
Upload folder using huggingface_hub
Browse files- README.md +116 -0
- checkpoint-1748/model.safetensors +3 -0
- checkpoint-1748/optimizer.pt +3 -0
- checkpoint-1748/rng_state.pth +3 -0
- checkpoint-1748/scaler.pt +3 -0
- checkpoint-1748/scheduler.pt +3 -0
- checkpoint-1748/trainer_state.json +62 -0
- checkpoint-1748/training_args.bin +3 -0
- confusion_matrix.csv +4 -0
- confusion_matrix.png +0 -0
- label_map.json +5 -0
- model.pt +3 -0
- model.safetensors +3 -0
- special_tokens_map.json +7 -0
- tokenizer.json +0 -0
- tokenizer_config.json +58 -0
- training_args.bin +3 -0
- training_metadata.json +47 -0
- vocab.txt +0 -0
README.md
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: ar
|
| 3 |
+
tags:
|
| 4 |
+
- text-classification
|
| 5 |
+
- arabic
|
| 6 |
+
- levantine
|
| 7 |
+
- marbert
|
| 8 |
+
- hate-speech
|
| 9 |
+
- incitement-detection
|
| 10 |
+
- custom-code
|
| 11 |
+
metrics:
|
| 12 |
+
- accuracy
|
| 13 |
+
- f1_macro
|
| 14 |
+
- f1_incitement
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# Levantine Arabic Incitement Detector (CLS + Mean + Max)
|
| 18 |
+
|
| 19 |
+
This repository contains a custom fine-tuned **MARBERTv2** pooled-architecture model for 3-way classification of Levantine Arabic social text:
|
| 20 |
+
|
| 21 |
+
- `normal`
|
| 22 |
+
- `abusive`
|
| 23 |
+
- `incitement`
|
| 24 |
+
|
| 25 |
+
The training setup uses:
|
| 26 |
+
- class-balanced cross-entropy
|
| 27 |
+
- asymmetric error cost for incitement mistakes
|
| 28 |
+
- a small ordinal penalty
|
| 29 |
+
- an auxiliary lexicon head based on `incitement.csv`
|
| 30 |
+
- pooled sentence representation: `CLS + mean pooling + max pooling`
|
| 31 |
+
|
| 32 |
+
## Validation Summary
|
| 33 |
+
|
| 34 |
+
These are the k-fold cross-validation averages used to select this configuration:
|
| 35 |
+
|
| 36 |
+
| Metric | Value |
|
| 37 |
+
| :-- | --: |
|
| 38 |
+
| Accuracy | 82.40% |
|
| 39 |
+
| F1 Macro | 0.8025 |
|
| 40 |
+
| F1 Incitement | 0.7752 |
|
| 41 |
+
|
| 42 |
+
## Labels
|
| 43 |
+
|
| 44 |
+
| ID | Label |
|
| 45 |
+
| :-- | :-- |
|
| 46 |
+
| 0 | normal |
|
| 47 |
+
| 1 | abusive |
|
| 48 |
+
| 2 | incitement |
|
| 49 |
+
|
| 50 |
+
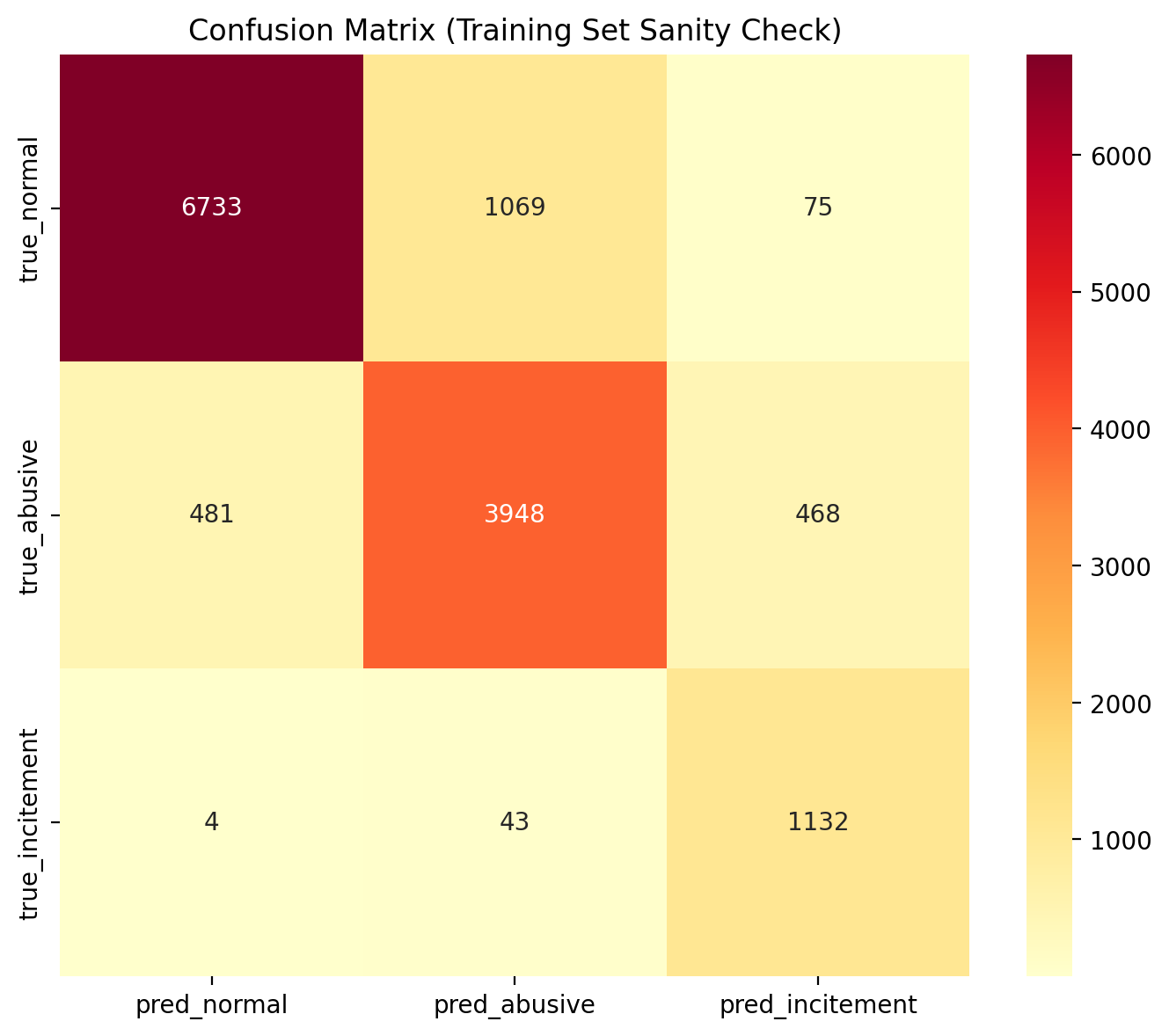
## Confusion Matrix
|
| 51 |
+
|
| 52 |
+
The image below is a **training-set sanity check** for the final model trained on all data. It is not an unbiased test result.
|
| 53 |
+
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
## How to Load
|
| 57 |
+
|
| 58 |
+
This is a custom model wrapper, so load it with the provided `model.pt` weights plus the MARBERTv2 encoder and tokenizer.
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
import json
|
| 62 |
+
import os
|
| 63 |
+
import torch
|
| 64 |
+
import torch.nn as nn
|
| 65 |
+
from transformers import AutoConfig, AutoModel, AutoTokenizer
|
| 66 |
+
|
| 67 |
+
MODEL_DIR = "amitca71/marbertv2-levantine-incitement-detector-cls-mean-max"
|
| 68 |
+
|
| 69 |
+
class MarbertMultiTask(nn.Module):
|
| 70 |
+
def __init__(self, model_name: str, pooling_strategy: str = "cls_mean_max"):
|
| 71 |
+
super().__init__()
|
| 72 |
+
config = AutoConfig.from_pretrained(model_name, num_labels=3)
|
| 73 |
+
self.encoder = AutoModel.from_pretrained(model_name, config=config)
|
| 74 |
+
self.pooling_strategy = pooling_strategy
|
| 75 |
+
hidden_size = self.encoder.config.hidden_size
|
| 76 |
+
self.dropout = nn.Dropout(getattr(self.encoder.config, "hidden_dropout_prob", 0.2))
|
| 77 |
+
self.classifier = nn.Linear(hidden_size * 3, 3)
|
| 78 |
+
self.lexicon_head = nn.Linear(hidden_size * 3, 1)
|
| 79 |
+
|
| 80 |
+
def _masked_mean(self, hidden_states, attention_mask):
|
| 81 |
+
mask = attention_mask.unsqueeze(-1).float()
|
| 82 |
+
masked = hidden_states * mask
|
| 83 |
+
denom = mask.sum(dim=1).clamp(min=1.0)
|
| 84 |
+
return masked.sum(dim=1) / denom
|
| 85 |
+
|
| 86 |
+
def _masked_max(self, hidden_states, attention_mask):
|
| 87 |
+
mask = attention_mask.unsqueeze(-1).bool()
|
| 88 |
+
masked = hidden_states.masked_fill(~mask, float("-inf"))
|
| 89 |
+
pooled = masked.max(dim=1).values
|
| 90 |
+
pooled[torch.isinf(pooled)] = 0.0
|
| 91 |
+
return pooled
|
| 92 |
+
|
| 93 |
+
def forward(self, input_ids, attention_mask, token_type_ids=None):
|
| 94 |
+
outputs = self.encoder(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
|
| 95 |
+
cls_state = outputs.last_hidden_state[:, 0]
|
| 96 |
+
mean_state = self._masked_mean(outputs.last_hidden_state, attention_mask)
|
| 97 |
+
max_state = self._masked_max(outputs.last_hidden_state, attention_mask)
|
| 98 |
+
pooled_state = self.dropout(torch.cat([cls_state, mean_state, max_state], dim=-1))
|
| 99 |
+
logits = self.classifier(pooled_state)
|
| 100 |
+
return logits
|
| 101 |
+
|
| 102 |
+
model = MarbertMultiTask("UBC-NLP/MARBERTv2", pooling_strategy="cls_mean_max")
|
| 103 |
+
state_dict = torch.load(os.path.join(MODEL_DIR, "model.pt"), map_location="cpu")
|
| 104 |
+
model.load_state_dict(state_dict)
|
| 105 |
+
model.eval()
|
| 106 |
+
|
| 107 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
|
| 108 |
+
with open(os.path.join(MODEL_DIR, "label_map.json"), encoding="utf-8") as f:
|
| 109 |
+
label_map = json.load(f)
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
## Limitations
|
| 113 |
+
|
| 114 |
+
- The top class is built from open-source proxies for incitement, not a gold incitement-only annotation project.
|
| 115 |
+
- Performance is best on Levantine political/social text and may degrade on other Arabic varieties or platforms.
|
| 116 |
+
- The confusion matrix in this card is from the full-data training run and should not be treated as held-out evaluation.
|
checkpoint-1748/model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:17490a58e11a2f0b010147faf35d59deb9213b71bd8e2b4232f19514292219ad
|
| 3 |
+
size 651426560
|
checkpoint-1748/optimizer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3ac3774da3dc92b6121a4beeae1e7a0f448dc53bc40a15e3da3a6cd06fab3b3c
|
| 3 |
+
size 340377291
|
checkpoint-1748/rng_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b85e51f1b32ba6c5e5ee05aef206f3d2a0346e1e2f6b7172203054c3aa73614
|
| 3 |
+
size 14709
|
checkpoint-1748/scaler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ad2e5787d1be4728ffadf823370726371ee5d4a156e2aba2c9dc2b59e032c2e
|
| 3 |
+
size 1383
|
checkpoint-1748/scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:929c9f4ef5e448da4bab7b0f36d9731ea203ded1e8d25831155becbbe0952e32
|
| 3 |
+
size 1465
|
checkpoint-1748/trainer_state.json
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_global_step": null,
|
| 3 |
+
"best_metric": null,
|
| 4 |
+
"best_model_checkpoint": null,
|
| 5 |
+
"epoch": 4.0,
|
| 6 |
+
"eval_steps": 500,
|
| 7 |
+
"global_step": 1748,
|
| 8 |
+
"is_hyper_param_search": false,
|
| 9 |
+
"is_local_process_zero": true,
|
| 10 |
+
"is_world_process_zero": true,
|
| 11 |
+
"log_history": [
|
| 12 |
+
{
|
| 13 |
+
"epoch": 1.0,
|
| 14 |
+
"grad_norm": 4.120875835418701,
|
| 15 |
+
"learning_rate": 4.170375079465988e-06,
|
| 16 |
+
"loss": 1.8289,
|
| 17 |
+
"step": 437
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 2.0,
|
| 21 |
+
"grad_norm": 1.2741719484329224,
|
| 22 |
+
"learning_rate": 2.781309599491418e-06,
|
| 23 |
+
"loss": 1.287,
|
| 24 |
+
"step": 874
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"epoch": 3.0,
|
| 28 |
+
"grad_norm": 2.3260374069213867,
|
| 29 |
+
"learning_rate": 1.3922441195168468e-06,
|
| 30 |
+
"loss": 1.2288,
|
| 31 |
+
"step": 1311
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"epoch": 4.0,
|
| 35 |
+
"grad_norm": 26.597824096679688,
|
| 36 |
+
"learning_rate": 3.178639542275906e-09,
|
| 37 |
+
"loss": 1.2176,
|
| 38 |
+
"step": 1748
|
| 39 |
+
}
|
| 40 |
+
],
|
| 41 |
+
"logging_steps": 500,
|
| 42 |
+
"max_steps": 1748,
|
| 43 |
+
"num_input_tokens_seen": 0,
|
| 44 |
+
"num_train_epochs": 4,
|
| 45 |
+
"save_steps": 500,
|
| 46 |
+
"stateful_callbacks": {
|
| 47 |
+
"TrainerControl": {
|
| 48 |
+
"args": {
|
| 49 |
+
"should_epoch_stop": false,
|
| 50 |
+
"should_evaluate": false,
|
| 51 |
+
"should_log": false,
|
| 52 |
+
"should_save": true,
|
| 53 |
+
"should_training_stop": true
|
| 54 |
+
},
|
| 55 |
+
"attributes": {}
|
| 56 |
+
}
|
| 57 |
+
},
|
| 58 |
+
"total_flos": 0.0,
|
| 59 |
+
"train_batch_size": 16,
|
| 60 |
+
"trial_name": null,
|
| 61 |
+
"trial_params": null
|
| 62 |
+
}
|
checkpoint-1748/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:274259ee33913acedabcfb1e8abe7fc4015bbb0f0dfc761cba9762cf9aa74bda
|
| 3 |
+
size 5905
|
confusion_matrix.csv
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
,pred_normal,pred_abusive,pred_incitement
|
| 2 |
+
true_normal,6733,1069,75
|
| 3 |
+
true_abusive,481,3948,468
|
| 4 |
+
true_incitement,4,43,1132
|
confusion_matrix.png
ADDED
|
label_map.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"0": "normal",
|
| 3 |
+
"1": "abusive",
|
| 4 |
+
"2": "incitement"
|
| 5 |
+
}
|
model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:be519b32387d9988d14d71b5aef7510ed1a265eb3ddc7e1b85ea7df52b04dc2d
|
| 3 |
+
size 651472903
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:17490a58e11a2f0b010147faf35d59deb9213b71bd8e2b4232f19514292219ad
|
| 3 |
+
size 651426560
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cls_token": "[CLS]",
|
| 3 |
+
"mask_token": "[MASK]",
|
| 4 |
+
"pad_token": "[PAD]",
|
| 5 |
+
"sep_token": "[SEP]",
|
| 6 |
+
"unk_token": "[UNK]"
|
| 7 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "[PAD]",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "[UNK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "[CLS]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "[SEP]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"4": {
|
| 36 |
+
"content": "[MASK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"clean_up_tokenization_spaces": true,
|
| 45 |
+
"cls_token": "[CLS]",
|
| 46 |
+
"do_basic_tokenize": true,
|
| 47 |
+
"do_lower_case": true,
|
| 48 |
+
"extra_special_tokens": {},
|
| 49 |
+
"mask_token": "[MASK]",
|
| 50 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 51 |
+
"never_split": null,
|
| 52 |
+
"pad_token": "[PAD]",
|
| 53 |
+
"sep_token": "[SEP]",
|
| 54 |
+
"strip_accents": null,
|
| 55 |
+
"tokenize_chinese_chars": true,
|
| 56 |
+
"tokenizer_class": "BertTokenizer",
|
| 57 |
+
"unk_token": "[UNK]"
|
| 58 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:274259ee33913acedabcfb1e8abe7fc4015bbb0f0dfc761cba9762cf9aa74bda
|
| 3 |
+
size 5905
|
training_metadata.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "UBC-NLP/MARBERTv2",
|
| 3 |
+
"max_length": 160,
|
| 4 |
+
"num_epochs": 4,
|
| 5 |
+
"learning_rate": 5e-06,
|
| 6 |
+
"train_batch_size": 16,
|
| 7 |
+
"gradient_accumulation_steps": 2,
|
| 8 |
+
"freeze_embeddings": true,
|
| 9 |
+
"freeze_bottom_n_layers": 6,
|
| 10 |
+
"pooling_strategy": "cls_mean_max",
|
| 11 |
+
"classifier_input_dim": 2304,
|
| 12 |
+
"class_weights": [
|
| 13 |
+
0.5904532074928284,
|
| 14 |
+
0.949765145778656,
|
| 15 |
+
3.944868564605713
|
| 16 |
+
],
|
| 17 |
+
"cost_matrix": [
|
| 18 |
+
[
|
| 19 |
+
1.0,
|
| 20 |
+
1.0,
|
| 21 |
+
1.0
|
| 22 |
+
],
|
| 23 |
+
[
|
| 24 |
+
1.0,
|
| 25 |
+
1.0,
|
| 26 |
+
1.0
|
| 27 |
+
],
|
| 28 |
+
[
|
| 29 |
+
3.0,
|
| 30 |
+
2.0,
|
| 31 |
+
1.0
|
| 32 |
+
]
|
| 33 |
+
],
|
| 34 |
+
"cost_loss_weight": 0.75,
|
| 35 |
+
"ordinal_loss_weight": 0.2,
|
| 36 |
+
"lexicon_aux_loss_weight": 0.3,
|
| 37 |
+
"lexicon_false_negative_boost": 1.75,
|
| 38 |
+
"rows": 13953,
|
| 39 |
+
"label_counts": {
|
| 40 |
+
"normal": 7877,
|
| 41 |
+
"abusive": 4897,
|
| 42 |
+
"incitement": 1179
|
| 43 |
+
},
|
| 44 |
+
"kfold_accuracy": 0.824,
|
| 45 |
+
"kfold_f1_macro": 0.8025,
|
| 46 |
+
"kfold_f1_incitement": 0.7752
|
| 47 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|