
Update README.md
Browse files
README.md
CHANGED
|
@@ -18,22 +18,35 @@ widget:
|
|
| 18 |
url: workflow-demo3.png
|
| 19 |
---
|
| 20 |
## qwen-image-edit-plus-gguf
|
| 21 |
-
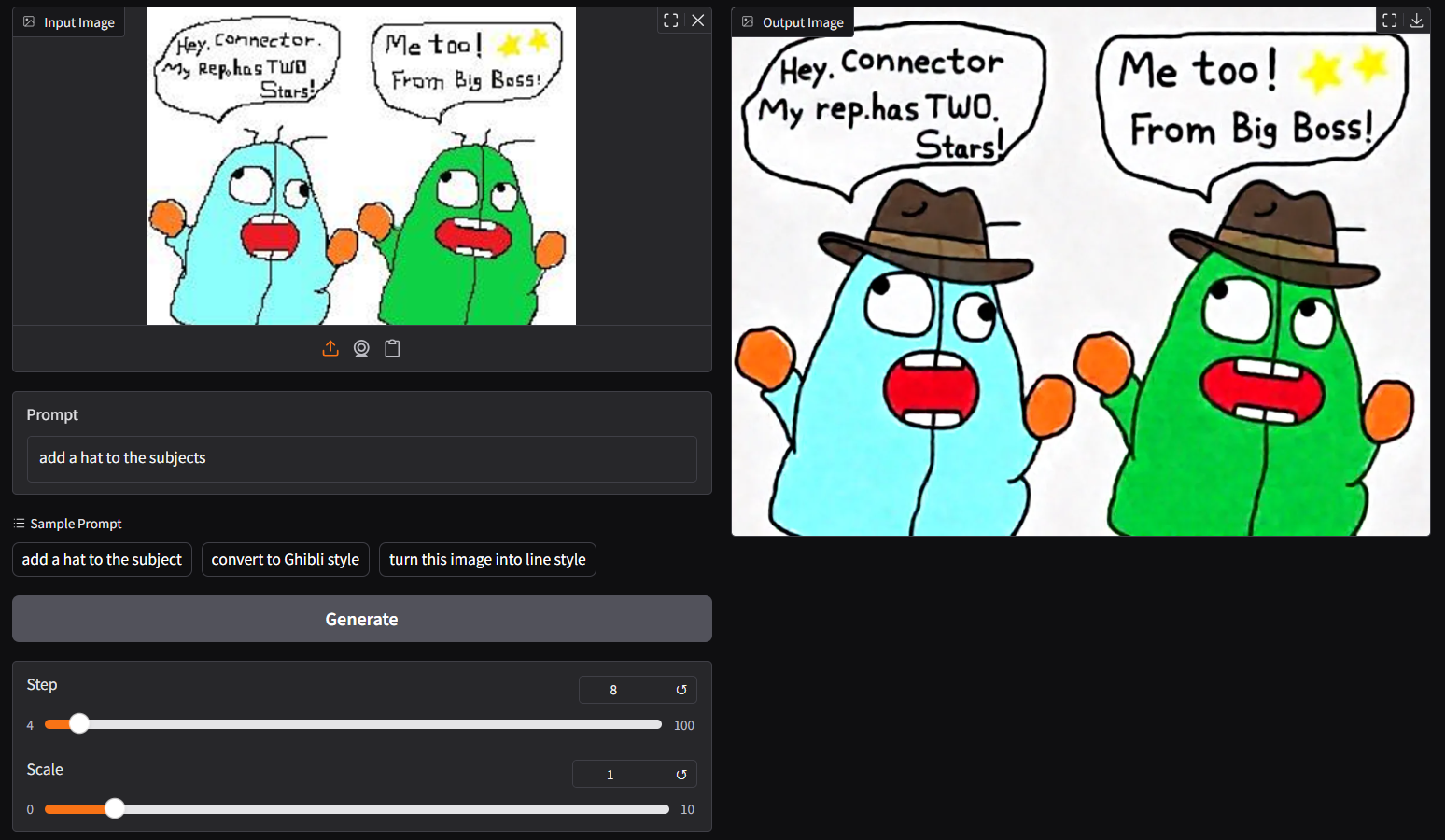
- use 8-step (lite-lora auto applied); save up to 70% loading time
|
| 22 |
- run it with `gguf-connector`; simply execute the command below in console/terminal
|
| 23 |
```
|
| 24 |
-
ggc
|
| 25 |
```
|
| 26 |
>
|
| 27 |
>GGUF file(s) available. Select which one to use:
|
| 28 |
>
|
| 29 |
-
>1. qwen-image-edit-plus-
|
| 30 |
-
>2. qwen-image-edit-plus-iq4_nl.gguf
|
| 31 |
-
>4. qwen-image-edit-plus-
|
| 32 |
>
|
| 33 |
>Enter your choice (1 to 3): _
|
| 34 |
>
|
| 35 |
- opt a `gguf` file in your current directory to interact with; nothing else
|
| 36 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
|
| 39 |
## **run it with gguf-node via comfyui**
|
|
@@ -54,7 +67,39 @@ ggc q7
|
|
| 54 |
pip install git+https://github.com/huggingface/diffusers.git
|
| 55 |
```
|
| 56 |
- simply replace `QwenImageEditPipeline` by `QwenImageEditPlusPipeline` for the qwen-image-edit inference example (see [here](https://huggingface.co/calcuis/qwen-image-edit-gguf))
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |

|
| 60 |
|
|
|
|
| 18 |
url: workflow-demo3.png
|
| 19 |
---
|
| 20 |
## qwen-image-edit-plus-gguf
|
|
|
|
| 21 |
- run it with `gguf-connector`; simply execute the command below in console/terminal
|
| 22 |
```
|
| 23 |
+
ggc q8
|
| 24 |
```
|
| 25 |
>
|
| 26 |
>GGUF file(s) available. Select which one to use:
|
| 27 |
>
|
| 28 |
+
>1. qwen-image-edit-plus-v2-iq3_s.gguf
|
| 29 |
+
>2. qwen-image-edit-plus-v2-iq4_nl.gguf
|
| 30 |
+
>4. qwen-image-edit-plus-v2-iq4_xs.gguf
|
| 31 |
>
|
| 32 |
>Enter your choice (1 to 3): _
|
| 33 |
>
|
| 34 |
- opt a `gguf` file in your current directory to interact with; nothing else
|
| 35 |
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
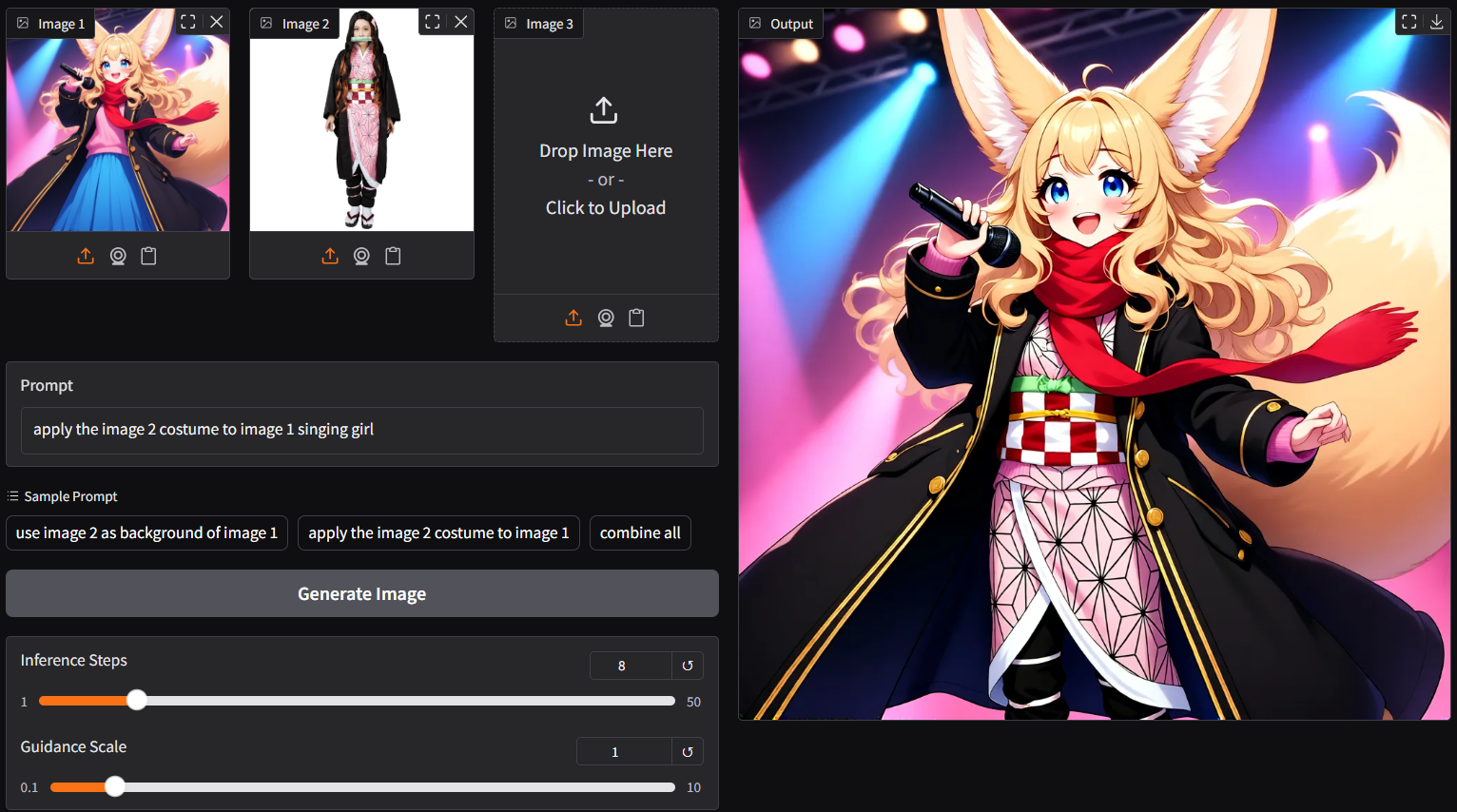
- `ggc q8` accepts multiple image input (see picture above; two images)
|
| 39 |
+
- as lite-lora auto applied, able to use 8 steps; save up to 70% loading time
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
- up to 3 pictures plus customize prompt as input (above is 3 images input demo)
|
| 44 |
+
- or you could also opt the legacy `ggc q7`; similar to image-edit model before
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
ggc q7
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |

|
| 51 |
|
| 52 |
## **run it with gguf-node via comfyui**
|
|
|
|
| 67 |
pip install git+https://github.com/huggingface/diffusers.git
|
| 68 |
```
|
| 69 |
- simply replace `QwenImageEditPipeline` by `QwenImageEditPlusPipeline` for the qwen-image-edit inference example (see [here](https://huggingface.co/calcuis/qwen-image-edit-gguf))
|
| 70 |
+
```py
|
| 71 |
+
import torch, os
|
| 72 |
+
from diffusers import QwenImageTransformer2DModel, GGUFQuantizationConfig, QwenImageEditPlusPipeline
|
| 73 |
+
from diffusers.utils import load_image
|
| 74 |
+
|
| 75 |
+
model_path = "https://huggingface.co/calcuis/qwen-image-edit-plus-gguf/blob/main/qwen-image-edit-plus-v2-iq4_nl.gguf"
|
| 76 |
+
|
| 77 |
+
transformer = QwenImageTransformer2DModel.from_single_file(
|
| 78 |
+
model_path,
|
| 79 |
+
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
|
| 80 |
+
torch_dtype=torch.bfloat16,
|
| 81 |
+
config="callgg/image-edit-decoder",
|
| 82 |
+
subfolder="transformer"
|
| 83 |
+
)
|
| 84 |
+
pipeline = QwenImageEditPipeline.from_pretrained("Qwen/Qwen-Image-Edit-2509", transformer=transformer, torch_dtype=torch.bfloat16)
|
| 85 |
+
print("pipeline loaded")
|
| 86 |
+
pipeline.enable_model_cpu_offload()
|
| 87 |
+
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png")
|
| 88 |
+
prompt = "Add a hat to the cat"
|
| 89 |
+
inputs = {
|
| 90 |
+
"image": image,
|
| 91 |
+
"prompt": prompt,
|
| 92 |
+
"generator": torch.manual_seed(0),
|
| 93 |
+
"true_cfg_scale": 2.5,
|
| 94 |
+
"negative_prompt": " ",
|
| 95 |
+
"num_inference_steps": 20,
|
| 96 |
+
}
|
| 97 |
+
with torch.inference_mode():
|
| 98 |
+
output = pipeline(**inputs)
|
| 99 |
+
output_image = output.images[0]
|
| 100 |
+
output_image.save("output.png")
|
| 101 |
+
print("image saved at", os.path.abspath("output.png"))
|
| 102 |
+
```
|
| 103 |
|
| 104 |

|
| 105 |
|