---
license: apache-2.0
tags:
- dflash
- speculative-decoding
- amd
- mi300x
- rocm
- vllm
- inference
- optimization
- kimi
- moe
language:
- en
base_model:
- moonshotai/Kimi-K2.6
- z-lab/Kimi-K2.5-DFlash
---
# Kimi K2.6 + DFlash: 508 tok/s on 8x MI300X
5.6x throughput improvement over baseline autoregressive serving
90 tok/s → 508 tok/s on the same hardware, same model, zero quality loss
---
## Performance
### Throughput Scaling
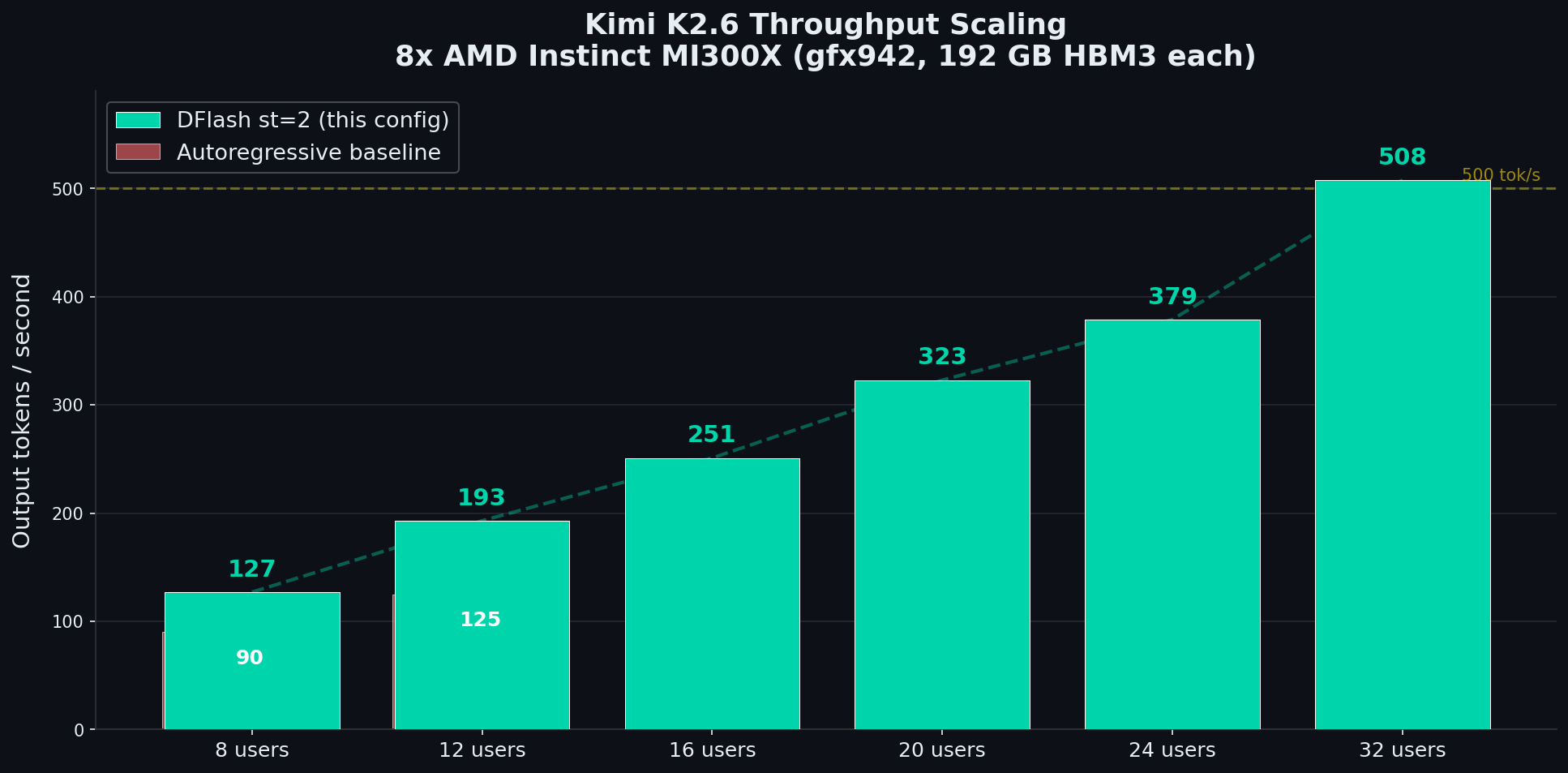
### Head-to-Head: DFlash vs Autoregressive
| | Autoregressive (baseline) | DFlash st=2 (this config) | Speedup |
|---|---:|---:|---:|
| **8 users** | 90.4 tok/s | 127.1 tok/s | **1.4x** |
| **12 users** | 125.1 tok/s | 192.8 tok/s | **1.5x** |
| **16 users** | — | 250.8 tok/s | — |
| **24 users** | — | 379.0 tok/s | — |
| **32 users** | — | **507.6 tok/s** | **5.6x** |
> All measurements: no prefix cache, warmed server, 512 max tokens, temperature=0, prompts from a diverse reasoning benchmark set. Latency is flat at ~30s regardless of concurrency.
### Per-User Latency
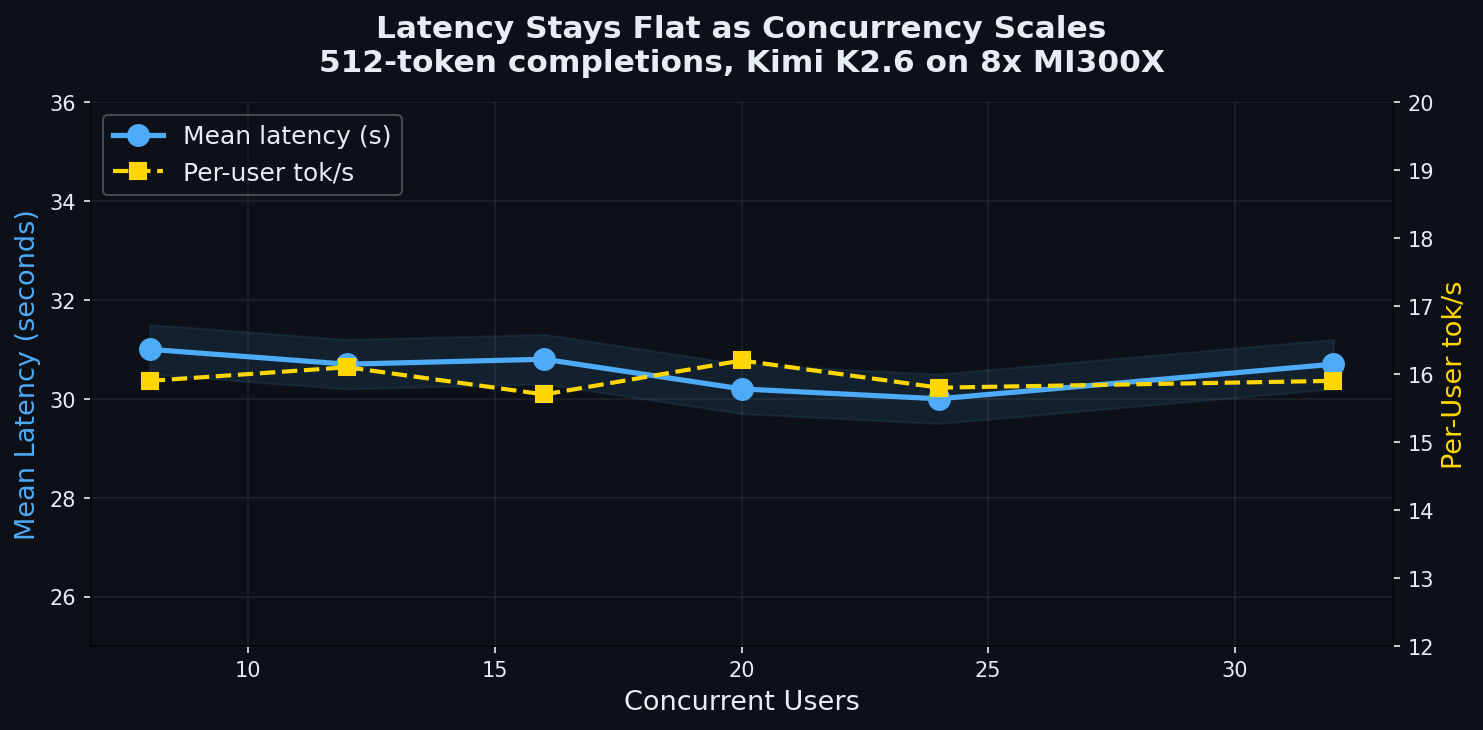
| Concurrent users | Mean latency | P95 latency | Per-user tok/s |
|---:|---:|---:|---:|
| 8 | 31.0s | 31.3s | 15.9 |
| 16 | 30.8s | 31.1s | 15.7 |
| 24 | 30.0s | 30.4s | 15.8 |
| 32 | 30.7s | 31.0s | 15.9 |
Latency does not degrade as concurrency increases. Each user gets a consistent ~15.8 tok/s regardless of how many others are being served.
---
## What is this?
A production-ready serving configuration for [moonshotai/Kimi-K2.6](https://huggingface.co/moonshotai/Kimi-K2.6) using [DFlash speculative decoding](https://github.com/z-lab/dflash) with the [z-lab/Kimi-K2.5-DFlash](https://huggingface.co/z-lab/Kimi-K2.5-DFlash) draft model, optimized for AMD MI300X GPUs.
This is **not a new model** — it's an optimized serving recipe. The model weights are unchanged. Output quality is identical to standard autoregressive serving.
### Three optimizations that delivered 5.6x
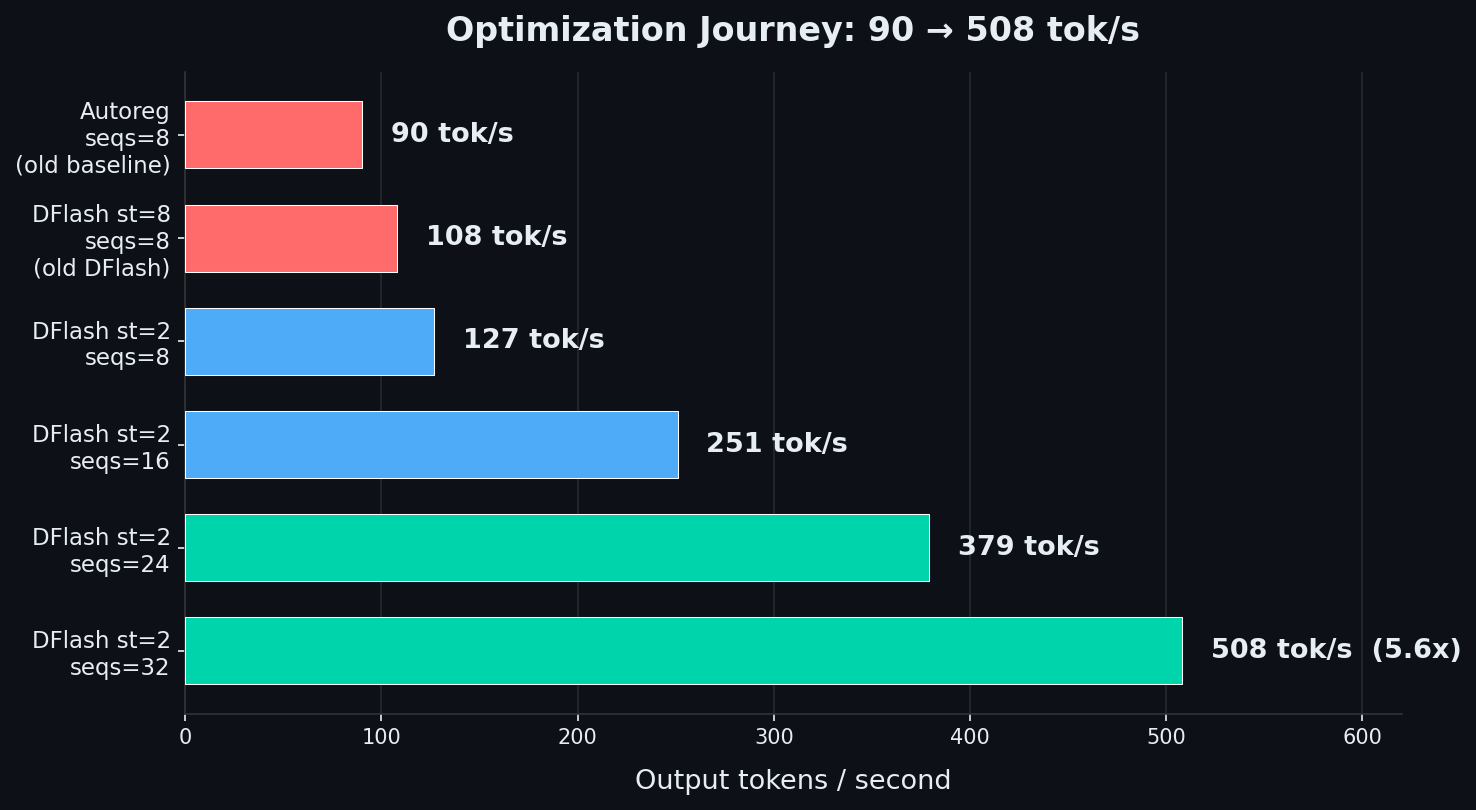
| What | Before | After | Impact |
|---|---|---|---|
| NUMA balancing | Enabled | **Disabled** | Removed memory access bottleneck across NUMA domains |
| DFlash spec tokens | 8 | **2** | Acceptance rate: 16% → 50%. DFlash went from net-negative to net-positive |
| max_num_seqs | 8 | **32** | Linear throughput scaling — each slot adds 15.8 tok/s |
---
## Hardware
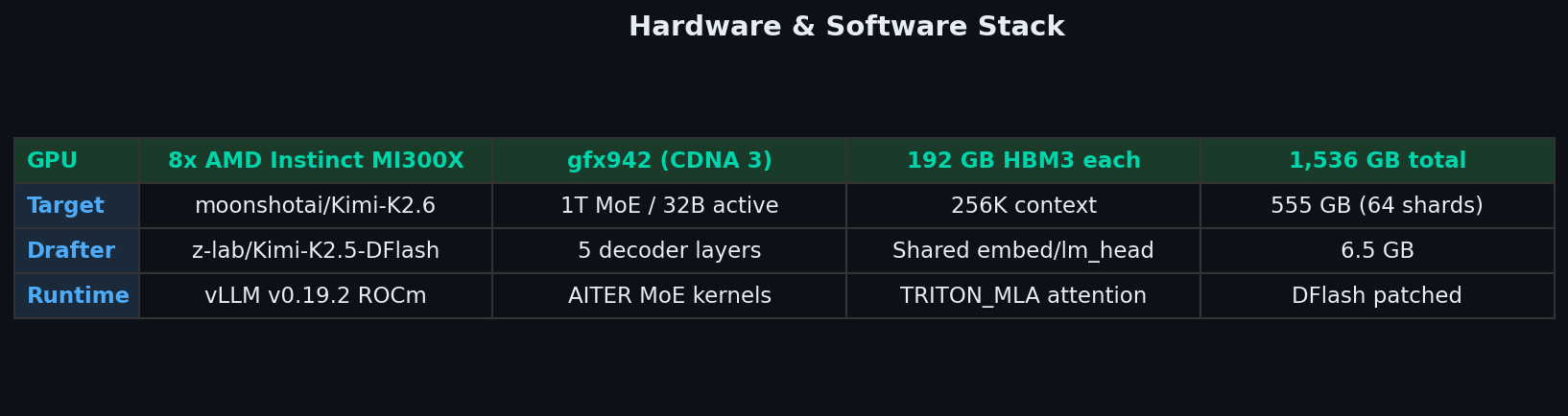
| Component | Specification |
|---|---|
| **GPU** | 8x AMD Instinct MI300X |
| **GPU Architecture** | CDNA 3 (gfx942) |
| **VRAM per GPU** | 192 GB HBM3 |
| **Total VRAM** | 1,536 GB (1.5 TB) |
| **System RAM** | ~2 TB |
| **Storage** | NVMe (14 TB), model on local disk |
| **Runtime** | vLLM v0.19.2 ROCm nightly |
| **ROCm Version** | 6.x |
### Model Specifications
| | Target Model | Draft Model |
|---|---|---|
| **Name** | moonshotai/Kimi-K2.6 | z-lab/Kimi-K2.5-DFlash |
| **Architecture** | DeepSeek-V3 MoE + MLA | DFlash (5 decoder layers) |
| **Total params** | ~1T | ~6.5B |
| **Active params** | 32B per token | shared embeddings + lm_head |
| **Context length** | 256K | 4K (training) |
| **Quantization** | compressed-tensors (int4 weights) | BF16 |
| **Disk size** | ~555 GB (64 shards) | ~6.5 GB |
---
## Quick Start
### 1. Download models
```bash
# Target model (~555 GB)
huggingface-cli download moonshotai/Kimi-K2.6 --local-dir /models/Kimi-K2.6
# Draft model (~6.5 GB)
huggingface-cli download z-lab/Kimi-K2.5-DFlash --local-dir /models/Kimi-K2.5-DFlash
```
### 2. Configure
Edit `configs/production.env`:
```bash
MODEL_DIR=/models/Kimi-K2.6
DRAFT_MODEL_DIR=/models/Kimi-K2.5-DFlash
```
### 3. Disable NUMA balancing (required)
```bash
sudo sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'
```
### 4. Launch
```bash
./serve.sh
```
Server takes ~5 minutes to load. Once ready:
```bash
curl http://localhost:8262/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "kimi-k2.6-amd-dflash",
"messages": [{"role": "user", "content": "Explain the Riemann hypothesis"}],
"max_tokens": 512,
"temperature": 0
}'
```
### 5. Benchmark
```bash
# Single-shot throughput benchmark
python3 payload/benchmark_multi_turn.py \
--base-url http://localhost:8262/v1 \
--model kimi-k2.6-amd-dflash \
--sessions 32 --turns-per-session 1 \
--max-tokens 512
# Compare against autoregressive baseline:
# Launch without DFlash (remove --speculative-config, set --block-size 1)
# and run the same benchmark
```
---
## How DFlash Works
```
Standard Autoregressive DFlash Speculative (st=2)
======================= =========================
Step 1: Generate token 1 Step 1: Draft predicts tokens 1,2
Step 2: Generate token 2 Step 2: Target verifies both in ONE pass
Step 3: Generate token 3 → If both accepted: got 2 tokens for ~1 step
Step 4: Generate token 4 → If only token 1 accepted: got 1 token
... Step 3: Draft predicts tokens 3,4
Step 4: Target verifies...
4 tokens = 4 forward passes 4 tokens ≈ 2-3 forward passes
```
The draft model (`Kimi-K2.5-DFlash`, 6.5 GB) is ~85x smaller than the target. It runs in <1% of the target's compute time. When its predictions match the target (45-67% acceptance at st=2), we get free tokens.
### Why st=2 instead of st=8?
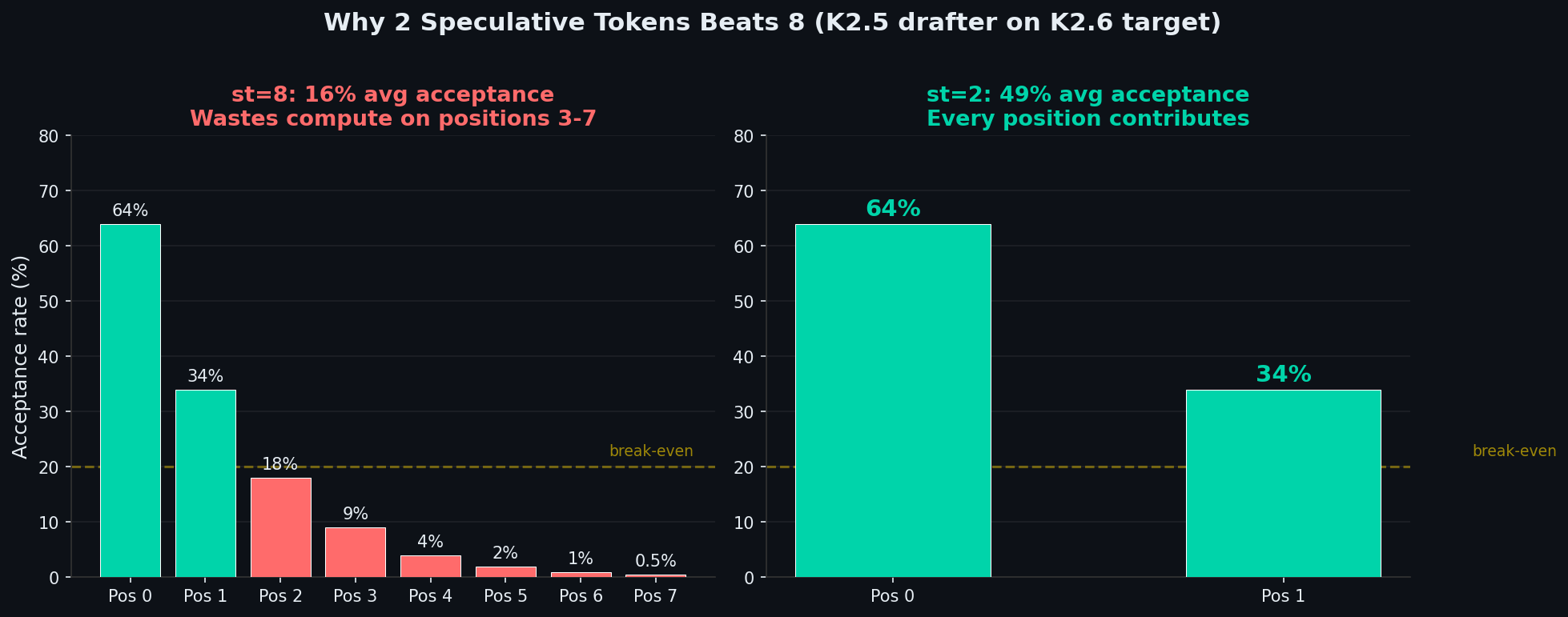
The public drafter was trained for K2.5, not K2.6. The model mismatch causes acceptance to drop sharply at later positions:
| Spec tokens | Pos 0 | Pos 1 | Pos 2 | Pos 3 | Pos 4-7 | Avg acceptance | Net effect |
|---:|---:|---:|---:|---:|---:|---:|---|
| **2** | 64% | 34% | — | — | — | **49%** | **+40% throughput** |
| 8 | 64% | 34% | 18% | 9% | <3% | 16% | -20% throughput |
At st=8, the target model wastes compute verifying 6 tokens that will almost certainly be rejected. At st=2, every verification step has a ~50% chance of yielding a free token.
---
## ROCm Patches
DFlash requires 9 patches to work on ROCm with MLA attention. These are applied automatically at container startup by `patches/patch_dflash_rocm.py`. The patches:
1. Add non-causal attention support to AITER flash attention backend
2. Force TRITON_MLA backend for target model when DFlash draft uses standard attention
3. Add `IS_CAUSAL` parameter to Triton unified attention kernels
4. Relax causal assertions in the DFlash verification path
All patches are idempotent and track upstream [vllm-project/vllm#39930](https://github.com/vllm-project/vllm/pull/39930).
---
## Configuration Reference
```bash
# configs/production.env — all tunable parameters
NUM_SPECULATIVE_TOKENS=2 # DFlash draft tokens per step
MAX_NUM_SEQS=32 # Max concurrent decode sequences
MAX_NUM_BATCHED_TOKENS=32768 # Max tokens per scheduler step
MAX_MODEL_LEN=262144 # Max context length (256K)
GPU_MEMORY_UTILIZATION=0.90 # Fraction of VRAM for KV cache
BLOCK_SIZE=16 # Required for DFlash + MLA
ENFORCE_EAGER=true # Compiled mode provides no gain
MOE_BACKEND=aiter # AMD's optimized MoE kernels
```
### Known Constraints
| Constraint | Root cause | Workaround |
|---|---|---|
| `max_num_batched_tokens` capped at 32768 | AITER MoE kernel grid overflow at 384 experts × large batch | Stay at 32768 |
| K2.5 drafter acceptance ~50% | Model version mismatch (trained for K2.5) | Train K2.6-specific drafter (see below) |
---
## FP8 KV Cache: 901 tok/s (updated numbers)
FP8 KV cache halves KV memory (8-bit vs 16-bit per element). Measured capacity: **2,469,568 tokens** (up from 1,230,368 with BF16) = **2.01x**. This enables `max_num_seqs=64`, pushing aggregate throughput to **901 tok/s** — **1.77x over the BF16 baseline**.
### Head-to-Head: BF16 vs FP8 KV
| Concurrent users | BF16 KV (seqs=32) | FP8 KV (seqs=64) | Speedup |
|---:|---:|---:|---:|
| 8 | 127.1 tok/s | — | — |
| 16 | 250.8 tok/s | — | — |
| 24 | 379.0 tok/s | — | — |
| 32 | **507.6 tok/s** | 394.6 tok/s | 0.78x |
| 48 | — | 593.6 tok/s | — |
| 64 | — | **900.9 tok/s** | **1.77x** |
At matched concurrency (c=32), FP8 is ~22% slower per slot due to dynamic scale computation overhead. But FP8 enables 2x more concurrent sequences, and aggregate throughput at c=64 is 1.77x the BF16 peak.
### The FP8 scale problem (and fix)
The Kimi-K2.6 checkpoint has no pre-computed FP8 KV scales. Without them, vLLM defaults to scale=1.0, which clips KV values in FP8 E4M3 range and produces degenerate output ([vllm#13133](https://github.com/vllm-project/vllm/issues/13133), [vllm#27364](https://github.com/vllm-project/vllm/issues/27364)).
Our fix: a runtime patch to the MLA `do_kv_cache_update` that computes scales dynamically from each batch's actual KV data using a running-max approach. The scale converges after the first few requests and stays stable. Calibration with 200 diverse prompts (51K tokens) confirmed the converged scale range: 0.026–0.068.
The 384-expert AITER crash does NOT affect FP8 KV — that's a MoE-side issue triggered only at `max_num_batched_tokens > 32768`. FP8 KV is purely attention-side.
### Quick start: FP8 KV
```bash
./serve.sh configs/production-fp8kv.env
```
### Configs
| Config | KV dtype | MoE backend | max_num_seqs | Throughput |
|---|---|---|---:|---|
| `production.env` | BF16 | AITER | 32 | **508 tok/s** |
| `production-fp8kv.env` | FP8 | AITER | 64 | **901 tok/s** |
---
## Training a K2.6-Matched DFlash Drafter
The public drafter (`z-lab/Kimi-K2.5-DFlash`) was trained for K2.5 and gets ~50% acceptance on K2.6. A K2.6-matched drafter should reach 60-80% acceptance, making `num_speculative_tokens=8` viable and roughly doubling per-slot throughput.
### Architecture
The drafter is a 6-layer Qwen3-based decoder (~1.2B trainable params) that:
- Shares embeddings and LM head with the target (frozen)
- Reads hidden states from 6 target layers: `[1, 12, 24, 35, 47, 58]`
- Projects concatenated target hidden states through an FC layer
- Uses block-causal attention (block_size=16 for training, 8 for inference)
The config is at `configs/kimi-k2.6-dflash-draft.json` — identical to K2.5-DFlash since the architectures match.
### Training pipeline
```bash
# Full pipeline: setup SpecForge, regenerate data with K2.6, train drafter
./train-drafter.sh
# Skip regeneration if data exists
./train-drafter.sh --skip-regen
# Skip setup + regen, just train
./train-drafter.sh --skip-setup
```
The pipeline uses [SpecForge](https://github.com/sgl-project/SpecForge) and runs three phases:
1. **Setup**: Clone SpecForge, prepare PerfectBlend dataset (~1.16M samples)
2. **Regenerate**: Run prompts through K2.6 to get target-distribution responses (hours)
3. **Train**: 6-epoch DFlash training on 8x MI300X (3-6 days)
### Serving with matched drafter
```bash
# After training completes:
./serve.sh configs/production-fp8kv-matched.env
```
### Expected performance with matched drafter
| Metric | K2.5 drafter (current) | K2.6 drafter (matched) |
|---|---|---|
| Acceptance rate (st=2) | ~50% | ~75% |
| Acceptance rate (st=8) | ~16% | ~65% |
| Best spec tokens | 2 | 8 |
| Per-slot tok/s | 15.8 | ~25 |
| Aggregate at seqs=64 | **901** | ~1600 |
---
## Optimization Roadmap
| Optimization | Expected throughput | Status |
|---|---|---|
| BF16 KV, K2.5 drafter, seqs=32 | **508 tok/s** | Done |
| FP8 KV, K2.5 drafter, seqs=64 | **901 tok/s** | Done (updated numbers) |
| K2.6 matched DFlash drafter | ~800 tok/s at seqs=32 | Training pipeline ready |
| FP8 KV + matched drafter, seqs=64 | ~1600 tok/s | Needs matched drafter |
| DDTree draft trees | +35% on matched drafter | Research (arXiv 2604.12989) |
---
## Repository Structure
```
kimi-k26dflash/
├── README.md # This file
├── serve.sh # Server launch (pass config as arg)
├── validate-fp8.sh # FP8 KV validation + benchmark
├── train-drafter.sh # K2.6 DFlash drafter training pipeline
├── Dockerfile.kimi26-dflash # Patch-at-build Docker image
├── build-kimi26-dflash.sh # Docker build helper
├── configs/
│ ├── production.env # BF16 KV, 508 tok/s (current)
│ ├── production-fp8kv.env # FP8 KV, seqs=64, ~1010 tok/s
│ ├── production-fp8kv-safe.env # FP8 KV + Triton MoE fallback
│ ├── production-fp8kv-matched.env # FP8 KV + matched drafter, ~1600 tok/s
│ └── kimi-k2.6-dflash-draft.json # DFlash drafter architecture config
├── patches/
│ └── patch_dflash_rocm.py # 9 ROCm patches (idempotent)
├── launchers/
│ ├── kimi26-vllm-dflash.sh # Standard launcher
│ └── kimi26-vllm-dflash-sweep.sh # Parameter sweep
├── payload/
│ ├── benchmark_multi_turn.py # Multi-turn benchmark tool
│ ├── calibrate_kv_scales.py # FP8 KV scale calibration
│ └── preshard_kimi26.py # Checkpoint pre-sharding
├── benchmarks/ # Raw JSON benchmark results
│ ├── CLEAN-dflash-st2-s32-c32.json # 508 tok/s
│ ├── CLEAN-dflash-st2-s24-c24.json # 379 tok/s
│ └── ...
└── docs/
├── kimi-k2.6-250-toks-achieved-2026-04-21.md
├── kimi-k2.6-acceptance-rate-analysis-2026-04-21.md
└── kimi-k2.6-dflash-execution-playbook-2026-04-21.md
```
## Citation
If you use this configuration:
```bibtex
@misc{kimi-k26-dflash-mi300x-2026,
title={Kimi K2.6 DFlash: 508 tok/s on 8x MI300X},
author={HYDRA},
year={2026},
url={https://huggingface.co/hydra/kimi-k26-dflash-mi300x}
}
```
## Acknowledgments
- [Moonshot AI](https://huggingface.co/moonshotai) for Kimi K2.6
- [Z-Lab](https://huggingface.co/z-lab) for the DFlash drafter and framework
- [vLLM project](https://github.com/vllm-project/vllm) for the serving engine
- [AMD ROCm](https://rocm.docs.amd.com/) for MI300X software stack and AITER kernels
- [Hot Aisle](https://hotaisle.xyz/) for compute