AUDIO_OUT|><|audio_eos|>' }}
|
| 38 |
+
{%- if not loop.last %}
|
| 39 |
+
{{- "\n" }}
|
| 40 |
+
{%- endif %}
|
| 41 |
+
{%- endif %}
|
| 42 |
+
{%- endfor %}
|
| 43 |
+
{%- endif %}
|
| 44 |
+
{{- "\n<|scene_desc_end|>" }}
|
| 45 |
+
{%- set messages = messages[1:] %}
|
| 46 |
+
{%- endif %}
|
| 47 |
+
|
| 48 |
+
{{- "<|eot_id|>" }}
|
| 49 |
+
|
| 50 |
+
{#- Loop through all messages #}
|
| 51 |
+
{%- for message in messages %}
|
| 52 |
+
{{- '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n' }}
|
| 53 |
+
{%- if message['role'] == 'assistant' %}
|
| 54 |
+
{%- if message['content'] is not iterable or message['content'][0]['type'] != 'audio' %}
|
| 55 |
+
{{- raise_exception("Assistant messages must contain audio content only!") }}
|
| 56 |
+
{%- endif %}
|
| 57 |
+
{{- '<|audio_out_bos|><|AUDIO_OUT|><|audio_eos|>' }}
|
| 58 |
+
{%- else %}
|
| 59 |
+
{%- if message['content'] is string %}
|
| 60 |
+
{{- message['content'] | trim }}
|
| 61 |
+
{%- elif message['content'] is iterable %}
|
| 62 |
+
{%- for content_item in message['content'] %}
|
| 63 |
+
{%- if content_item['type'] == 'text' %}
|
| 64 |
+
{{- content_item['text'] | trim }}
|
| 65 |
+
{%- endif %}
|
| 66 |
+
{%- endfor %}
|
| 67 |
+
{%- endif %}
|
| 68 |
+
{%- endif %}
|
| 69 |
+
{{- '<|eot_id|>' }}
|
| 70 |
+
{%- endfor %}
|
| 71 |
+
|
| 72 |
+
{%- if add_generation_prompt %}
|
| 73 |
+
{{- '<|start_header_id|>assistant<|end_header_id|>\n\n<|audio_out_bos|>' }}
|
| 74 |
+
{%- endif %}
|
chute_config.yml
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Vocence chute config for Higgs Audio v2 (example_repo/miner.py) — build-time only.
|
| 2 |
+
# Generation + tokenizer weights: HF snapshot (repo) at runtime; image installs PyTorch + Transformers.
|
| 3 |
+
|
| 4 |
+
Image:
|
| 5 |
+
from_base: parachutes/base-python:3.12.9
|
| 6 |
+
set_user: root
|
| 7 |
+
run_command:
|
| 8 |
+
# Optional if you use processor.save_audio / soundfile-backed I/O elsewhere.
|
| 9 |
+
- apt-get update && apt-get install -y --no-install-recommends libsndfile1 && rm -rf /var/lib/apt/lists/*
|
| 10 |
+
# Match your Chutes CUDA major: cu124 → cu126 / cu128 on pytorch.org if needed.
|
| 11 |
+
- pip install --no-cache-dir "transformers>=5.3.0"
|
| 12 |
+
- pip install --no-cache-dir "transformers>=4.53.0" accelerate huggingface_hub safetensors pyyaml soundfile
|
| 13 |
+
- pip install --no-cache-dir numpy einops scipy tqdm protobuf sentencepiece filelock packaging regex requests
|
| 14 |
+
|
| 15 |
+
NodeSelector:
|
| 16 |
+
gpu_count: 1
|
| 17 |
+
min_vram_gb_per_gpu: 24
|
| 18 |
+
include: ['pro_6000']
|
| 19 |
+
|
| 20 |
+
Chute:
|
| 21 |
+
tagline: Vocence PromptTTS — Higgs Audio v2 (miner.py)
|
| 22 |
+
readme: Higgs Audio v2 + Vocence Miner; device_map=auto. Set HIGGS_AUDIO_TOKENIZER_REPO or bundle tokenizer under the HF repo if not using default Hub tokenizer.
|
| 23 |
+
shutdown_after_seconds: 86400
|
| 24 |
+
concurrency: 1
|
| 25 |
+
max_instances: 1
|
| 26 |
+
scaling_threshold: 0.5
|
| 27 |
+
tee: true
|
config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"HiggsAudioV2ForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"audio_bos_token_id": 128013,
|
| 8 |
+
"audio_delay_token_id": 128014,
|
| 9 |
+
"audio_stream_bos_id": 1024,
|
| 10 |
+
"audio_stream_eos_id": 1025,
|
| 11 |
+
"audio_token_id": 128016,
|
| 12 |
+
"bos_token_id": 1,
|
| 13 |
+
"codebook_size": 1026,
|
| 14 |
+
"dtype": "bfloat16",
|
| 15 |
+
"eos_token_id": 128009,
|
| 16 |
+
"head_dim": 128,
|
| 17 |
+
"hidden_act": "silu",
|
| 18 |
+
"hidden_size": 3072,
|
| 19 |
+
"initializer_range": 0.02,
|
| 20 |
+
"intermediate_size": 8192,
|
| 21 |
+
"max_position_embeddings": 2048,
|
| 22 |
+
"mlp_bias": false,
|
| 23 |
+
"model_type": "higgs_audio_v2",
|
| 24 |
+
"num_attention_heads": 24,
|
| 25 |
+
"num_codebooks": 8,
|
| 26 |
+
"num_hidden_layers": 28,
|
| 27 |
+
"num_key_value_heads": 8,
|
| 28 |
+
"pad_token_id": 128001,
|
| 29 |
+
"pretraining_tp": 1,
|
| 30 |
+
"rms_norm_eps": 1e-05,
|
| 31 |
+
"rope_parameters": {
|
| 32 |
+
"factor": 32.0,
|
| 33 |
+
"high_freq_factor": 0.5,
|
| 34 |
+
"low_freq_factor": 0.125,
|
| 35 |
+
"original_max_position_embeddings": 1024,
|
| 36 |
+
"rope_theta": 500000.0,
|
| 37 |
+
"rope_type": "llama3"
|
| 38 |
+
},
|
| 39 |
+
"tie_word_embeddings": false,
|
| 40 |
+
"transformers_version": "5.3.0.dev0",
|
| 41 |
+
"use_cache": true,
|
| 42 |
+
"vocab_size": 128256
|
| 43 |
+
}
|
emergent-tts-emotions-win-rate.png
ADDED

|
Git LFS Details
|
generation_config.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 1,
|
| 3 |
+
"eos_token_id": 128009,
|
| 4 |
+
"output_attentions": false,
|
| 5 |
+
"output_hidden_states": false,
|
| 6 |
+
"pad_token_id": 128001,
|
| 7 |
+
"ras_win_len": 7,
|
| 8 |
+
"ras_win_max_num_repeat": 2,
|
| 9 |
+
"transformers_version": "5.3.0.dev0",
|
| 10 |
+
"use_cache": true,
|
| 11 |
+
"use_text_head": true,
|
| 12 |
+
"do_sample": true,
|
| 13 |
+
"temperature": 1.0,
|
| 14 |
+
"top_k": 50,
|
| 15 |
+
"top_p": 0.95
|
| 16 |
+
}
|
higgs_audio_tokenizer_architecture.png
ADDED

|
Git LFS Details
|
higgs_audio_v2_architecture_combined.png
ADDED

|
Git LFS Details
|
higgs_audio_v2_open_source_delay_pattern.png
ADDED
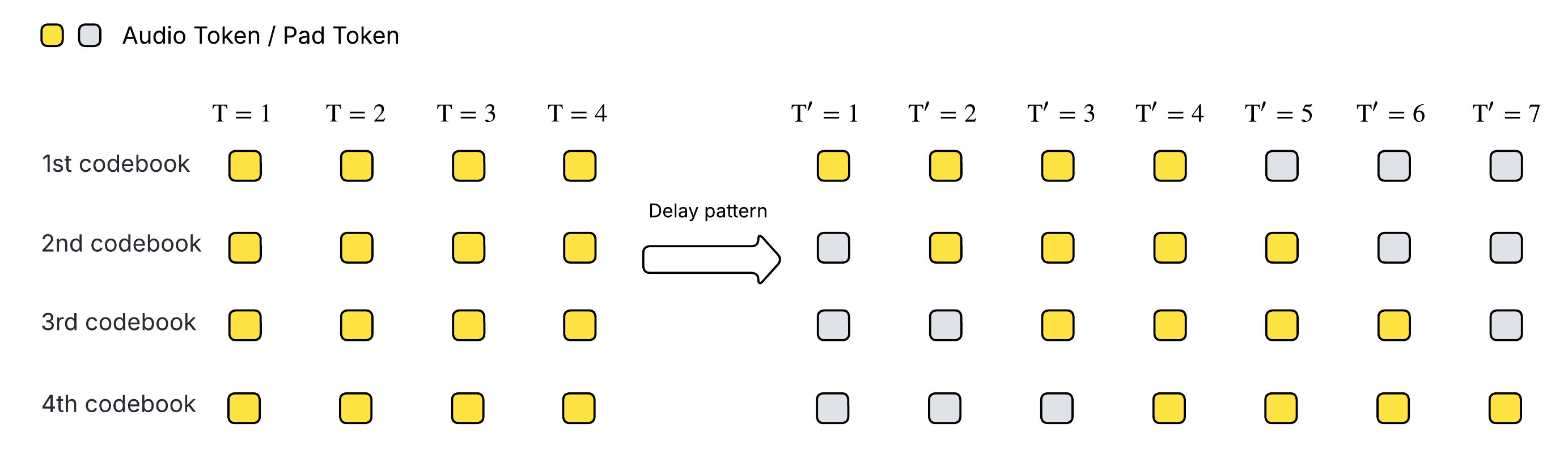
|
miner.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Higgs Audio v2 — Vocence ``Miner`` (Chutes ``POST /speak``: ``instruction`` + ``text``).
|
| 3 |
+
|
| 4 |
+
Loads **generation** weights from ``path_hf_repo`` (HF snapshot root passed by the chute).
|
| 5 |
+
Loads **audio tokenizer** from, in order: ``HIGGS_AUDIO_TOKENIZER_REPO`` env,
|
| 6 |
+
``vocence_config.yaml`` ``runtime.audio_tokenizer_repo``, a local directory
|
| 7 |
+
``higgs-audio-v2-tokenizer`` or ``audio_tokenizer`` under the repo (with ``config.json``),
|
| 8 |
+
else Hub ``eustlb/higgs-audio-v2-tokenizer``.
|
| 9 |
+
|
| 10 |
+
The Hub repo ``bosonai/higgs-audio-v2-tokenizer`` ships weights that do not match
|
| 11 |
+
``HiggsAudioV2TokenizerModel`` for this stack; prefer ``eustlb`` tokenizer weights unless
|
| 12 |
+
you know your files match.
|
| 13 |
+
|
| 14 |
+
Optional env: ``HIGGS_MODEL_REPO`` — if set, overrides ``path_hf_repo`` for the generation model only.
|
| 15 |
+
"""
|
| 16 |
+
from __future__ import annotations
|
| 17 |
+
|
| 18 |
+
import os
|
| 19 |
+
from pathlib import Path
|
| 20 |
+
from typing import Any
|
| 21 |
+
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
from transformers import (
|
| 25 |
+
AutoProcessor,
|
| 26 |
+
HiggsAudioV2ForConditionalGeneration,
|
| 27 |
+
HiggsAudioV2TokenizerModel,
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def default_hf_repo_root() -> Path:
|
| 32 |
+
"""Directory containing ``miner.py`` (HF snapshot layout: config, weights, …)."""
|
| 33 |
+
return Path(__file__).resolve().parent
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def _load_yaml_config(repo: Path) -> dict[str, Any]:
|
| 37 |
+
path = repo / "vocence_config.yaml"
|
| 38 |
+
if not path.is_file():
|
| 39 |
+
return {}
|
| 40 |
+
try:
|
| 41 |
+
import yaml
|
| 42 |
+
|
| 43 |
+
with path.open(encoding="utf-8") as f:
|
| 44 |
+
data = yaml.safe_load(f)
|
| 45 |
+
return data if isinstance(data, dict) else {}
|
| 46 |
+
except Exception:
|
| 47 |
+
return {}
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _resolve_audio_tokenizer_source(repo: Path, cfg: dict[str, Any]) -> str:
|
| 51 |
+
env = (os.environ.get("HIGGS_AUDIO_TOKENIZER_REPO") or "").strip()
|
| 52 |
+
if env:
|
| 53 |
+
return env
|
| 54 |
+
runtime = cfg.get("runtime") or {}
|
| 55 |
+
r = runtime.get("audio_tokenizer_repo")
|
| 56 |
+
if isinstance(r, str) and r.strip():
|
| 57 |
+
return r.strip()
|
| 58 |
+
for name in ("higgs-audio-v2-tokenizer", "audio_tokenizer"):
|
| 59 |
+
p = (repo / name).resolve()
|
| 60 |
+
if p.is_dir() and (p / "config.json").is_file():
|
| 61 |
+
return str(p)
|
| 62 |
+
return "eustlb/higgs-audio-v2-tokenizer"
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def _resolve_generation_model_id(repo: Path) -> str:
|
| 66 |
+
return (os.environ.get("HIGGS_MODEL_REPO") or "").strip() or str(repo)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class Miner:
|
| 70 |
+
"""Higgs Audio v2: ``generate_wav(instruction, text)`` → mono float32 PCM + sample rate."""
|
| 71 |
+
|
| 72 |
+
def __init__(self, path_hf_repo: Path | str | os.PathLike[str] | None = None) -> None:
|
| 73 |
+
self._repo_path = (
|
| 74 |
+
Path(path_hf_repo).resolve()
|
| 75 |
+
if path_hf_repo is not None
|
| 76 |
+
else default_hf_repo_root()
|
| 77 |
+
)
|
| 78 |
+
self._cfg = _load_yaml_config(self._repo_path)
|
| 79 |
+
gen = self._cfg.get("generation") or {}
|
| 80 |
+
lim = self._cfg.get("limits") or {}
|
| 81 |
+
|
| 82 |
+
self._max_new_tokens = int(gen.get("max_new_tokens", 1000))
|
| 83 |
+
self._do_sample = bool(gen.get("do_sample", False))
|
| 84 |
+
self._sampling_rate = int(gen.get("sampling_rate", 24000))
|
| 85 |
+
self._max_instruction = int(lim.get("max_instruction_chars", 600))
|
| 86 |
+
self._max_text = int(lim.get("max_text_chars", 2000))
|
| 87 |
+
|
| 88 |
+
model_id = _resolve_generation_model_id(self._repo_path)
|
| 89 |
+
tok_src = _resolve_audio_tokenizer_source(self._repo_path, self._cfg)
|
| 90 |
+
|
| 91 |
+
self._processor = AutoProcessor.from_pretrained(model_id, device_map="auto")
|
| 92 |
+
self._processor.audio_tokenizer = HiggsAudioV2TokenizerModel.from_pretrained(
|
| 93 |
+
tok_src,
|
| 94 |
+
device_map="auto",
|
| 95 |
+
)
|
| 96 |
+
self._model = HiggsAudioV2ForConditionalGeneration.from_pretrained(
|
| 97 |
+
model_id,
|
| 98 |
+
device_map="auto",
|
| 99 |
+
)
|
| 100 |
+
self._model.eval()
|
| 101 |
+
|
| 102 |
+
def _truncate(self, s: str, cap: int) -> str:
|
| 103 |
+
s = (s or "").strip()
|
| 104 |
+
return s[:cap] if len(s) > cap else s
|
| 105 |
+
|
| 106 |
+
def _conversation(self, instruction: str, text: str) -> list[dict[str, Any]]:
|
| 107 |
+
"""Map Vocence ``instruction`` (style / scene) + ``text`` (words to speak) to Higgs chat roles."""
|
| 108 |
+
scene = (
|
| 109 |
+
instruction.strip()
|
| 110 |
+
if instruction.strip()
|
| 111 |
+
else "Audio is recorded from a quiet room with a neutral voice."
|
| 112 |
+
)
|
| 113 |
+
return [
|
| 114 |
+
{
|
| 115 |
+
"role": "system",
|
| 116 |
+
"content": [{"type": "text", "text": "Generate audio following instruction."}],
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"role": "scene",
|
| 120 |
+
"content": [{"type": "text", "text": scene}],
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"role": "user",
|
| 124 |
+
"content": [{"type": "text", "text": text}],
|
| 125 |
+
},
|
| 126 |
+
]
|
| 127 |
+
|
| 128 |
+
def warmup(self) -> None:
|
| 129 |
+
self.generate_wav(
|
| 130 |
+
"A clear, neutral speaking style with moderate pace.",
|
| 131 |
+
"Warmup.",
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
def generate_wav(self, instruction: str, text: str) -> tuple[np.ndarray, int]:
|
| 135 |
+
if not (text or "").strip():
|
| 136 |
+
raise ValueError("text must be non-empty")
|
| 137 |
+
|
| 138 |
+
ins = self._truncate(instruction, self._max_instruction)
|
| 139 |
+
body = self._truncate(text, self._max_text)
|
| 140 |
+
|
| 141 |
+
inputs = self._processor.apply_chat_template(
|
| 142 |
+
self._conversation(ins, body),
|
| 143 |
+
add_generation_prompt=True,
|
| 144 |
+
tokenize=True,
|
| 145 |
+
return_dict=True,
|
| 146 |
+
return_tensors="pt",
|
| 147 |
+
processor_kwargs={"sampling_rate": self._sampling_rate},
|
| 148 |
+
).to(self._model.device)
|
| 149 |
+
|
| 150 |
+
with torch.no_grad():
|
| 151 |
+
outputs = self._model.generate(
|
| 152 |
+
**inputs,
|
| 153 |
+
max_new_tokens=self._max_new_tokens,
|
| 154 |
+
do_sample=self._do_sample,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
decoded_list = self._processor.batch_decode(outputs)
|
| 158 |
+
if not decoded_list:
|
| 159 |
+
raise RuntimeError("Higgs batch_decode returned no audio.")
|
| 160 |
+
|
| 161 |
+
wav_t = decoded_list[0]
|
| 162 |
+
if hasattr(wav_t, "detach"):
|
| 163 |
+
wav = wav_t.detach().cpu().float().numpy()
|
| 164 |
+
else:
|
| 165 |
+
wav = np.asarray(wav_t, dtype=np.float32)
|
| 166 |
+
wav = np.reshape(wav, (-1,)).astype(np.float32, copy=False)
|
| 167 |
+
peak = float(np.max(np.abs(wav))) if wav.size else 0.0
|
| 168 |
+
if peak > 1.0:
|
| 169 |
+
wav = wav / peak
|
| 170 |
+
return wav, int(self._sampling_rate)
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46b461c6658985869a757453a6ba5199d7767c9d3b98b443c154c0771b1b56db
|
| 3 |
+
size 4965820232
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f6654fe31eb9de990bd2734b1cbf85e79966945fa0c9923b15c5c06b073e35e
|
| 3 |
+
size 4983224272
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:02a36e0c47281184ecbee3b9329fc4546a57674d9faca89cb2d3110c4c6bb56b
|
| 3 |
+
size 1593566728
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c896b019ec1a4fc950218e32797c30870d36ce1cd76f45b35de46495764a204
|
| 3 |
+
size 11542613696
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,404 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 11542566912
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"audio_codebook_embeddings.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"audio_decoder_proj.audio_lm_head.weight": "model-00003-of-00003.safetensors",
|
| 8 |
+
"audio_decoder_proj.text_lm_head.weight": "model-00003-of-00003.safetensors",
|
| 9 |
+
"embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"layers.0.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"layers.0.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"layers.0.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"layers.0.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"layers.0.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"layers.1.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"layers.1.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"layers.1.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"layers.1.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"layers.1.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 37 |
+
"layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 38 |
+
"layers.10.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 39 |
+
"layers.10.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 40 |
+
"layers.10.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 41 |
+
"layers.10.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 42 |
+
"layers.10.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 43 |
+
"layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 44 |
+
"layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 45 |
+
"layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 46 |
+
"layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 47 |
+
"layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 48 |
+
"layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 49 |
+
"layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 50 |
+
"layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 51 |
+
"layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 52 |
+
"layers.11.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"layers.11.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"layers.11.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 55 |
+
"layers.11.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 56 |
+
"layers.11.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"layers.11.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 59 |
+
"layers.11.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 60 |
+
"layers.11.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 61 |
+
"layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"layers.11.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 63 |
+
"layers.11.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 64 |
+
"layers.11.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 65 |
+
"layers.11.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 66 |
+
"layers.12.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"layers.12.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"layers.12.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"layers.12.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"layers.12.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"layers.13.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"layers.13.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"layers.13.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"layers.13.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"layers.13.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"layers.14.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"layers.14.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"layers.14.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"layers.14.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"layers.14.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"layers.15.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"layers.15.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"layers.15.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"layers.15.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"layers.15.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 118 |
+
"layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 119 |
+
"layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 120 |
+
"layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 121 |
+
"layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 122 |
+
"layers.16.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 123 |
+
"layers.16.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 124 |
+
"layers.16.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 125 |
+
"layers.16.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"layers.16.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"layers.17.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"layers.17.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"layers.17.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"layers.17.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"layers.17.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"layers.18.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"layers.18.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"layers.18.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"layers.18.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 154 |
+
"layers.18.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 155 |
+
"layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 156 |
+
"layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 157 |
+
"layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 158 |
+
"layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 163 |
+
"layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 164 |
+
"layers.19.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 165 |
+
"layers.19.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 166 |
+
"layers.19.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 167 |
+
"layers.19.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 168 |
+
"layers.19.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 169 |
+
"layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 170 |
+
"layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 171 |
+
"layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 172 |
+
"layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 173 |
+
"layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 174 |
+
"layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 175 |
+
"layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 176 |
+
"layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 177 |
+
"layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 178 |
+
"layers.2.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 179 |
+
"layers.2.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 180 |
+
"layers.2.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 181 |
+
"layers.2.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 182 |
+
"layers.2.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 183 |
+
"layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 184 |
+
"layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 185 |
+
"layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 186 |
+
"layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 187 |
+
"layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 188 |
+
"layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 189 |
+
"layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 190 |
+
"layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 191 |
+
"layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 192 |
+
"layers.20.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 193 |
+
"layers.20.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 194 |
+
"layers.20.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 195 |
+
"layers.20.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 196 |
+
"layers.20.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 197 |
+
"layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 198 |
+
"layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 199 |
+
"layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 200 |
+
"layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 201 |
+
"layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 202 |
+
"layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 203 |
+
"layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 204 |
+
"layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 205 |
+
"layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 206 |
+
"layers.21.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 207 |
+
"layers.21.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 208 |
+
"layers.21.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 209 |
+
"layers.21.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 210 |
+
"layers.21.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 211 |
+
"layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 212 |
+
"layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 213 |
+
"layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 214 |
+
"layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 215 |
+
"layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 216 |
+
"layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 217 |
+
"layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 218 |
+
"layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 219 |
+
"layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 220 |
+
"layers.22.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 221 |
+
"layers.22.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 222 |
+
"layers.22.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 223 |
+
"layers.22.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 224 |
+
"layers.22.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 225 |
+
"layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 226 |
+
"layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 227 |
+
"layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 228 |
+
"layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 229 |
+
"layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 230 |
+
"layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 231 |
+
"layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 232 |
+
"layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 233 |
+
"layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 234 |
+
"layers.23.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 235 |
+
"layers.23.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 236 |
+
"layers.23.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 237 |
+
"layers.23.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 238 |
+
"layers.23.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 239 |
+
"layers.23.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 240 |
+
"layers.23.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 241 |
+
"layers.23.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 242 |
+
"layers.23.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 243 |
+
"layers.23.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 244 |
+
"layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 245 |
+
"layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 246 |
+
"layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 247 |
+
"layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 248 |
+
"layers.24.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 249 |
+
"layers.24.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 250 |
+
"layers.24.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 251 |
+
"layers.24.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 252 |
+
"layers.24.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 253 |
+
"layers.24.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 254 |
+
"layers.24.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 255 |
+
"layers.24.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 256 |
+
"layers.24.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 257 |
+
"layers.24.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 258 |
+
"layers.24.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 259 |
+
"layers.24.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 260 |
+
"layers.24.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 261 |
+
"layers.24.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 262 |
+
"layers.25.audio_input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 263 |
+
"layers.25.audio_mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 264 |
+
"layers.25.audio_mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 265 |
+
"layers.25.audio_mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 266 |
+
"layers.25.audio_post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 267 |
+
"layers.25.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 268 |
+
"layers.25.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 269 |
+
"layers.25.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 270 |
+
"layers.25.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 271 |
+
"layers.25.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 272 |
+
"layers.25.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 273 |
+
"layers.25.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 274 |
+
"layers.25.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 275 |
+
"layers.25.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 276 |
+
"layers.26.audio_input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 277 |
+
"layers.26.audio_mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 278 |
+
"layers.26.audio_mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 279 |
+
"layers.26.audio_mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 280 |
+
"layers.26.audio_post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 281 |
+
"layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 282 |
+
"layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 283 |
+
"layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 284 |
+
"layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 285 |
+
"layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 286 |
+
"layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 287 |
+
"layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 288 |
+
"layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 289 |
+
"layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 290 |
+
"layers.27.audio_input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 291 |
+
"layers.27.audio_mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 292 |
+
"layers.27.audio_mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 293 |
+
"layers.27.audio_mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 294 |
+
"layers.27.audio_post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 295 |
+
"layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 296 |
+
"layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 297 |
+
"layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 298 |
+
"layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 299 |
+
"layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 300 |
+
"layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 301 |
+
"layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 302 |
+
"layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 303 |
+
"layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 304 |
+
"layers.3.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 305 |
+
"layers.3.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 306 |
+
"layers.3.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 307 |
+
"layers.3.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 308 |
+
"layers.3.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 309 |
+
"layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 310 |
+
"layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 311 |
+
"layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 312 |
+
"layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 313 |
+
"layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 314 |
+
"layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 315 |
+
"layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 316 |
+
"layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 317 |
+
"layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 318 |
+
"layers.4.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 319 |
+
"layers.4.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 320 |
+
"layers.4.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 321 |
+
"layers.4.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 322 |
+
"layers.4.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 323 |
+
"layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 324 |
+
"layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 325 |
+
"layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 326 |
+
"layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 327 |
+
"layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 328 |
+
"layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 329 |
+
"layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 330 |
+
"layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 331 |
+
"layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 332 |
+
"layers.5.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 333 |
+
"layers.5.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 334 |
+
"layers.5.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 335 |
+
"layers.5.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 336 |
+
"layers.5.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 337 |
+
"layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 338 |
+
"layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 339 |
+
"layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 340 |
+
"layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 341 |
+
"layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 342 |
+
"layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 343 |
+
"layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 344 |
+
"layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 345 |
+
"layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 346 |
+
"layers.6.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 347 |
+
"layers.6.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 348 |
+
"layers.6.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 349 |
+
"layers.6.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 350 |
+
"layers.6.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 351 |
+
"layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 352 |
+
"layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 353 |
+
"layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 354 |
+
"layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 355 |
+
"layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 356 |
+
"layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 357 |
+
"layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 358 |
+
"layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 359 |
+
"layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 360 |
+
"layers.7.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 361 |
+
"layers.7.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 362 |
+
"layers.7.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 363 |
+
"layers.7.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 364 |
+
"layers.7.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 365 |
+
"layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 366 |
+
"layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 367 |
+
"layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 368 |
+
"layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 369 |
+
"layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 370 |
+
"layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 371 |
+
"layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 372 |
+
"layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 373 |
+
"layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 374 |
+
"layers.8.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 375 |
+
"layers.8.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 376 |
+
"layers.8.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 377 |
+
"layers.8.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 378 |
+
"layers.8.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 379 |
+
"layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 380 |
+
"layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 381 |
+
"layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 382 |
+
"layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 383 |
+
"layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 384 |
+
"layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 385 |
+
"layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 386 |
+
"layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 387 |
+
"layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 388 |
+
"layers.9.audio_input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 389 |
+
"layers.9.audio_mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 390 |
+
"layers.9.audio_mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 391 |
+
"layers.9.audio_mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 392 |
+
"layers.9.audio_post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 393 |
+
"layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 394 |
+
"layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 395 |
+
"layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 396 |
+
"layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 397 |
+
"layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 398 |
+
"layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 399 |
+
"layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 400 |
+
"layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 401 |
+
"layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 402 |
+
"norm.weight": "model-00003-of-00003.safetensors"
|
| 403 |
+
}
|
| 404 |
+
}
|
open_source_repo_demo.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6dd765d355fffb62861e627373857c01d15fbf95ddaf7a6f5e7dff1d933ceb14
|
| 3 |
+
size 13975450
|
processor_config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"audio_bos_token": "<|audio_out_bos|>",
|
| 3 |
+
"audio_delay_token": "<|reserved_special_token_6|>",
|
| 4 |
+
"audio_eos_token": "<|audio_eos|>",
|
| 5 |
+
"audio_stream_bos_id": 1024,
|
| 6 |
+
"audio_stream_eos_id": 1025,
|
| 7 |
+
"audio_token": "<|AUDIO_OUT|>",
|
| 8 |
+
"audio_tokenizer": {
|
| 9 |
+
"audio_tokenizer_class": "HiggsAudioV2TokenizerModel",
|
| 10 |
+
"audio_tokenizer_name_or_path": "bosonai/higgs-audio-v2-tokenizer"
|
| 11 |
+
},
|
| 12 |
+
"feature_extractor": {
|
| 13 |
+
"feature_extractor_type": "DacFeatureExtractor",
|
| 14 |
+
"feature_size": 1,
|
| 15 |
+
"hop_length": 1,
|
| 16 |
+
"padding_side": "right",
|
| 17 |
+
"padding_value": 0.0,
|
| 18 |
+
"return_attention_mask": true,
|
| 19 |
+
"sampling_rate": 24000
|
| 20 |
+
},
|
| 21 |
+
"processor_class": "HiggsAudioV2Processor"
|
| 22 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin_of_text|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end_of_text|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
}
|
| 16 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1a222563314bf6ffe3471622bff017ff5bb0630f2924faf44216195ebfef2af3
|
| 3 |
+
size 17209675
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backend": "tokenizers",
|
| 3 |
+
"bos_token": "<|begin_of_text|>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"eos_token": "<|end_of_text|>",
|
| 6 |
+
"is_local": false,
|
| 7 |
+
"model_input_names": [
|
| 8 |
+
"input_ids",
|
| 9 |
+
"attention_mask"
|
| 10 |
+
],
|
| 11 |
+
"model_max_length": 131072,
|
| 12 |
+
"pad_token": "<|end_of_text|>",
|
| 13 |
+
"processor_class": "HiggsAudioV2Processor",
|
| 14 |
+
"tokenizer_class": "TokenizersBackend",
|
| 15 |
+
"trust_remote": true
|
| 16 |
+
}
|
vocence_config.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Optional PromptTTS settings read by your miner.py. Example values.
|
| 2 |
+
|
| 3 |
+
runtime:
|
| 4 |
+
adapter: "example"
|
| 5 |
+
device_preference: "cuda"
|
| 6 |
+
dtype: "float32"
|
| 7 |
+
|
| 8 |
+
generation:
|
| 9 |
+
sample_rate: 24000
|
| 10 |
+
max_seconds: 20
|
| 11 |
+
guidance_scale: 1.0
|
| 12 |
+
|
| 13 |
+
io:
|
| 14 |
+
output_format: "wav"
|
| 15 |
+
|
| 16 |
+
limits:
|
| 17 |
+
max_text_chars: 2000
|
| 18 |
+
max_instruction_chars: 600
|