Datasets:

admin commited on
Commit ·
28b3330
1
Parent(s): 147011c
upd md
Browse files
README.md
CHANGED
|
@@ -25,11 +25,11 @@ Since this is a self-created dataset, we directly carry out the unified integrat
|
|
| 25 |
We have constructed the [default subset](#default-subset) of the current integrated version of the dataset, and its data structure can be viewed in the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/bel_canto/dataPeview). Since the default subset has not been evaluated, to verify its effectiveness, we have built the [eval subset](#eval-subset) based on the default subset for the evaluation of the integrated version of the dataset. The evaluation results can be seen in the [bel_canto](https://huggingface.co/ccmusic-database/bel_canto). Below are the data structures and invocation methods of the subsets.
|
| 26 |
|
| 27 |
## Statistics
|
| 28 |
-
|  of the current integrated version of the dataset, and its data structure can be viewed in the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/bel_canto/dataPeview). Since the default subset has not been evaluated, to verify its effectiveness, we have built the [eval subset](#eval-subset) based on the default subset for the evaluation of the integrated version of the dataset. The evaluation results can be seen in the [bel_canto](https://huggingface.co/ccmusic-database/bel_canto). Below are the data structures and invocation methods of the subsets.
|
| 26 |
|
| 27 |
## Statistics
|
| 28 |
+
|  |  |  |
|
| 29 |
+
| :------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------: |
|
| 30 |
+
| **Fig. 1** | **Fig. 2** | **Fig. 3** |
|
| 31 |
|
| 32 |
+
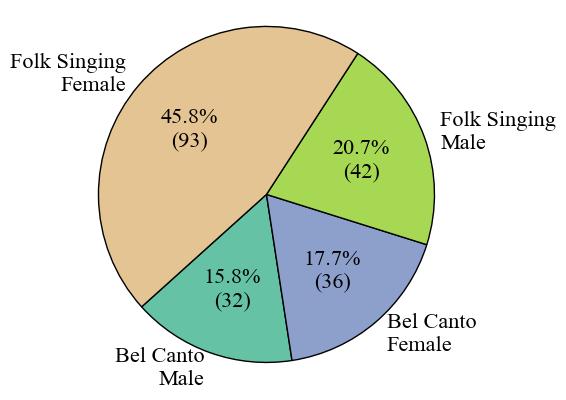
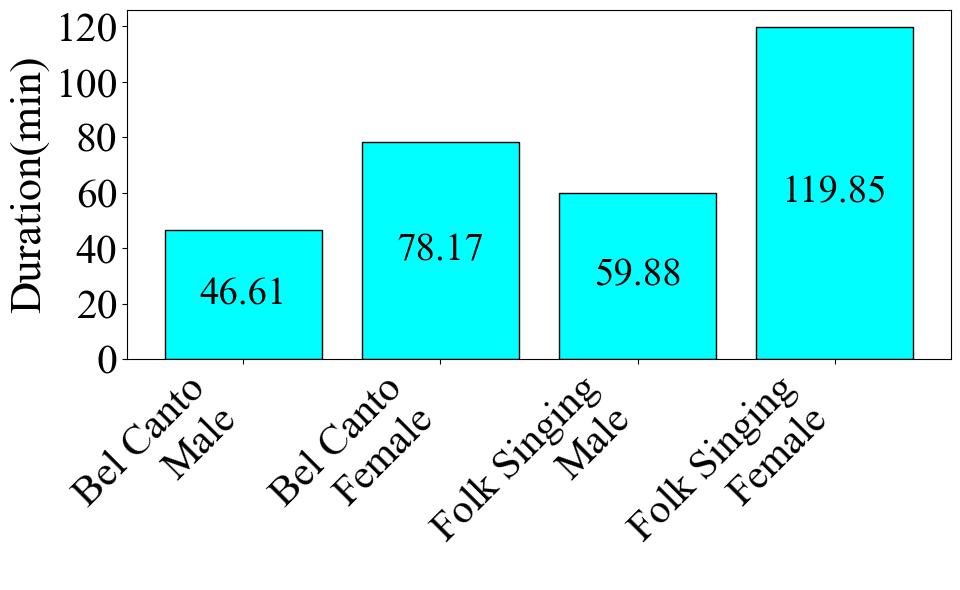
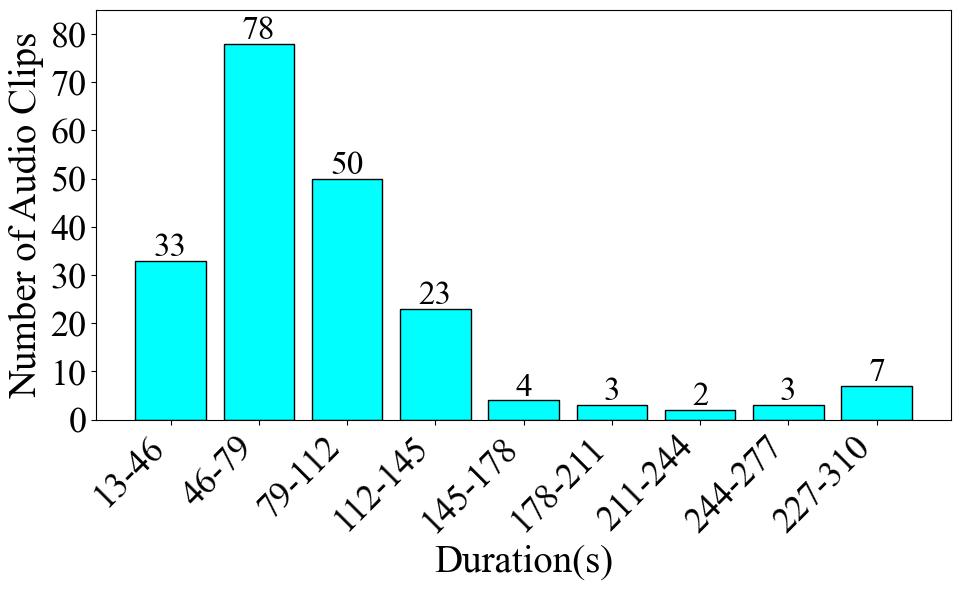
Firstly, **Fig. 1** presents the clip number of each category. The label with the highest data volume is Folk singing female, comprising 93 audio clips, which is 45.8% of the dataset. The label with the lowest data volume is Bel Canto Male, with 32 audio clips, constituting 15.8% of the dataset. Next, we assess the length of the audio for each label in **Fig. 2**. The Folk Singing Female label has the longest audio data, totaling 119.85 minutes. Bel Canto Male has the shortest audio duration, amounting to 46.61 minutes. The trend is the same as the data number difference shown in the pie chart. Lastly, in **Fig. 3**, the number of audio clips within various duration intervals is displayed. The most common duration range is observed to be 46-79 seconds, with 78 audio segments, while the least common range is 211-244 seconds, featuring only 2 audio segments.
|
| 33 |
|
| 34 |
| Statistical items | Values |
|
| 35 |
| :-----------------: | :------------------: |
|