---
language:
- bn
license: apache-2.0
library_name: transformers
tags:
- text-generation-inference
datasets:
- Polygl0t/gigakriya-v1
metrics:
- perplexity
pipeline_tag: text-generation
model-index:
- name: GigaKriya-ablation-NonEDU-1.5B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: ARC Challenge (Bengali)
type: Polygl0t/ARC-poly
split: test
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 24.29
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (Bengali)
type: Polygl0t/HellaSwag-poly
split: validation
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 29.13
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (Bengali)
type: Polygl0t/MMLU-poly
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 24.49
name: accuracy
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: BOOLQ (Bengali)
type: Polygl0t/BOOLQ
split: test
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 51.85
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: PIQA (Bengali)
type: Polygl0t/PIQA
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 48.96
name: accuracy
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: OpenBookQA (Bengali)
type: Polygl0t/OpenBookQA
split: test
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 20.72
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: CommonsenseQA (Bengali)
type: Polygl0t/CommonsenseQA
split: test
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 28.09
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
- task:
type: text-generation
name: Text Generation
dataset:
name: Bangla MMLU
type: Polygl0t/BanglaMMLU
split: test
args:
num_few_shot: 5
metrics:
- type: acc_norm
value: 24.74
name: accuracy (normalized)
source:
url: https://github.com/Polygl0t/lm-evaluation-harness
name: Language Model Evaluation Harness (branch=polyglot_harness_bengali)
---
# GigaKriya-ablation-NonEDU-1.5B
## Model Summary
**[GigaKriya-ablation-NonEDU-1.5B](https://huggingface.co/Polygl0t/GigaKriya-ablation-NonEDU-1.5B)** is a decoder-transformer natively pretrained in Bengali. This model is part of an ablation study to measure the impact of our educational data filtering/augmentation strategy on the downstream performance of models trained with [GigaKriya](https://huggingface.co/datasets/Polygl0t/GigaKriya-v1). GigaKriya-ablation-NonEDU-1.5B was trained with ~34 billion tokens, those being a mixture of the non-educational portion of GigaKriya (i.e., samples with an Edu Score < 3). This model has 1.5 billion parameters and a context length of 4096 tokens.
## Details
- **Architecture:** a Transformer-based model ([`llama`](https://huggingface.co/docs/transformers/main/en/model_doc/llama))
- **Size:** 1,510,066,176 parameters
- **Context length:** 4096 tokens
- **Dataset(s):**
- [GigaKriya](https://huggingface.co/datasets/Polygl0t/GigaKriya-v1) (non-educational subset, Edu Score < 3)
- **Language(s):** Bengali
- **Batch size:** 2,097,152 tokens
- **Number of steps:** 16,000
- **GPU:** 16 NVIDIA A40 (48 GB)
- **Training time**: ~60.49 hours
- **Emissions:** 94.44 KgCO2 (Germany)
- **Total energy consumption:** 247.90 kWh
This repository has the [source code](https://github.com/Polygl0t/llm-foundry) used to train this model. The complete configuration used for training is available in the following config file:
- Single stage (linear warmup with cosine decay): [training_config.yaml](training_config.yaml)
The main branch of this repository contains the final checkpoint saved at step 16,000. All other checkpoints are available as separate branches. To load a specific checkpoint, you can use the following code snippet:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "Polygl0t/GigaKriya-ablation-NonEDU-1.5B"
revision = "step-2000" # Change this to the desired checkpoint branch
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, revision=revision)
```
Or, you can access all the revisions for the models via the following code snippet:
```python
from huggingface_hub import list_repo_refs
out = list_repo_refs("Polygl0t/GigaKriya-ablation-NonEDU-1.5B")
branches = [b.name for b in out.branches]
print(branches)
```
## Intended Uses
The primary intended use of this model is to serve as a baseline for evaluating the impact of data quality and filtering on Bengali language model performance. Researchers and practitioners can use this model as a reference point for further ablation studies or for comparison with other models trained on different data mixtures.
## Basic usage
```python
from transformers import GenerationConfig, TextGenerationPipeline, AutoTokenizer, AutoModelForCausalLM
import torch
# Specify the model and tokenizer
model_id = "Polygl0t/GigaKriya-ablation-NonEDU-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Specify the generation parameters as you like
generation_config = GenerationConfig(
**{
"do_sample": True,
"max_new_tokens": 150,
"renormalize_logits": True,
"repetition_penalty": 1.2,
"temperature": 0.1,
"top_k": 50,
"top_p": 1.0,
"use_cache": True,
}
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
generator = TextGenerationPipeline(model=model, task="text-generation", tokenizer=tokenizer, device=device)
# Generate text
prompt = "ভারতের রাজধানী কী ?"
completion = generator(prompt, generation_config=generation_config)
print(completion[0]['generated_text'])
```
## Evaluations
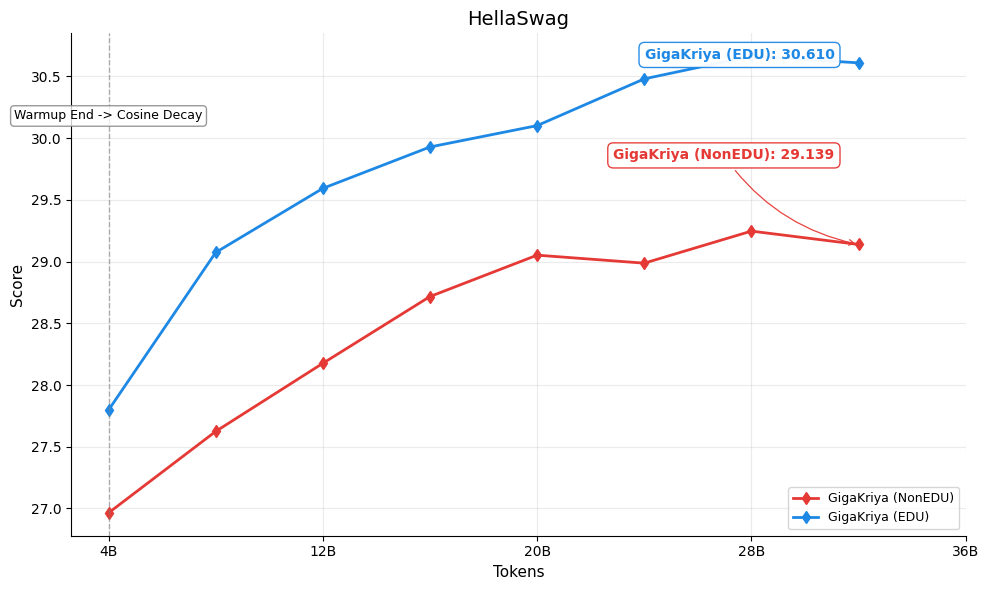
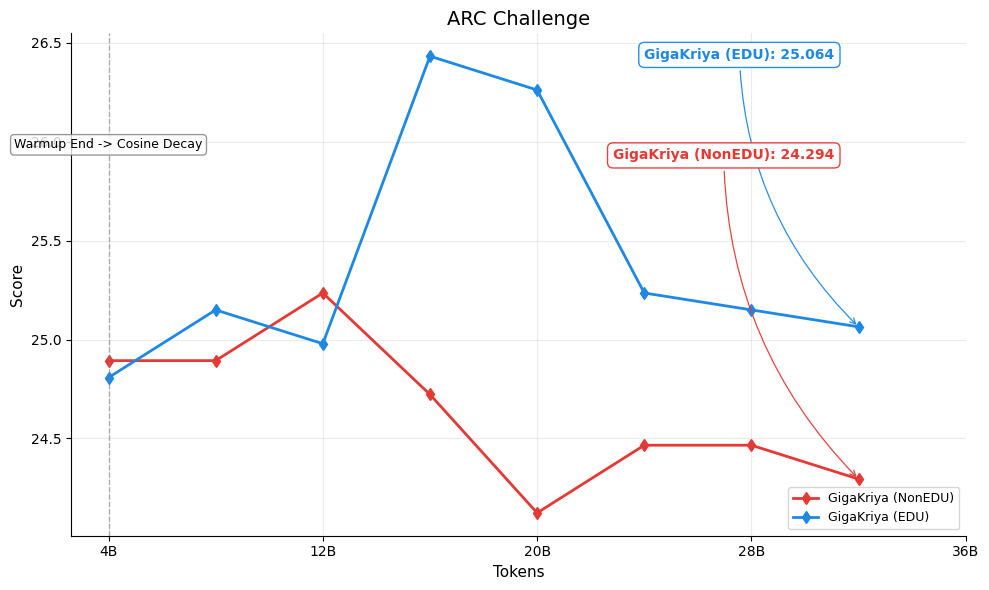
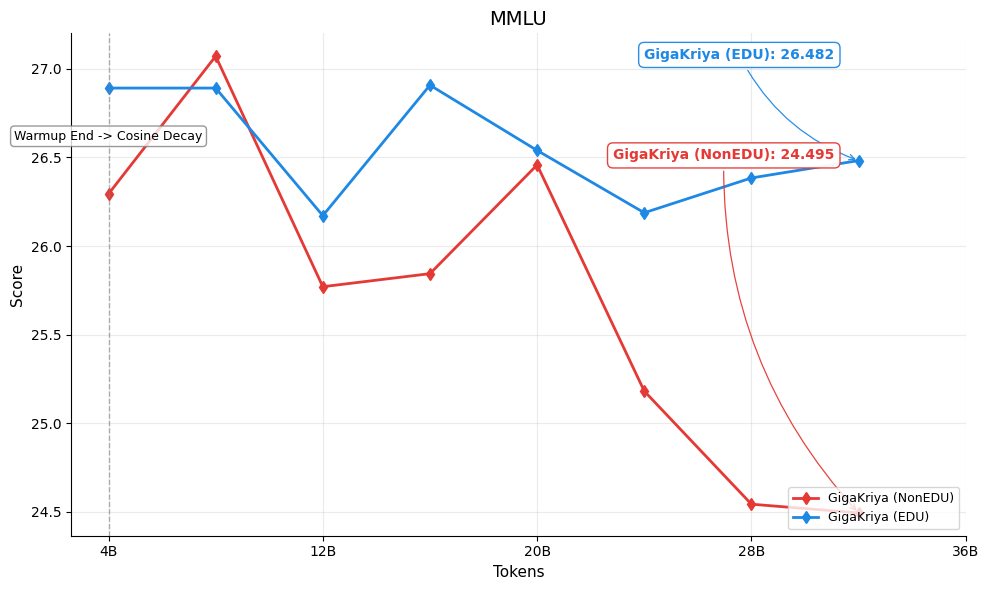
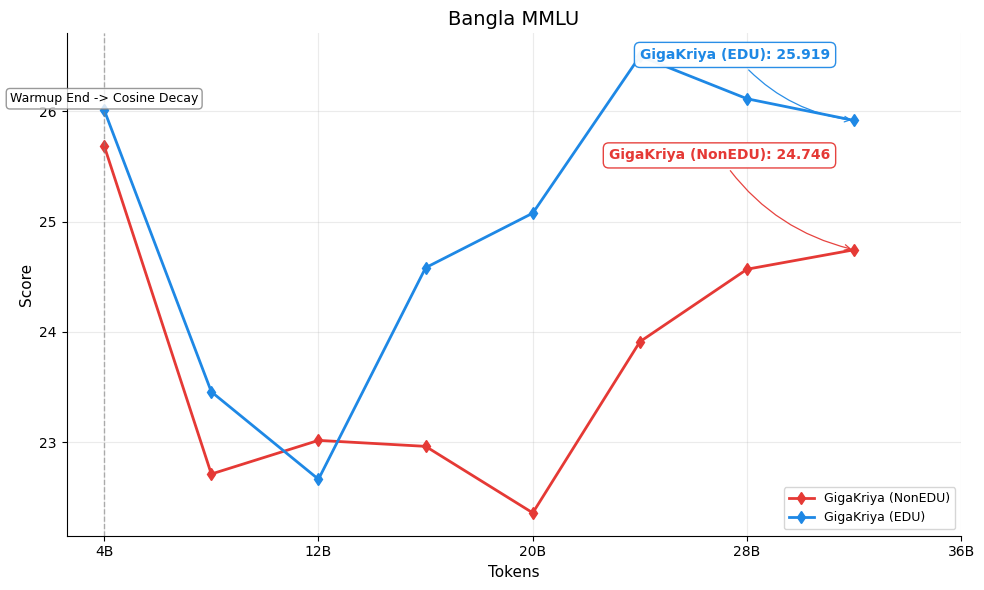
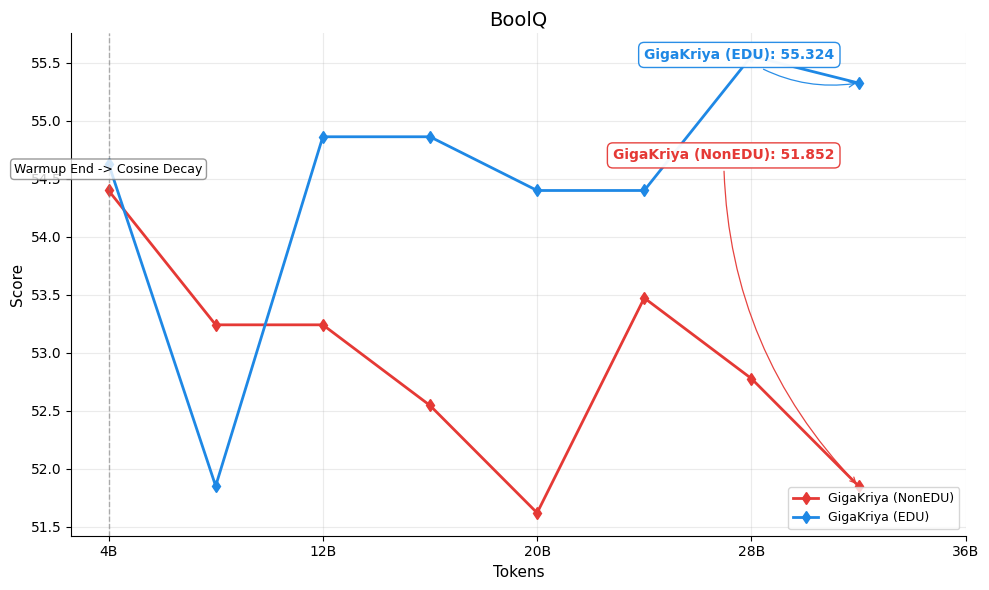
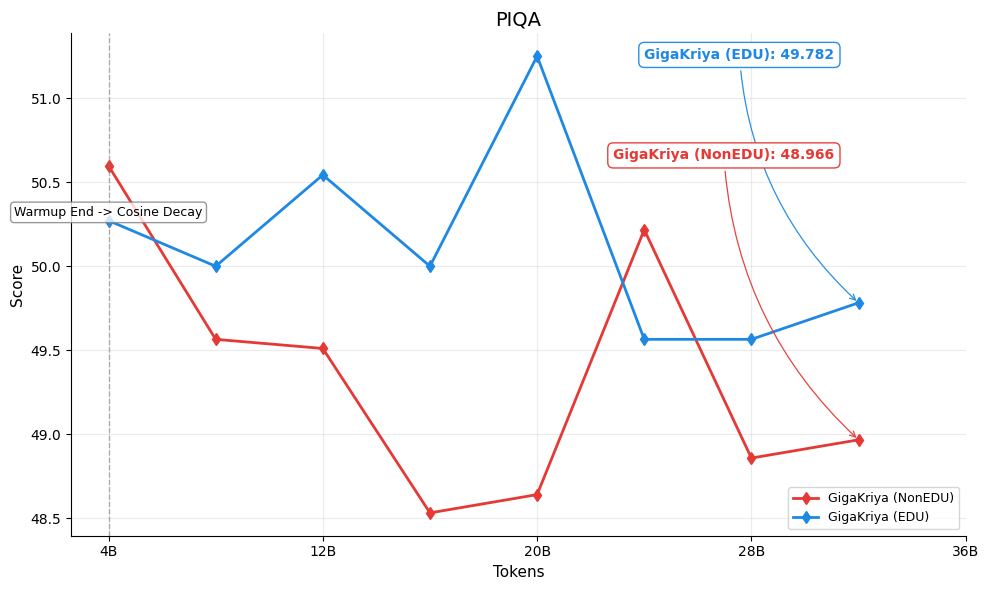
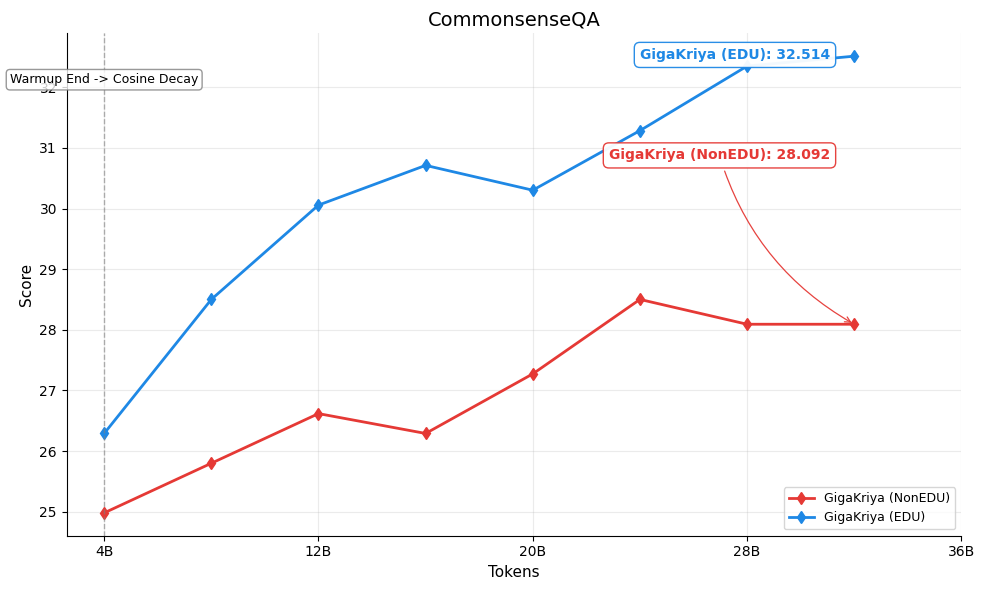
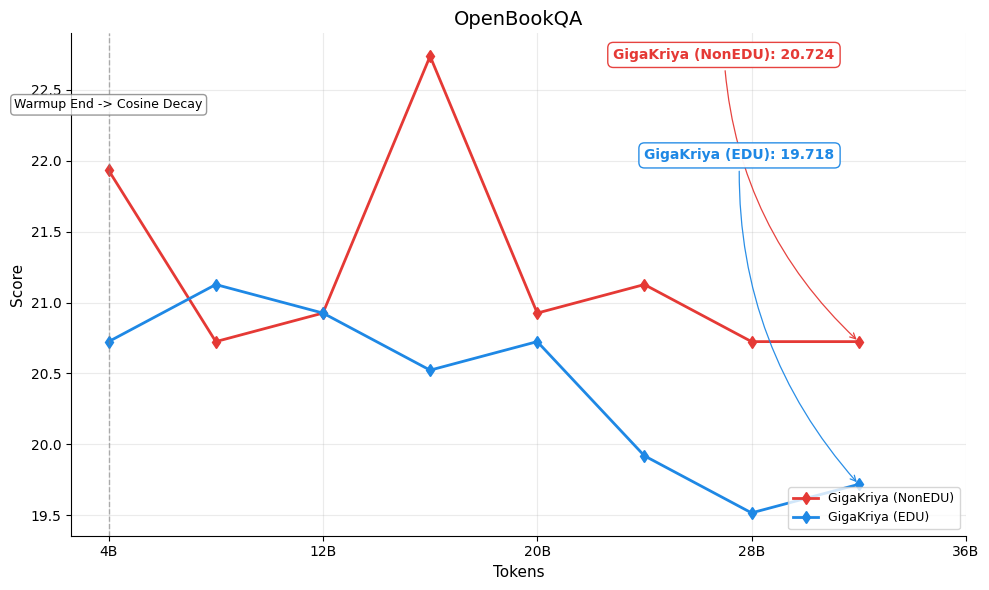
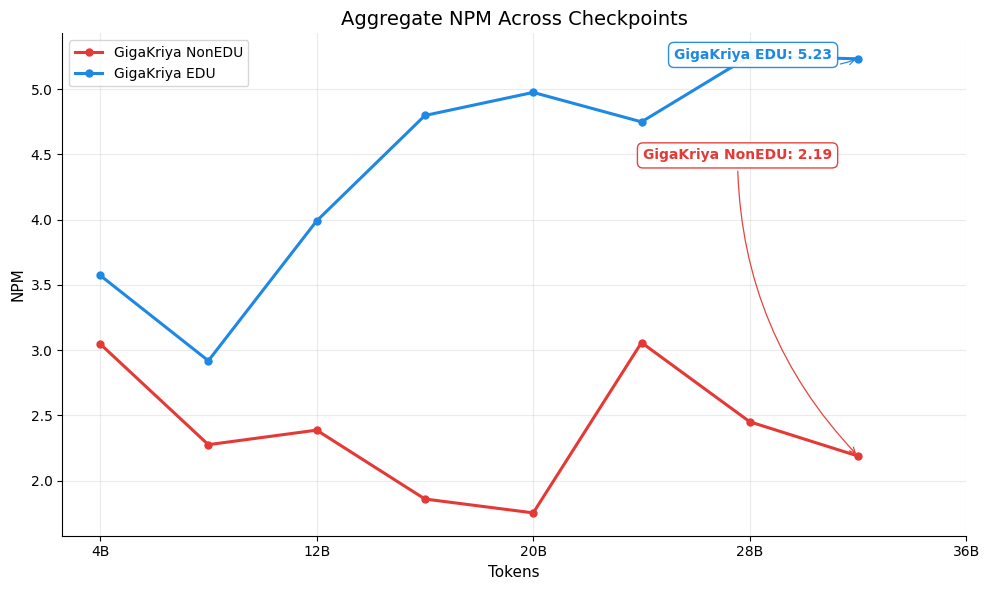
Figures below show the per-benchmark performance of [GigaKriya-ablation-EDU-1.5B](https://huggingface.co/Polygl0t/GigaKriya-ablation-EDU-1.5B) (educational subset, Edu Score >= 3) compared to [GigaKriya-ablation-NonEDU-1.5B](https://huggingface.co/Polygl0t/GigaKriya-ablation-NonEDU-1.5B) (non educational subset, Edu Score < 3). *GigaKriya-Edu* outperforms *GigaKriya-NonEdu* on 7 of 8 benchmarks and achieves a higher NPM score. These results suggest that training on educationally curated content consistently yields stronger language understanding.
🏆 HellaSwag
🏆 ARC Challenge
🏆 MMLU
🏆 Bangla MMLU
🏆 BoolQ
🏆PIQA
🏆CommonsenseQA
🏆OpenbookQA
Aggregate NPM Across Benchmarks
## Cite as 🤗
```latex
@misc{fatimah2026liltii,
title={{LilTii: A 0.6B Bengali Language Model that Outperforms Qwen}},
author={Shiza Fatimah and Aniket Sen and Sophia Falk and Florian Mai and Lucie Flek and Nicholas Kluge Corr{\^e}a},
year={2026},
howpublished={\url{https://hf.co/blog/Polygl0t/liltii}}
}
```
## Aknowlegments
Polyglot is a project funded by the Federal Ministry of Education and Research (BMBF) and the Ministry of Culture and Science of the State of North Rhine-Westphalia (MWK) as part of TRA Sustainable Futures (University of Bonn) and the Excellence Strategy of the federal and state governments.
We also gratefully acknowledge the granted access to the [Marvin cluster](https://www.hpc.uni-bonn.de/en/systems/marvin) hosted by [University of Bonn](https://www.uni-bonn.de/en) along with the support provided by its High Performance Computing & Analytics Lab.
## License
This model is licensed under the Apache License, Version 2.0. For more details, see the [LICENSE](LICENSE) file.