

Update model card for Greek
Browse files
README.md
CHANGED
|
@@ -1,60 +1,70 @@
|
|
| 1 |
-
---
|
| 2 |
-
pipeline_tag: sentence-similarity
|
| 3 |
-
language: ell
|
| 4 |
-
license: mit
|
| 5 |
-
tags:
|
| 6 |
-
- trimmed
|
| 7 |
-
library_name: sentence-transformers
|
| 8 |
-
base_model: intfloat/multilingual-e5-large-instruct
|
| 9 |
-
base_model_relation: quantized
|
| 10 |
-
datasets:
|
| 11 |
-
-
|
| 12 |
-
---
|
| 13 |
-
|
| 14 |
-
# multilingual-e5-large-instruct-ell-16384
|
| 15 |
-
This model is a 42.73% smaller version of [intfloat/multilingual-e5-large-instruct](https://huggingface.co/intfloat/multilingual-e5-large-instruct) optimized for
|
| 16 |
-
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
|
| 17 |
-
|
| 18 |
-
## Model Statistics
|
| 19 |
-
| Metric | Original | Trimmed | Reduction |
|
| 20 |
-
|--------|----------|---------|-----------|
|
| 21 |
-
| **Vocabulary size** | 250,
|
| 22 |
-
| **Model size** | 559,890,432 params | 320,665,600 params | **42.73%** |
|
| 23 |
-
|
| 24 |
-

|
| 43 |
-
document_embeddings = model.encode_document(documents)
|
| 44 |
-
print(query_embeddings.shape, document_embeddings.shape)
|
| 45 |
-
# Compute similarities to determine a ranking
|
| 46 |
-
similarities = model.similarity(query_embeddings, document_embeddings)
|
| 47 |
-
print(similarities)
|
| 48 |
-
```
|
| 49 |
-
|
| 50 |
-
##
|
| 51 |
-
|
| 52 |
-
#### Multilingual E5
|
| 53 |
-
```
|
| 54 |
-
@article{wang2024multilingual,
|
| 55 |
-
title={Multilingual E5 Text Embeddings: A Technical Report},
|
| 56 |
-
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
|
| 57 |
-
journal={arXiv preprint arXiv:2402.05672},
|
| 58 |
-
year={2024}
|
| 59 |
-
}
|
| 60 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: sentence-similarity
|
| 3 |
+
language: ell
|
| 4 |
+
license: mit
|
| 5 |
+
tags:
|
| 6 |
+
- trimmed
|
| 7 |
+
library_name: sentence-transformers
|
| 8 |
+
base_model: intfloat/multilingual-e5-large-instruct
|
| 9 |
+
base_model_relation: quantized
|
| 10 |
+
datasets:
|
| 11 |
+
- lbourdois/fineweb-2-trimming
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# multilingual-e5-large-instruct-ell-16384
|
| 15 |
+
This model is a **42.73% smaller** version of [intfloat/multilingual-e5-large-instruct](https://huggingface.co/intfloat/multilingual-e5-large-instruct) optimized for **Greek** language via vocabulary size reduction using the [trimming](https://huggingface.co/blog/lbourdois/introduction-to-trimming) method.
|
| 16 |
+
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
|
| 17 |
+
|
| 18 |
+
## Model Statistics
|
| 19 |
+
| Metric | Original | Trimmed | Reduction |
|
| 20 |
+
|--------|----------|---------|-----------|
|
| 21 |
+
| **Vocabulary size** | 250,037 tokens | 16,384 tokens | **93.44%** |
|
| 22 |
+
| **Model size** | 559,890,432 params | 320,665,600 params | **42.73%** |
|
| 23 |
+
|
| 24 |
+
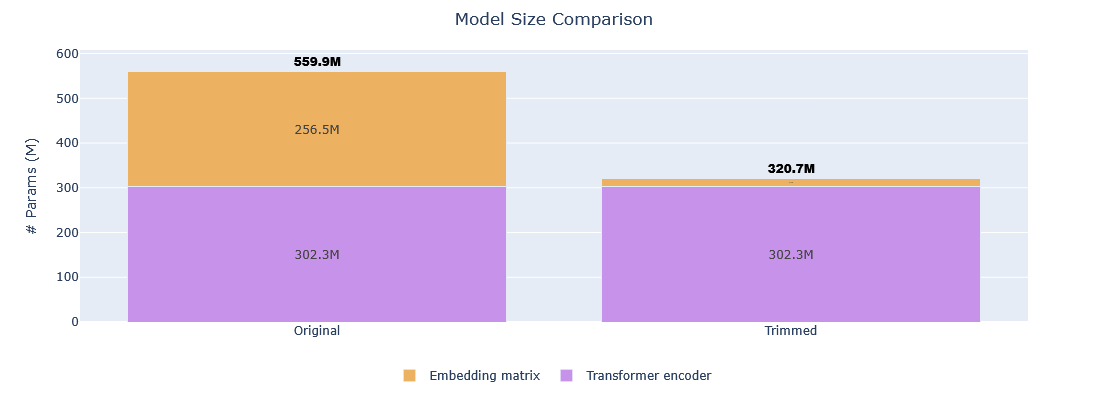
|
| 25 |
+
|
| 26 |
+
## Mining Dataset Statistics
|
| 27 |
+
- **Number of texts used for mining**: 200,000 texts
|
| 28 |
+
- **Dataset**: [lbourdois/fineweb-2-trimming](https://huggingface.co/datasets/lbourdois/fineweb-2-trimming)
|
| 29 |
+
|
| 30 |
+
## Usage
|
| 31 |
+
```python
|
| 32 |
+
from sentence_transformers import SentenceTransformer
|
| 33 |
+
# Download from the 🤗 Hub
|
| 34 |
+
model = SentenceTransformer("alphaedge-ai/multilingual-e5-large-instruct-ell-16384")
|
| 35 |
+
# Run inference with queries and documents
|
| 36 |
+
query = "My query in Greek"
|
| 37 |
+
documents = [
|
| 38 |
+
"Chunk in Greek",
|
| 39 |
+
"Chunk in Greek",
|
| 40 |
+
"Chunk in Greek",
|
| 41 |
+
]
|
| 42 |
+
query_embeddings = model.encode_query(query)
|
| 43 |
+
document_embeddings = model.encode_document(documents)
|
| 44 |
+
print(query_embeddings.shape, document_embeddings.shape)
|
| 45 |
+
# Compute similarities to determine a ranking
|
| 46 |
+
similarities = model.similarity(query_embeddings, document_embeddings)
|
| 47 |
+
print(similarities)
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Citations
|
| 51 |
+
|
| 52 |
+
#### Multilingual E5
|
| 53 |
+
```
|
| 54 |
+
@article{wang2024multilingual,
|
| 55 |
+
title={Multilingual E5 Text Embeddings: A Technical Report},
|
| 56 |
+
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
|
| 57 |
+
journal={arXiv preprint arXiv:2402.05672},
|
| 58 |
+
year={2024}
|
| 59 |
+
}
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
#### Trimming blog post
|
| 63 |
+
```
|
| 64 |
+
@misc{hf_blogpost_trimming,
|
| 65 |
+
title={Introduction to Trimming},
|
| 66 |
+
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
|
| 67 |
+
year={2026},
|
| 68 |
+
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
|
| 69 |
+
}
|
| 70 |
+
```
|