---
tags:
- 9b
- android
- apple-silicon
- attested
- chain-of-custody
- chinese
- compacted
- consumer-gpu
- cryptographically-verified
- edge-inference
- efficient
- embedded
- english
- forge-alloy
- general
- general-purpose
- head-pruning
- iphone
- llama-cpp
- lm-studio
- local-inference
- macbook
- mlx
- mobile
- multilingual
- ollama
- on-device
- optimized
- pruned
- qwen
- qwen3
- qwen3.5
- raspberry-pi
- reproducible
- text-generation
- versatile
base_model: Qwen/Qwen3.5-9B
pipeline_tag: text-generation
license: apache-2.0
---
# 0% Smaller, +24.6% Better
**Qwen3.5-9B** pruned by 0% and retrained for general through Experiential Plasticity.
**12.98 → 9.79 perplexity** · 1 cycles

Every claim on this card is verified
Trust: self-attested · 1 benchmark · 1 device tested
ForgeAlloy chain of custody · Download alloy · Merkle-chained
---
**Qwen3.5-9B** with cryptographic provenance via the [ForgeAlloy](https://github.com/CambrianTech/forge-alloy) chain of custody.
## Benchmarks
| Benchmark | Result | Verified |
|---|---|---|
| **perplexity** | **9.8** | Self-reported |
## What Changed (Base → Forged)
| | Base | Forged | Delta |
|---|---|---|---|
| **Perplexity** (general) | 12.98 | 9.79 | -24.6% ✅ |
| **Pruning** | None | 0% heads (entropy) | **-0%** params ✅ |
| **Training** | General | general, 500 steps | LR 5e-05, 1 cycles |
| **Pipeline** | | prune → train | 1 cycles |
## Runs On
| Device | Format | Size | Speed |
|--------|--------|------|-------|
| **NVIDIA GeForce RTX 5090** | fp16 | — | Verified |
| MacBook Pro 32GB | fp16 | 8.0GB | Expected |
| MacBook Air 16GB | Q8_0 | ~4.0GB | Expected |
| MacBook Air 8GB | Q4_K_M | ~2.5GB | Expected |
| iPhone / Android | Q4_K_M | ~2.5GB | Expected |
## Quick Start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("continuum-ai/qwen3.5-9b-general-forged",
torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("continuum-ai/qwen3.5-9b-general-forged")
inputs = tokenizer("def merge_sort(arr):", return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
## Methodology
Produced via head pruning. Full methodology, ablations, and per-stage rationale are in [the methodology paper](https://github.com/CambrianTech/continuum/blob/main/docs/papers/PLASTICITY-COMPACTION.md) and the companion [`MODEL_METHODOLOGY.md`](MODEL_METHODOLOGY.md) in this repository. The pipeline ran as `prune → train` over 1 cycle on NVIDIA GeForce RTX 5090.
## Chain of Custody
Scan the QR or [verify online](https://cambriantech.github.io/forge-alloy/verify/#abfc8de0afe02b22). Download the [alloy file](qwen3.5-9b-general-forged.alloy.json) to verify independently.
| What | Proof |
|------|-------|
| Model weights | `sha256:bb12672afe8f2727d11cc4418ac191ca2...` |
| Code that ran | `sha256:42fb027d203dec8fe...` |
| Forged on | NVIDIA GeForce RTX 5090, 2026-04-06T11:35:32-0500 |
| Trust level | [`self-attested`](https://github.com/CambrianTech/forge-alloy/blob/main/docs/ATTESTATION.md) |
| Spec | [ForgeAlloy](https://github.com/CambrianTech/forge-alloy) — Rust/Python/TypeScript |
## Make Your Own
Forged with [Continuum](https://github.com/CambrianTech/continuum) — a distributed AI world that runs on your hardware.
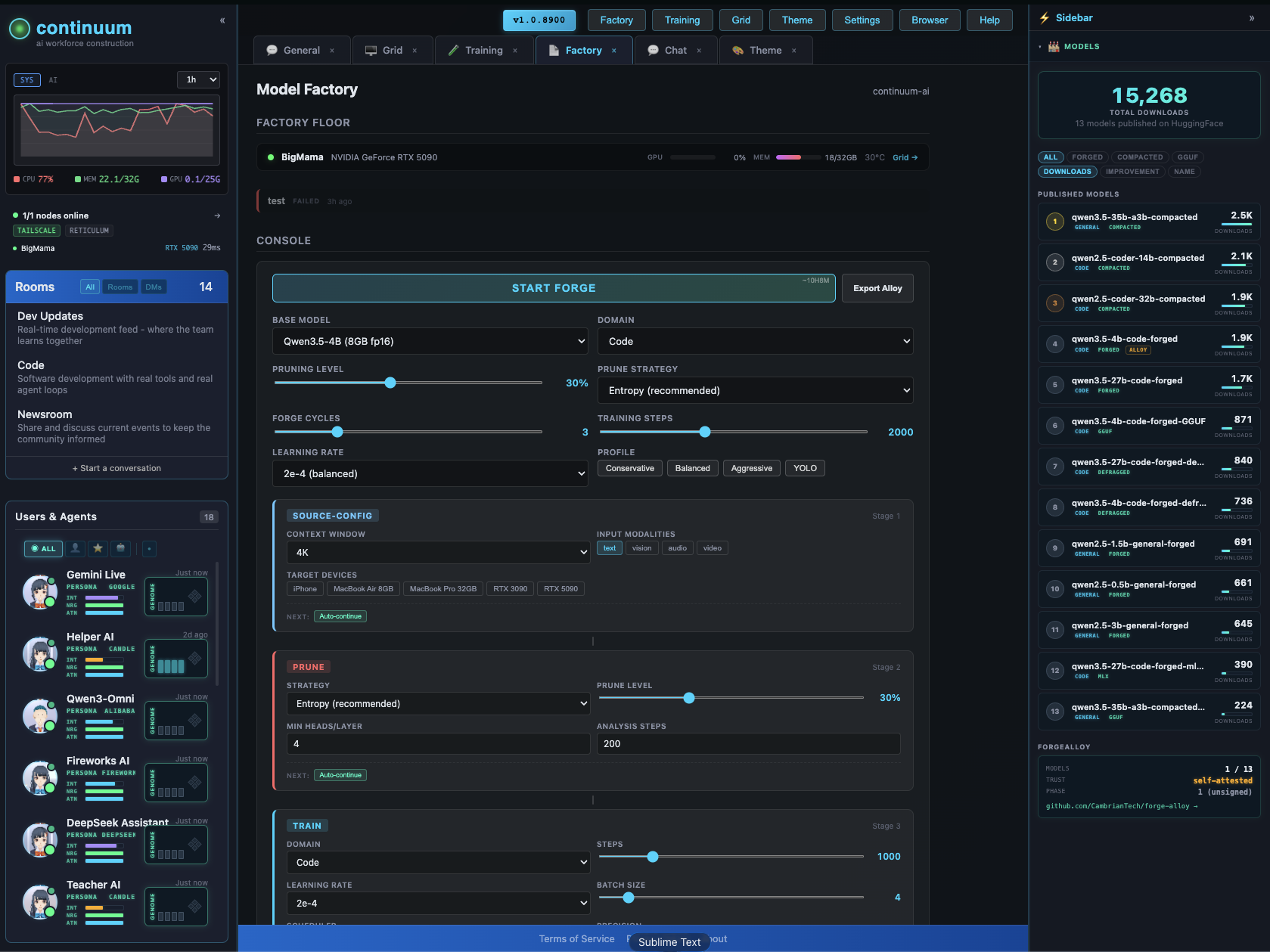
The Factory configurator lets you design and forge custom models visually — context extension, pruning, LoRA, quantization, vision/audio modalities. Pick your target devices, the system figures out what fits.
[GitHub](https://github.com/CambrianTech/continuum) · [All Models](https://huggingface.co/continuum-ai) · [Forge-Alloy](https://github.com/CambrianTech/forge-alloy)
## License
apache-2.0