

Upload 14 files
Browse files- .gitattributes +1 -0
- all_results.json +12 -0
- chat_template.jinja +1 -0
- config.json +65 -0
- eval_results.json +7 -0
- generation_config.json +11 -0
- model.safetensors +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +18 -0
- train_results.json +8 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
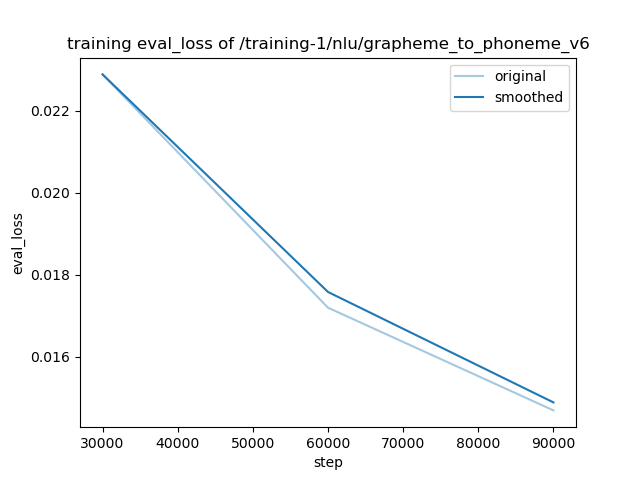
- training_eval_loss.png +0 -0
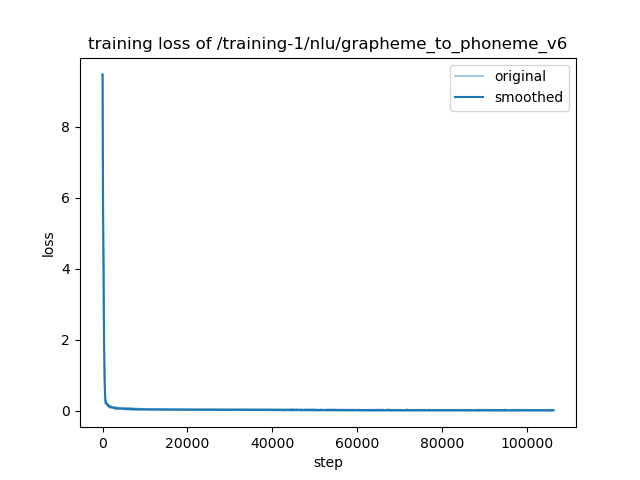
- training_loss.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 0.013834569603204727,
|
| 4 |
+
"eval_runtime": 613.8852,
|
| 5 |
+
"eval_samples_per_second": 110.77,
|
| 6 |
+
"eval_steps_per_second": 6.923,
|
| 7 |
+
"total_flos": 3635036937584640.0,
|
| 8 |
+
"train_loss": 0.040250375388965885,
|
| 9 |
+
"train_runtime": 214343.3461,
|
| 10 |
+
"train_samples_per_second": 31.725,
|
| 11 |
+
"train_steps_per_second": 0.496
|
| 12 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ content }}{% elif message['role'] == 'assistant' %}{{ content }}{% endif %}{% endfor %}
|
config.json
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Gemma2ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"attn_logit_softcapping": 50.0,
|
| 8 |
+
"bos_token_id": 2,
|
| 9 |
+
"cache_implementation": "hybrid",
|
| 10 |
+
"dtype": "bfloat16",
|
| 11 |
+
"eos_token_id": 1,
|
| 12 |
+
"final_logit_softcapping": 30.0,
|
| 13 |
+
"head_dim": 256,
|
| 14 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 15 |
+
"hidden_activation": "gelu_pytorch_tanh",
|
| 16 |
+
"hidden_size": 2304,
|
| 17 |
+
"initializer_range": 0.02,
|
| 18 |
+
"intermediate_size": 9216,
|
| 19 |
+
"layer_types": [
|
| 20 |
+
"sliding_attention",
|
| 21 |
+
"full_attention",
|
| 22 |
+
"sliding_attention",
|
| 23 |
+
"full_attention",
|
| 24 |
+
"sliding_attention",
|
| 25 |
+
"full_attention",
|
| 26 |
+
"sliding_attention",
|
| 27 |
+
"full_attention",
|
| 28 |
+
"sliding_attention",
|
| 29 |
+
"full_attention",
|
| 30 |
+
"sliding_attention",
|
| 31 |
+
"full_attention",
|
| 32 |
+
"sliding_attention",
|
| 33 |
+
"full_attention",
|
| 34 |
+
"sliding_attention",
|
| 35 |
+
"full_attention",
|
| 36 |
+
"sliding_attention",
|
| 37 |
+
"full_attention",
|
| 38 |
+
"sliding_attention",
|
| 39 |
+
"full_attention",
|
| 40 |
+
"sliding_attention",
|
| 41 |
+
"full_attention",
|
| 42 |
+
"sliding_attention",
|
| 43 |
+
"full_attention",
|
| 44 |
+
"sliding_attention",
|
| 45 |
+
"full_attention"
|
| 46 |
+
],
|
| 47 |
+
"max_position_embeddings": 8192,
|
| 48 |
+
"model_type": "gemma2",
|
| 49 |
+
"num_attention_heads": 8,
|
| 50 |
+
"num_hidden_layers": 26,
|
| 51 |
+
"num_key_value_heads": 4,
|
| 52 |
+
"pad_token_id": 0,
|
| 53 |
+
"query_pre_attn_scalar": 256,
|
| 54 |
+
"rms_norm_eps": 1e-06,
|
| 55 |
+
"rope_parameters": {
|
| 56 |
+
"rope_theta": 10000.0,
|
| 57 |
+
"rope_type": "default"
|
| 58 |
+
},
|
| 59 |
+
"sliding_window": 4096,
|
| 60 |
+
"tie_word_embeddings": true,
|
| 61 |
+
"transformers_version": "5.0.0",
|
| 62 |
+
"use_bidirectional_attention": null,
|
| 63 |
+
"use_cache": false,
|
| 64 |
+
"vocab_size": 256064
|
| 65 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 0.013834569603204727,
|
| 4 |
+
"eval_runtime": 613.8852,
|
| 5 |
+
"eval_samples_per_second": 110.77,
|
| 6 |
+
"eval_steps_per_second": 6.923
|
| 7 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 2,
|
| 4 |
+
"cache_implementation": "hybrid",
|
| 5 |
+
"eos_token_id": [
|
| 6 |
+
1
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 0,
|
| 9 |
+
"transformers_version": "5.0.0",
|
| 10 |
+
"use_cache": true
|
| 11 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ffc73ef51d53b5cd15a8d0c5b2d660186e65ad303e1488fcf3caa8f79410305a
|
| 3 |
+
size 5229012424
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a09888eecfc2c471e752492bac14515a6f6e0af75dac67698f274234538a9b20
|
| 3 |
+
size 34374269
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"backend": "tokenizers",
|
| 3 |
+
"bos_token": "<bos>",
|
| 4 |
+
"clean_up_tokenization_spaces": false,
|
| 5 |
+
"eos_token": "<eos>",
|
| 6 |
+
"is_local": true,
|
| 7 |
+
"mask_token": "<mask>",
|
| 8 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 9 |
+
"model_specific_special_tokens": {},
|
| 10 |
+
"pad_token": "<pad>",
|
| 11 |
+
"padding_side": "right",
|
| 12 |
+
"sp_model_kwargs": {},
|
| 13 |
+
"spaces_between_special_tokens": false,
|
| 14 |
+
"split_special_tokens": false,
|
| 15 |
+
"tokenizer_class": "GemmaTokenizer",
|
| 16 |
+
"unk_token": "<unk>",
|
| 17 |
+
"use_default_system_prompt": false
|
| 18 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 3635036937584640.0,
|
| 4 |
+
"train_loss": 0.040250375388965885,
|
| 5 |
+
"train_runtime": 214343.3461,
|
| 6 |
+
"train_samples_per_second": 31.725,
|
| 7 |
+
"train_steps_per_second": 0.496
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:65d5e9864c0480c6ce77f22859a347fb92ca258c36b5a77321ffb918fd2e7355
|
| 3 |
+
size 7313
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|