
xuebi commited on
Commit ·
2a60e16
0
Parent(s):
initial commit
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +36 -0
- LICENSE +17 -0
- README.md +88 -0
- added_tokens.json +63 -0
- chat_template.jinja +247 -0
- config.json +356 -0
- configuration_minimax_m3_vl.py +111 -0
- figures/benchmark.jpeg +3 -0
- figures/efficiency_gqa_vs_msa.png +0 -0
- figures/logo.svg +16 -0
- generation_config.json +8 -0
- image_processor.py +223 -0
- merges.txt +0 -0
- model-00001-of-00031.safetensors +3 -0
- model-00002-of-00031.safetensors +3 -0
- model-00003-of-00031.safetensors +3 -0
- model-00004-of-00031.safetensors +3 -0
- model-00005-of-00031.safetensors +3 -0
- model-00006-of-00031.safetensors +3 -0
- model-00007-of-00031.safetensors +3 -0
- model-00008-of-00031.safetensors +3 -0
- model-00009-of-00031.safetensors +3 -0
- model-00010-of-00031.safetensors +3 -0
- model-00011-of-00031.safetensors +3 -0
- model-00012-of-00031.safetensors +3 -0
- model-00013-of-00031.safetensors +3 -0
- model-00014-of-00031.safetensors +3 -0
- model-00015-of-00031.safetensors +3 -0
- model-00016-of-00031.safetensors +3 -0
- model-00017-of-00031.safetensors +3 -0
- model-00018-of-00031.safetensors +3 -0
- model-00019-of-00031.safetensors +3 -0
- model-00020-of-00031.safetensors +3 -0
- model-00021-of-00031.safetensors +3 -0
- model-00022-of-00031.safetensors +3 -0
- model-00023-of-00031.safetensors +3 -0
- model-00024-of-00031.safetensors +3 -0
- model-00025-of-00031.safetensors +3 -0
- model-00026-of-00031.safetensors +3 -0
- model-00027-of-00031.safetensors +3 -0
- model-00028-of-00031.safetensors +3 -0
- model-00029-of-00031.safetensors +3 -0
- model-00030-of-00031.safetensors +3 -0
- model-00031-of-00031.safetensors +3 -0
- preprocessor_config.json +32 -0
- processing_minimax.py +254 -0
- special_tokens_map.json +16 -0
- tokenizer.json +0 -0
- tokenizer_config.json +501 -0
- video_processor.py +208 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
figures/benchmark.jpeg filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MINIMAX COMMUNITY LICENSE
|
| 2 |
+
Copyright (c) 2026 MiniMax
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software for non-commercial purposes, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or provide copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
| 4 |
+
1. The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 5 |
+
2. If the Software (or any derivative works thereof) is used for any Commercial Use for your products or services:
|
| 6 |
+
1. you shall prominently display “Built with MiniMax M3” on a related website, user interface, blogpost, about page or product documentation.
|
| 7 |
+
2. you shall obtain a separate, prior written authorization from MiniMax by contacting api@minimax.io with the subject line “M3 licensing - authorization request”, if such products and services generate more than 20 million US dollars (or equivalent in other currencies) in yearly revenue; otherwise, you only need to send a one-time notice to api@minimax.io with the subject “M3 licensing — notice”.
|
| 8 |
+
3. “Commercial Use” means any use of the Software or any derivative work thereof that is primarily intended for commercial advantage or monetary compensation, which includes, without limitation: (i) offering products or services to third parties for a fee, which utilize, incorporate, or rely on the Software or its derivatives, (ii) the commercial use of APIs provided by or for the Software or its derivatives, including to support or enable commercial products, services, or operations, whether in a cloud-based, hosted, or other similar environment, and (iii) the deployment or provision of the Software or its derivatives that have been subjected to post-training, fine-tuning, instruction-tuning, or any other form of modification, for any commercial purpose.
|
| 9 |
+
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 10 |
+
|
| 11 |
+
Appendix: Prohibited Uses
|
| 12 |
+
You agree you will not use, or allow others to use, the Software or any derivatives of the Software to:
|
| 13 |
+
1. Generate or disseminate content prohibited by applicable laws or regulations.
|
| 14 |
+
2. Assist with, engage in or otherwise support any military purpose.
|
| 15 |
+
3. Exploit, harm, or attempt to exploit or harm minors.
|
| 16 |
+
4. Generate or disseminate false or misleading information with the intent to cause harm.
|
| 17 |
+
5. Promote discrimination, hate speech, or harmful behavior against individuals or groups based on race or ethnic origin, religion, disability, age, nationality and national origin, veteran status, sexual orientation, gender or gender identity, caste, immigration status, or any other characteristic that is associated with systemic discrimination or marginalization.
|
README.md
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pipeline_tag: image-text-to-text
|
| 3 |
+
license: other
|
| 4 |
+
license_name: minimax-community
|
| 5 |
+
license_link: LICENSE
|
| 6 |
+
library_name: transformers
|
| 7 |
+
tags:
|
| 8 |
+
- multimodal
|
| 9 |
+
- moe
|
| 10 |
+
- agent
|
| 11 |
+
- coding
|
| 12 |
+
- video
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+
<div align="center">
|
| 16 |
+
<img width="60%" src="figures/logo.svg" alt="MiniMax">
|
| 17 |
+
</div>
|
| 18 |
+
<hr>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<a href="https://agent.minimax.io/" target="_blank"><img src="https://img.shields.io/badge/MiniMax%20Agent-FF6C37?style=for-the-badge&logo=minimax&logoColor=white" alt="MiniMax Agent"></a>
|
| 22 |
+
<a href="https://platform.minimax.io/docs/guides/text-generation" target="_blank"><img src="https://img.shields.io/badge/API-FF6C37?style=for-the-badge&logo=minimax&logoColor=white" alt="API"></a>
|
| 23 |
+
<a href="https://www.minimax.io" target="_blank"><img src="https://img.shields.io/badge/MiniMax%20Website-FF6C37?style=for-the-badge&logo=minimax&logoColor=white" alt="MiniMax Website"></a>
|
| 24 |
+
<br>
|
| 25 |
+
<a href="https://platform.minimaxi.com/docs/faq/contact-us" target="_blank"><img src="https://img.shields.io/badge/WeChat-07C160?style=for-the-badge&logo=wechat&logoColor=white" alt="WeChat"></a>
|
| 26 |
+
<a href="https://discord.com/invite/DPC4AHFCBw" target="_blank"><img src="https://img.shields.io/badge/Discord-5865F2?style=for-the-badge&logo=discord&logoColor=white" alt="Discord"></a>
|
| 27 |
+
<a href="https://huggingface.co/MiniMaxAI" target="_blank"><img src="https://img.shields.io/badge/Hugging%20Face-FFD21E?style=for-the-badge&logo=huggingface&logoColor=black" alt="Hugging Face"></a>
|
| 28 |
+
<a href="https://github.com/MiniMax-AI/MiniMax-M3" target="_blank"><img src="https://img.shields.io/badge/GitHub-181717?style=for-the-badge&logo=github&logoColor=white" alt="GitHub"></a>
|
| 29 |
+
<a href="https://arxiv.org/abs/2606.13392" target="_blank"><img src="https://img.shields.io/badge/arXiv-2606.13392-B31B1B?style=for-the-badge&logo=arxiv&logoColor=white" alt="arXiv Paper"></a>
|
| 30 |
+
<a href="https://huggingface.co/MiniMaxAI/MiniMax-M3/blob/main/LICENSE" target="_blank"><img src="https://img.shields.io/badge/LICENSE-4CAF50?style=for-the-badge&logo=creativecommons&logoColor=white" alt="LICENSE"></a>
|
| 31 |
+
</p>
|
| 32 |
+
|
| 33 |
+
MiniMax-M3 is a native multimodal model with 1M context. It has ~428B parameters and ~23B activated parameters.
|
| 34 |
+
|
| 35 |
+
**Highlights:**
|
| 36 |
+
- **Native Multimodality:** M3 undergoes mixed-modality training from the very first step, enabling deeper semantic fusion across text, image, and video.
|
| 37 |
+
- **Context Scaling via Sparse Attention:** M3 introduces MiniMax Sparse Attention (MSA) to improve long context efficiency. M3 delivers 9× prefill and 15× decode speedups compared to M2 at 1M context, reducing per-token compute to 1/20.
|
| 38 |
+
- **Coding & Cowork Capability:** M3 achieves frontier-level performance across long-horizon agentic benchmarks, excelling in both coding and cowork.
|
| 39 |
+
|
| 40 |
+
MiniMax-M3-MXFP8 is the MXFP8 quantized variant of [MiniMax-M3](https://huggingface.co/MiniMaxAI/MiniMax-M3), a native multimodal model with 1M context. It has ~428B parameters and ~23B activated parameters.
|
| 41 |
+
|
| 42 |
+
<p align="center">
|
| 43 |
+
<img width="100%" src="figures/benchmark.jpeg">
|
| 44 |
+
</p>
|
| 45 |
+
|
| 46 |
+
## MiniMax Sparse Attention (MSA)
|
| 47 |
+
|
| 48 |
+
M3 is powered by [**MiniMax Sparse Attention (MSA)**](https://github.com/MiniMax-AI/MSA), a high-performance sparse attention operator designed for million-token contexts. Compared with GQA, MSA dramatically reduces the attention compute and memory footprint while preserving model quality.
|
| 49 |
+
|
| 50 |
+
<p align="center">
|
| 51 |
+
<img width="100%" src="figures/efficiency_gqa_vs_msa.png" alt="GQA vs MSA Efficiency Comparison">
|
| 52 |
+
</p>
|
| 53 |
+
|
| 54 |
+
> 📄 Read the technical report: [arXiv:2606.13392](https://arxiv.org/abs/2606.13392) · [Hugging Face Papers](https://huggingface.co/papers/2606.13392)
|
| 55 |
+
|
| 56 |
+
## How to Use
|
| 57 |
+
|
| 58 |
+
- [MiniMax Agent](https://agent.minimax.io/)
|
| 59 |
+
- [MiniMax API](https://platform.minimax.io/)
|
| 60 |
+
|
| 61 |
+
M3 supports two reasoning modes:
|
| 62 |
+
- **thinking** — for complex reasoning, agentic tasks, and long-horizon collaboration.
|
| 63 |
+
- **non-thinking** — for latency-sensitive scenarios such as chat and code completion.
|
| 64 |
+
|
| 65 |
+
## Local Deployment
|
| 66 |
+
|
| 67 |
+
Download the model:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
hf download MiniMaxAI/MiniMax-M3 --local-dir MiniMax-M3
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
We recommend the following inference frameworks (listed alphabetically) to serve the model:
|
| 74 |
+
|
| 75 |
+
- [SGLang](https://docs.sglang.io/) - see [SGLang cookbook](https://docs.sglang.io/cookbook/autoregressive/MiniMax/MiniMax-M3).
|
| 76 |
+
|
| 77 |
+
- [vLLM](https://github.com/vllm-project/vllm) - see [vLLM recipes](https://recipes.vllm.ai/MiniMaxAI/MiniMax-M3).
|
| 78 |
+
|
| 79 |
+
- [Transformers](https://github.com/huggingface/transformers) - see [Transformers docs](https://huggingface.co/docs/transformers/model_doc/minimax_m3_vl).
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
### Inference Parameters
|
| 83 |
+
|
| 84 |
+
We recommend the following parameters for best performance: `temperature=1.0`, `top_p=0.95`, `top_k=40`.
|
| 85 |
+
|
| 86 |
+
## Contact Us
|
| 87 |
+
|
| 88 |
+
Contact us at [model@minimax.io](mailto:model@minimax.io).
|
added_tokens.json
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"]!p~[": 200000,
|
| 3 |
+
"<fim_prefix>": 200001,
|
| 4 |
+
"<fim_middle>": 200002,
|
| 5 |
+
"<fim_suffix>": 200003,
|
| 6 |
+
"<fim_pad>": 200004,
|
| 7 |
+
"<reponame>": 200005,
|
| 8 |
+
"<filename>": 200006,
|
| 9 |
+
"<gh_stars>": 200007,
|
| 10 |
+
"<issue_start>": 200008,
|
| 11 |
+
"<issue_comment>": 200009,
|
| 12 |
+
"<issue_closed>": 200010,
|
| 13 |
+
"<jupyter_start>": 200011,
|
| 14 |
+
"<jupyter_text>": 200012,
|
| 15 |
+
"<jupyter_code>": 200013,
|
| 16 |
+
"<jupyter_output>": 200014,
|
| 17 |
+
"<empty_output>": 200015,
|
| 18 |
+
"<commit_before>": 200016,
|
| 19 |
+
"<commit_msg>": 200017,
|
| 20 |
+
"<commit_after>": 200018,
|
| 21 |
+
"]~b]": 200019,
|
| 22 |
+
"[e~[": 200020,
|
| 23 |
+
"]!d~[": 200021,
|
| 24 |
+
"<function_call>": 200022,
|
| 25 |
+
"<code_interpreter>": 200023,
|
| 26 |
+
"]<]speech[>[": 200024,
|
| 27 |
+
"]<]image[>[": 200025,
|
| 28 |
+
"]<]video[>[": 200026,
|
| 29 |
+
"]<]start of speech[>[": 200027,
|
| 30 |
+
"]<]end of speech[>[": 200028,
|
| 31 |
+
"]<]start of image[>[": 200029,
|
| 32 |
+
"]<]end of image[>[": 200030,
|
| 33 |
+
"]<]start of video[>[": 200031,
|
| 34 |
+
"]<]end of video[>[": 200032,
|
| 35 |
+
"]<]vision pad[>[": 200033,
|
| 36 |
+
"]~!b[": 200034,
|
| 37 |
+
"<jupyter_error>": 200035,
|
| 38 |
+
"<add_file>": 200036,
|
| 39 |
+
"<delete_file>": 200037,
|
| 40 |
+
"<rename_file>": 200038,
|
| 41 |
+
"<edit_file>": 200039,
|
| 42 |
+
"<commit_message>": 200040,
|
| 43 |
+
"<empty_source_file>": 200041,
|
| 44 |
+
"<repo_struct>": 200042,
|
| 45 |
+
"<code_context>": 200043,
|
| 46 |
+
"<file_content>": 200044,
|
| 47 |
+
"<source_files>": 200045,
|
| 48 |
+
"<pr_start>": 200046,
|
| 49 |
+
"<review_comment>": 200047,
|
| 50 |
+
"<filepath>": 200048,
|
| 51 |
+
"<file_sep>": 200049,
|
| 52 |
+
"<think>": 200050,
|
| 53 |
+
"</think>": 200051,
|
| 54 |
+
"<tool_call>": 200052,
|
| 55 |
+
"</tool_call>": 200053,
|
| 56 |
+
"]<]frame[>[": 200054,
|
| 57 |
+
"]<]start of frame[>[": 200055,
|
| 58 |
+
"]<]end of frame[>[": 200056,
|
| 59 |
+
"<|content_altered_placeholder|>": 200057,
|
| 60 |
+
"]<]minimax[>[": 200058,
|
| 61 |
+
"<mm:think>": 200059,
|
| 62 |
+
"</mm:think>": 200060
|
| 63 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{# ---------- special token variables ---------- #}
|
| 2 |
+
{%- set ns_token = ']<]minimax[>[' -%}
|
| 3 |
+
{%- set bod_token = ']~!b[' -%}
|
| 4 |
+
{%- set bos_token = ']~b]' -%}
|
| 5 |
+
{%- set eos_token = '[e~[' -%}
|
| 6 |
+
{%- set toolcall_begin_token = ns_token ~ '<tool_call>' -%}
|
| 7 |
+
{%- set toolcall_end_token = ns_token ~ '</tool_call>' -%}
|
| 8 |
+
{%- set think_begin_token = '<mm:think>' -%}
|
| 9 |
+
{%- set think_end_token = '</mm:think>' -%}
|
| 10 |
+
{%- set image_token = ']<]image[>[' -%}
|
| 11 |
+
{%- set video_token = ']<]video[>[' -%}
|
| 12 |
+
{#- Thinking mode: "enabled" / "disabled" / "adaptive" / not defined -#}
|
| 13 |
+
{#- Recursive XML renderer for tool_call arguments ======================== -#}
|
| 14 |
+
{#- None values are intentionally skipped in mapping iteration so that
|
| 15 |
+
`<key>null</key>` (which would round-trip to the literal string "null")
|
| 16 |
+
never appears in the rendered tool_call. The convention is: omit the
|
| 17 |
+
field entirely. The top-level `_args` loop applies the same rule.
|
| 18 |
+
The `val is none` branch below is a safety net only — upstream cleaning
|
| 19 |
+
(drop_none_in_tool_arguments) should ensure no None ever reaches here. -#}
|
| 20 |
+
{%- macro to_xml(val, ns) -%}
|
| 21 |
+
{%- if val is mapping -%}
|
| 22 |
+
{%- for k, v in val.items() if v is not none -%}
|
| 23 |
+
{{ ns }}<{{ k }}>{{ to_xml(v, ns) }}{{ ns }}</{{ k }}>
|
| 24 |
+
{%- endfor -%}
|
| 25 |
+
{%- elif val is iterable and val is not string -%}
|
| 26 |
+
{%- for item in val -%}
|
| 27 |
+
{{ ns }}<item>{{ to_xml(item, ns) }}{{ ns }}</item>
|
| 28 |
+
{%- endfor -%}
|
| 29 |
+
{%- elif val is none -%}
|
| 30 |
+
{#- Should be unreachable when upstream cleaning is applied. -#}
|
| 31 |
+
{%- elif val is boolean -%}
|
| 32 |
+
{{ val | tojson }}
|
| 33 |
+
{%- else -%}
|
| 34 |
+
{{ val }}
|
| 35 |
+
{%- endif -%}
|
| 36 |
+
{%- endmacro -%}
|
| 37 |
+
{#- Tool Rendering Functions ============================================== -#}
|
| 38 |
+
{%- macro render_tool_namespace(namespace_name, tool_list) -%}
|
| 39 |
+
{%- for tool in tool_list -%}
|
| 40 |
+
<tool>{{ tool.function | tojson(ensure_ascii=False) }}</tool>
|
| 41 |
+
{% endfor -%}
|
| 42 |
+
{%- endmacro -%}
|
| 43 |
+
{%- macro visible_text(content) -%}
|
| 44 |
+
{%- if content is string -%}
|
| 45 |
+
{{ content }}
|
| 46 |
+
{%- elif content is iterable and content is not mapping -%}
|
| 47 |
+
{%- for item in content -%}
|
| 48 |
+
{%- if item is mapping and item.type == 'text' -%}
|
| 49 |
+
{{- item.text }}
|
| 50 |
+
{%- elif item is mapping and item.type == 'image' -%}
|
| 51 |
+
{{- image_token }}
|
| 52 |
+
{%- elif item is mapping and item.type == 'video' -%}
|
| 53 |
+
{{- video_token}}
|
| 54 |
+
{%- elif item is string -%}
|
| 55 |
+
{{- item }}
|
| 56 |
+
{%- endif -%}
|
| 57 |
+
{%- endfor -%}
|
| 58 |
+
{%- elif content is none -%}
|
| 59 |
+
{{- '' }}
|
| 60 |
+
{%- else -%}
|
| 61 |
+
{{- content }}
|
| 62 |
+
{%- endif -%}
|
| 63 |
+
{%- endmacro -%}
|
| 64 |
+
{#- System Message Construction ============================================ -#}
|
| 65 |
+
{%- macro build_system_message(system_message) -%}
|
| 66 |
+
{%- if system_message and system_message.content -%}
|
| 67 |
+
{{- visible_text(system_message.content) }}
|
| 68 |
+
{%- else -%}
|
| 69 |
+
{{- 'Your model version is MiniMax-M3, developed by MiniMax. Knowledge cutoff: January 2026. Founded in early 2022, MiniMax is a global AI foundation model company committed to advancing the frontiers of AI towards AGI.' }}
|
| 70 |
+
{%- endif -%}
|
| 71 |
+
|
| 72 |
+
{#- Thinking mode instructions -#}
|
| 73 |
+
{{- '\n\n<thinking_instructions>\n' }}
|
| 74 |
+
{{- 'You have a thinking capability that allows you to reason step by step before responding. When thinking is enabled, wrap your reasoning in ' ~ think_begin_token ~ think_end_token ~ ' tags before your response. When thinking is disabled, begin your response directly after the ' ~ think_end_token ~ ' prefix. When thinking is adaptive, decide on your own whether to think for the current turn.\n' }}
|
| 75 |
+
{%- if thinking_mode is defined -%}
|
| 76 |
+
{%- if thinking_mode == "enabled" -%}
|
| 77 |
+
{{- 'Current thinking mode: enabled. You MUST think step by step before every response, including after receiving function/tool results.\n' }}
|
| 78 |
+
{%- elif thinking_mode == "disabled" -%}
|
| 79 |
+
{{- 'Current thinking mode: disabled. Do not output any thinking process.\n' }}
|
| 80 |
+
{%- elif thinking_mode == "adaptive" -%}
|
| 81 |
+
{{- 'Current thinking mode: adaptive. You are encouraged to think for complex decision-making, multi-step reasoning, or when analyzing function/tool results.\n' }}
|
| 82 |
+
{%- endif -%}
|
| 83 |
+
{%- else -%}
|
| 84 |
+
{{- 'Current thinking mode: adaptive. You are encouraged to think for complex decision-making, multi-step reasoning, or when analyzing function/tool results.\n' }}
|
| 85 |
+
{%- endif -%}
|
| 86 |
+
{{- '</thinking_instructions>' }}
|
| 87 |
+
{%- endmacro -%}
|
| 88 |
+
{%- macro build_developer_message(developer_message) -%}
|
| 89 |
+
{%- if developer_message and developer_message.content -%}
|
| 90 |
+
{{- visible_text(developer_message.content) }}
|
| 91 |
+
{%- else -%}
|
| 92 |
+
{%- if model_identity is not defined -%}
|
| 93 |
+
{%- set model_identity = "You are a helpful assistant." -%}
|
| 94 |
+
{%- endif -%}
|
| 95 |
+
{{- model_identity }}
|
| 96 |
+
{%- endif -%}
|
| 97 |
+
{%- endmacro -%}
|
| 98 |
+
{#- Main Template Logic ================================================= -#}
|
| 99 |
+
{#- Role mapping: root -> system sp (high priority), system/developer -> developer sp (low priority) -#}
|
| 100 |
+
{%- set system_message = none -%}
|
| 101 |
+
{%- set developer_message = none -%}
|
| 102 |
+
{%- set conversation_messages = messages -%}
|
| 103 |
+
{%- if messages and messages[0].role == "root" -%}
|
| 104 |
+
{%- set system_message = messages[0] -%}
|
| 105 |
+
{%- set conversation_messages = messages[1:] -%}
|
| 106 |
+
{%- if conversation_messages and conversation_messages[0].role in ["system", "developer"] -%}
|
| 107 |
+
{%- set developer_message = conversation_messages[0] -%}
|
| 108 |
+
{%- set conversation_messages = conversation_messages[1:] -%}
|
| 109 |
+
{%- endif -%}
|
| 110 |
+
{%- elif messages and messages[0].role in ["system", "developer"] -%}
|
| 111 |
+
{%- set developer_message = messages[0] -%}
|
| 112 |
+
{%- set conversation_messages = messages[1:] -%}
|
| 113 |
+
{%- endif -%}
|
| 114 |
+
{#- Render system sp (higher priority, root role only) -#}
|
| 115 |
+
{{- bod_token ~ bos_token ~ 'system' ~ '\n' }}
|
| 116 |
+
{{- build_system_message(system_message) }}
|
| 117 |
+
{{- eos_token ~ '\n' }}
|
| 118 |
+
|
| 119 |
+
{#- Render developer sp (lower priority: system/developer role + tools) -#}
|
| 120 |
+
{{- bos_token ~ 'developer' ~ '\n' }}
|
| 121 |
+
{{- build_developer_message(developer_message) }}
|
| 122 |
+
{%- if tools -%}
|
| 123 |
+
{{- '\n\n' ~ '# Tools' ~ '\n' ~ 'You may call one or more tools to assist with the user query.\nHere are the tools available in JSONSchema format:' ~ '\n' }}
|
| 124 |
+
{{- '\n' ~ '<tools>' ~ '\n' }}
|
| 125 |
+
{{- render_tool_namespace("functions", tools) }}
|
| 126 |
+
{{- '</tools>' ~ '\n\n' }}
|
| 127 |
+
{{- 'To call tools, wrap all invocations in a single ' ~ toolcall_begin_token ~ toolcall_end_token ~ ' block. Parameter values containing nested objects or arrays are recursively expanded into XML elements. Example:\n' }}
|
| 128 |
+
{{- '\n' ~ toolcall_begin_token ~ '\n' }}
|
| 129 |
+
{{- ns_token + '<invoke name="tool-name-1">' }}
|
| 130 |
+
{{- ns_token + '<param-1>value-1' + ns_token + '</param-1>' }}
|
| 131 |
+
{{- ns_token + '<param-2>' }}
|
| 132 |
+
{{- ns_token + '<item>' }}
|
| 133 |
+
{{- ns_token + '<key-a>val-a' + ns_token + '</key-a>' }}
|
| 134 |
+
{{- ns_token + '<key-b>val-b' + ns_token + '</key-b>' }}
|
| 135 |
+
{{- ns_token + '</item>' }}
|
| 136 |
+
{{- ns_token + '</param-2>' }}
|
| 137 |
+
{{- ns_token + '</invoke>\n' }}
|
| 138 |
+
{{- ns_token + '<invoke name="tool-name-2">' }}
|
| 139 |
+
{{- ns_token + '<param-1>value-1' + ns_token + '</param-1>' }}
|
| 140 |
+
{{- ns_token + '</invoke>\n' }}
|
| 141 |
+
{{- toolcall_end_token }}
|
| 142 |
+
{%- endif -%}
|
| 143 |
+
{{- eos_token ~ '\n' }}
|
| 144 |
+
|
| 145 |
+
{#- Render messages -#}
|
| 146 |
+
{%- set last_tool_call = namespace(name=none) -%}
|
| 147 |
+
{%- for message in conversation_messages -%}
|
| 148 |
+
{%- if message.role == 'assistant' -%}
|
| 149 |
+
{{- bos_token ~ 'ai' ~ '\n' }}
|
| 150 |
+
|
| 151 |
+
{%- set reasoning_content = '' %}
|
| 152 |
+
{%- set content = visible_text(message.content) %}
|
| 153 |
+
{%- if message.reasoning_content is string %}
|
| 154 |
+
{%- set reasoning_content = message.reasoning_content %}
|
| 155 |
+
{%- else %}
|
| 156 |
+
{%- if think_end_token in content %}
|
| 157 |
+
{%- set reasoning_content = content.split(think_end_token)[0].strip('\n').split(think_begin_token)[-1].strip('\n') %}
|
| 158 |
+
{%- set content = content.split(think_end_token)[-1].strip('\n') %}
|
| 159 |
+
{%- endif %}
|
| 160 |
+
{%- endif %}
|
| 161 |
+
|
| 162 |
+
{%- if reasoning_content -%}
|
| 163 |
+
{#- Render thinking for every assistant turn (all-turn visible) -#}
|
| 164 |
+
{{- think_begin_token ~ reasoning_content ~ think_end_token }}
|
| 165 |
+
{%- else -%}
|
| 166 |
+
{#- No thinking rendered → prefix with think_end_token -#}
|
| 167 |
+
{{- think_end_token }}
|
| 168 |
+
{%- endif -%}
|
| 169 |
+
|
| 170 |
+
{%- if content -%}
|
| 171 |
+
{{- content }}
|
| 172 |
+
{%- endif -%}
|
| 173 |
+
{%- if message.tool_calls -%}
|
| 174 |
+
{{- toolcall_begin_token ~ '\n' }}
|
| 175 |
+
|
| 176 |
+
{%- for tool_call in message.tool_calls -%}
|
| 177 |
+
{%- if tool_call.function -%}
|
| 178 |
+
{%- set tool_call = tool_call.function -%}
|
| 179 |
+
{%- endif -%}
|
| 180 |
+
{{- ns_token + '<invoke name="' + tool_call.name + '">' }}
|
| 181 |
+
{%- set _args = tool_call.arguments -%}
|
| 182 |
+
{%- for k, v in _args.items() if v is not none %}
|
| 183 |
+
{{- ns_token + '<' + k + '>' -}}
|
| 184 |
+
{{- to_xml(v, ns_token) -}}
|
| 185 |
+
{{- ns_token + '</' + k + '>' }}
|
| 186 |
+
{%- endfor -%}
|
| 187 |
+
{{- ns_token + '</invoke>' ~ '\n' }}
|
| 188 |
+
{%- endfor -%}
|
| 189 |
+
|
| 190 |
+
{{- toolcall_end_token }}
|
| 191 |
+
{%- if message.tool_calls[-1].function -%}
|
| 192 |
+
{%- set last_tool_call.name = message.tool_calls[-1].function.name -%}
|
| 193 |
+
{%- else -%}
|
| 194 |
+
{%- set last_tool_call.name = message.tool_calls[-1].name -%}
|
| 195 |
+
{%- endif -%}
|
| 196 |
+
{%- else -%}
|
| 197 |
+
{%- set last_tool_call.name = none -%}
|
| 198 |
+
{%- endif -%}
|
| 199 |
+
{{- eos_token ~ '\n' }}
|
| 200 |
+
|
| 201 |
+
{%- elif message.role == 'tool' -%}
|
| 202 |
+
{%- if last_tool_call.name is none -%}
|
| 203 |
+
{{- raise_exception("Message has tool role, but there was no previous assistant message with a tool call!") }}
|
| 204 |
+
{%- endif -%}
|
| 205 |
+
{%- if loop.first or (conversation_messages[loop.index0 - 1].role != 'tool') -%}
|
| 206 |
+
{{- bos_token ~ 'tool' }}
|
| 207 |
+
{%- endif -%}
|
| 208 |
+
{{- '\n<response>' }}
|
| 209 |
+
{%- if message.content is string -%}
|
| 210 |
+
{{- message.content }}
|
| 211 |
+
{%- else -%}
|
| 212 |
+
{%- for tr in message.content -%}
|
| 213 |
+
{%- if tr is mapping and tr.type is defined and tr.type == 'image' -%}
|
| 214 |
+
{{- image_token }}
|
| 215 |
+
{%- elif tr is mapping and tr.type is defined and tr.type == 'video' -%}
|
| 216 |
+
{{- video_token }}
|
| 217 |
+
{%- else -%}
|
| 218 |
+
{{- tr.output if tr.output is defined else (tr.text if tr.type == 'text' and tr.text is defined else tr) }}
|
| 219 |
+
{%- endif -%}
|
| 220 |
+
{%- endfor -%}
|
| 221 |
+
{%- endif -%}
|
| 222 |
+
{{- '</response>' }}
|
| 223 |
+
{%- if loop.last or (conversation_messages[loop.index0 + 1].role != 'tool') -%}
|
| 224 |
+
{{- eos_token ~ '\n' -}}
|
| 225 |
+
{%- endif -%}
|
| 226 |
+
|
| 227 |
+
{%- elif message.role == 'user' -%}
|
| 228 |
+
{{- bos_token ~ 'user' ~ '\n' }}
|
| 229 |
+
{{- visible_text(message.content) }}
|
| 230 |
+
{{- eos_token ~ '\n' }}
|
| 231 |
+
{%- endif -%}
|
| 232 |
+
{%- endfor -%}
|
| 233 |
+
|
| 234 |
+
{#- Generation prompt -#}
|
| 235 |
+
{%- if add_generation_prompt -%}
|
| 236 |
+
{{- bos_token ~ 'ai' ~ '\n' }}
|
| 237 |
+
{%- if thinking_mode is defined and thinking_mode == "disabled" -%}
|
| 238 |
+
{{- think_end_token }}
|
| 239 |
+
{%- elif thinking_mode is defined and thinking_mode == "adaptive" -%}
|
| 240 |
+
{#- adaptive: no prefix, let model decide -#}
|
| 241 |
+
{%- elif thinking_mode is defined and thinking_mode == "enabled" -%}
|
| 242 |
+
{#- enabled or not defined: default to think -#}
|
| 243 |
+
{{- think_begin_token }}
|
| 244 |
+
{%- else -%}
|
| 245 |
+
{#- adaptive: no prefix, let model decide -#}
|
| 246 |
+
{%- endif -%}
|
| 247 |
+
{%- endif -%}
|
config.json
ADDED
|
@@ -0,0 +1,356 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"MiniMaxM3SparseForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_minimax_m3_vl.MiniMaxM3VLConfig"
|
| 7 |
+
},
|
| 8 |
+
"model_type": "minimax_m3_vl",
|
| 9 |
+
"text_config": {
|
| 10 |
+
"dtype": "bfloat16",
|
| 11 |
+
"hidden_size": 6144,
|
| 12 |
+
"intermediate_size": 3072,
|
| 13 |
+
"num_hidden_layers": 60,
|
| 14 |
+
"num_attention_heads": 64,
|
| 15 |
+
"num_key_value_heads": 4,
|
| 16 |
+
"head_dim": 128,
|
| 17 |
+
"vocab_size": 200064,
|
| 18 |
+
"max_position_embeddings": 1048576,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"use_gemma_norm": true,
|
| 21 |
+
"attention_output_gate": false,
|
| 22 |
+
"rope_theta": 5000000,
|
| 23 |
+
"rotary_dim": 64,
|
| 24 |
+
"partial_rotary_factor": 0.5,
|
| 25 |
+
"hidden_act": "swigluoai",
|
| 26 |
+
"use_qk_norm": true,
|
| 27 |
+
"tie_word_embeddings": false,
|
| 28 |
+
"dense_intermediate_size": 12288,
|
| 29 |
+
"shared_intermediate_size": 3072,
|
| 30 |
+
"num_local_experts": 128,
|
| 31 |
+
"num_experts_per_tok": 4,
|
| 32 |
+
"n_shared_experts": 1,
|
| 33 |
+
"scoring_func": "sigmoid",
|
| 34 |
+
"use_routing_bias": true,
|
| 35 |
+
"moe_layer_freq": [
|
| 36 |
+
0,
|
| 37 |
+
0,
|
| 38 |
+
0,
|
| 39 |
+
1,
|
| 40 |
+
1,
|
| 41 |
+
1,
|
| 42 |
+
1,
|
| 43 |
+
1,
|
| 44 |
+
1,
|
| 45 |
+
1,
|
| 46 |
+
1,
|
| 47 |
+
1,
|
| 48 |
+
1,
|
| 49 |
+
1,
|
| 50 |
+
1,
|
| 51 |
+
1,
|
| 52 |
+
1,
|
| 53 |
+
1,
|
| 54 |
+
1,
|
| 55 |
+
1,
|
| 56 |
+
1,
|
| 57 |
+
1,
|
| 58 |
+
1,
|
| 59 |
+
1,
|
| 60 |
+
1,
|
| 61 |
+
1,
|
| 62 |
+
1,
|
| 63 |
+
1,
|
| 64 |
+
1,
|
| 65 |
+
1,
|
| 66 |
+
1,
|
| 67 |
+
1,
|
| 68 |
+
1,
|
| 69 |
+
1,
|
| 70 |
+
1,
|
| 71 |
+
1,
|
| 72 |
+
1,
|
| 73 |
+
1,
|
| 74 |
+
1,
|
| 75 |
+
1,
|
| 76 |
+
1,
|
| 77 |
+
1,
|
| 78 |
+
1,
|
| 79 |
+
1,
|
| 80 |
+
1,
|
| 81 |
+
1,
|
| 82 |
+
1,
|
| 83 |
+
1,
|
| 84 |
+
1,
|
| 85 |
+
1,
|
| 86 |
+
1,
|
| 87 |
+
1,
|
| 88 |
+
1,
|
| 89 |
+
1,
|
| 90 |
+
1,
|
| 91 |
+
1,
|
| 92 |
+
1,
|
| 93 |
+
1,
|
| 94 |
+
1,
|
| 95 |
+
1
|
| 96 |
+
],
|
| 97 |
+
"qk_norm_type": "per_head",
|
| 98 |
+
"num_mtp_modules": 1,
|
| 99 |
+
"swiglu_alpha": 1.702,
|
| 100 |
+
"swiglu_limit": 7.0,
|
| 101 |
+
"routed_scaling_factor": 2.0,
|
| 102 |
+
"sparse_attention_config": {
|
| 103 |
+
"use_sparse_attention": true,
|
| 104 |
+
"sparse_index_dim": 128,
|
| 105 |
+
"sparse_num_index_heads": 4,
|
| 106 |
+
"sparse_topk_blocks": 16,
|
| 107 |
+
"sparse_block_size": 128,
|
| 108 |
+
"sparse_disable_index_value": [
|
| 109 |
+
0,
|
| 110 |
+
0,
|
| 111 |
+
0,
|
| 112 |
+
1,
|
| 113 |
+
1,
|
| 114 |
+
1,
|
| 115 |
+
1,
|
| 116 |
+
1,
|
| 117 |
+
1,
|
| 118 |
+
1,
|
| 119 |
+
1,
|
| 120 |
+
1,
|
| 121 |
+
1,
|
| 122 |
+
1,
|
| 123 |
+
1,
|
| 124 |
+
1,
|
| 125 |
+
1,
|
| 126 |
+
1,
|
| 127 |
+
1,
|
| 128 |
+
1,
|
| 129 |
+
1,
|
| 130 |
+
1,
|
| 131 |
+
1,
|
| 132 |
+
1,
|
| 133 |
+
1,
|
| 134 |
+
1,
|
| 135 |
+
1,
|
| 136 |
+
1,
|
| 137 |
+
1,
|
| 138 |
+
1,
|
| 139 |
+
1,
|
| 140 |
+
1,
|
| 141 |
+
1,
|
| 142 |
+
1,
|
| 143 |
+
1,
|
| 144 |
+
1,
|
| 145 |
+
1,
|
| 146 |
+
1,
|
| 147 |
+
1,
|
| 148 |
+
1,
|
| 149 |
+
1,
|
| 150 |
+
1,
|
| 151 |
+
1,
|
| 152 |
+
1,
|
| 153 |
+
1,
|
| 154 |
+
1,
|
| 155 |
+
1,
|
| 156 |
+
1,
|
| 157 |
+
1,
|
| 158 |
+
1,
|
| 159 |
+
1,
|
| 160 |
+
1,
|
| 161 |
+
1,
|
| 162 |
+
1,
|
| 163 |
+
1,
|
| 164 |
+
1,
|
| 165 |
+
1,
|
| 166 |
+
1,
|
| 167 |
+
1,
|
| 168 |
+
1
|
| 169 |
+
],
|
| 170 |
+
"sparse_score_type": "max",
|
| 171 |
+
"sparse_init_block": 0,
|
| 172 |
+
"sparse_local_block": 1,
|
| 173 |
+
"sparse_attention_freq": [
|
| 174 |
+
0,
|
| 175 |
+
0,
|
| 176 |
+
0,
|
| 177 |
+
1,
|
| 178 |
+
1,
|
| 179 |
+
1,
|
| 180 |
+
1,
|
| 181 |
+
1,
|
| 182 |
+
1,
|
| 183 |
+
1,
|
| 184 |
+
1,
|
| 185 |
+
1,
|
| 186 |
+
1,
|
| 187 |
+
1,
|
| 188 |
+
1,
|
| 189 |
+
1,
|
| 190 |
+
1,
|
| 191 |
+
1,
|
| 192 |
+
1,
|
| 193 |
+
1,
|
| 194 |
+
1,
|
| 195 |
+
1,
|
| 196 |
+
1,
|
| 197 |
+
1,
|
| 198 |
+
1,
|
| 199 |
+
1,
|
| 200 |
+
1,
|
| 201 |
+
1,
|
| 202 |
+
1,
|
| 203 |
+
1,
|
| 204 |
+
1,
|
| 205 |
+
1,
|
| 206 |
+
1,
|
| 207 |
+
1,
|
| 208 |
+
1,
|
| 209 |
+
1,
|
| 210 |
+
1,
|
| 211 |
+
1,
|
| 212 |
+
1,
|
| 213 |
+
1,
|
| 214 |
+
1,
|
| 215 |
+
1,
|
| 216 |
+
1,
|
| 217 |
+
1,
|
| 218 |
+
1,
|
| 219 |
+
1,
|
| 220 |
+
1,
|
| 221 |
+
1,
|
| 222 |
+
1,
|
| 223 |
+
1,
|
| 224 |
+
1,
|
| 225 |
+
1,
|
| 226 |
+
1,
|
| 227 |
+
1,
|
| 228 |
+
1,
|
| 229 |
+
1,
|
| 230 |
+
1,
|
| 231 |
+
1,
|
| 232 |
+
1,
|
| 233 |
+
1
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
"architectures": [
|
| 237 |
+
"MiniMaxM3SparseForCausalLM"
|
| 238 |
+
]
|
| 239 |
+
},
|
| 240 |
+
"vision_config": {
|
| 241 |
+
"hidden_size": 1280,
|
| 242 |
+
"num_attention_heads": 16,
|
| 243 |
+
"num_hidden_layers": 32,
|
| 244 |
+
"intermediate_size": 5120,
|
| 245 |
+
"patch_size": 14,
|
| 246 |
+
"image_size": 2016,
|
| 247 |
+
"projection_dim": 6144,
|
| 248 |
+
"position_embedding_type": "rope",
|
| 249 |
+
"rope_mode": "3d",
|
| 250 |
+
"rope_theta": 10000.0,
|
| 251 |
+
"attention_dropout": 0.0,
|
| 252 |
+
"hidden_act": "gelu",
|
| 253 |
+
"initializer_factor": 1.0,
|
| 254 |
+
"initializer_range": 0.02,
|
| 255 |
+
"layer_norm_eps": 1e-05,
|
| 256 |
+
"model_type": "clip_vision_model",
|
| 257 |
+
"num_channels": 3,
|
| 258 |
+
"vocab_size": 32000,
|
| 259 |
+
"img_token_compression_config": {
|
| 260 |
+
"image_token_compression_method": "patch_merge",
|
| 261 |
+
"spatial_merge_size": 2,
|
| 262 |
+
"temporal_patch_size": 2
|
| 263 |
+
},
|
| 264 |
+
"vision_segment_max_frames": 4
|
| 265 |
+
},
|
| 266 |
+
"img_token_compression_config": {
|
| 267 |
+
"image_token_compression_method": "patch_merge",
|
| 268 |
+
"spatial_merge_size": 2,
|
| 269 |
+
"temporal_patch_size": 2
|
| 270 |
+
},
|
| 271 |
+
"image_grid_pinpoints": "[(336, 336), (336, 672), (336, 1008), (336, 1344), (336, 1680), (336, 2016), (672, 336), (672, 672), (672, 1008), (672, 1344), (672, 1680), (672, 2016), (1008, 336), (1008, 672), (1008, 1008), (1008, 1344), (1008, 1680), (1008, 2016), (1344, 336), (1344, 672), (1344, 1008), (1344, 1344), (1344, 1680), (1344, 2016), (1680, 336), (1680, 672), (1680, 1008), (1680, 1344), (1680, 1680), (1680, 2016), (2016, 336), (2016, 672), (2016, 1008), (2016, 1344), (2016, 1680), (2016, 2016)]",
|
| 272 |
+
"image_seq_length": 576,
|
| 273 |
+
"image_token_index": 200025,
|
| 274 |
+
"video_token_index": 200026,
|
| 275 |
+
"multimodal_projector_bias": true,
|
| 276 |
+
"num_reward_heads": 0,
|
| 277 |
+
"process_image_mode": "dynamic_res",
|
| 278 |
+
"projector_hidden_act": "gelu",
|
| 279 |
+
"vision_feature_layer": -1,
|
| 280 |
+
"vision_feature_select_strategy": "full",
|
| 281 |
+
"torch_dtype": "bfloat16",
|
| 282 |
+
"transformers_version": "4.52.4",
|
| 283 |
+
"projector_hidden_size": 6144,
|
| 284 |
+
"quantization_config": {
|
| 285 |
+
"quant_method": "mxfp8",
|
| 286 |
+
"activation_scheme": "dynamic",
|
| 287 |
+
"weight_block_size": [
|
| 288 |
+
1,
|
| 289 |
+
32
|
| 290 |
+
],
|
| 291 |
+
"ignored_layers": [
|
| 292 |
+
"lm_head",
|
| 293 |
+
"model.embed_tokens",
|
| 294 |
+
"vision_tower",
|
| 295 |
+
"multi_modal_projector",
|
| 296 |
+
"patch_merge_mlp",
|
| 297 |
+
"language_model.model.layers.10.block_sparse_moe.gate",
|
| 298 |
+
"language_model.model.layers.11.block_sparse_moe.gate",
|
| 299 |
+
"language_model.model.layers.12.block_sparse_moe.gate",
|
| 300 |
+
"language_model.model.layers.13.block_sparse_moe.gate",
|
| 301 |
+
"language_model.model.layers.14.block_sparse_moe.gate",
|
| 302 |
+
"language_model.model.layers.15.block_sparse_moe.gate",
|
| 303 |
+
"language_model.model.layers.16.block_sparse_moe.gate",
|
| 304 |
+
"language_model.model.layers.17.block_sparse_moe.gate",
|
| 305 |
+
"language_model.model.layers.18.block_sparse_moe.gate",
|
| 306 |
+
"language_model.model.layers.19.block_sparse_moe.gate",
|
| 307 |
+
"language_model.model.layers.20.block_sparse_moe.gate",
|
| 308 |
+
"language_model.model.layers.21.block_sparse_moe.gate",
|
| 309 |
+
"language_model.model.layers.22.block_sparse_moe.gate",
|
| 310 |
+
"language_model.model.layers.23.block_sparse_moe.gate",
|
| 311 |
+
"language_model.model.layers.24.block_sparse_moe.gate",
|
| 312 |
+
"language_model.model.layers.25.block_sparse_moe.gate",
|
| 313 |
+
"language_model.model.layers.26.block_sparse_moe.gate",
|
| 314 |
+
"language_model.model.layers.27.block_sparse_moe.gate",
|
| 315 |
+
"language_model.model.layers.28.block_sparse_moe.gate",
|
| 316 |
+
"language_model.model.layers.29.block_sparse_moe.gate",
|
| 317 |
+
"language_model.model.layers.3.block_sparse_moe.gate",
|
| 318 |
+
"language_model.model.layers.30.block_sparse_moe.gate",
|
| 319 |
+
"language_model.model.layers.31.block_sparse_moe.gate",
|
| 320 |
+
"language_model.model.layers.32.block_sparse_moe.gate",
|
| 321 |
+
"language_model.model.layers.33.block_sparse_moe.gate",
|
| 322 |
+
"language_model.model.layers.34.block_sparse_moe.gate",
|
| 323 |
+
"language_model.model.layers.35.block_sparse_moe.gate",
|
| 324 |
+
"language_model.model.layers.36.block_sparse_moe.gate",
|
| 325 |
+
"language_model.model.layers.37.block_sparse_moe.gate",
|
| 326 |
+
"language_model.model.layers.38.block_sparse_moe.gate",
|
| 327 |
+
"language_model.model.layers.39.block_sparse_moe.gate",
|
| 328 |
+
"language_model.model.layers.4.block_sparse_moe.gate",
|
| 329 |
+
"language_model.model.layers.40.block_sparse_moe.gate",
|
| 330 |
+
"language_model.model.layers.41.block_sparse_moe.gate",
|
| 331 |
+
"language_model.model.layers.42.block_sparse_moe.gate",
|
| 332 |
+
"language_model.model.layers.43.block_sparse_moe.gate",
|
| 333 |
+
"language_model.model.layers.44.block_sparse_moe.gate",
|
| 334 |
+
"language_model.model.layers.45.block_sparse_moe.gate",
|
| 335 |
+
"language_model.model.layers.46.block_sparse_moe.gate",
|
| 336 |
+
"language_model.model.layers.47.block_sparse_moe.gate",
|
| 337 |
+
"language_model.model.layers.48.block_sparse_moe.gate",
|
| 338 |
+
"language_model.model.layers.49.block_sparse_moe.gate",
|
| 339 |
+
"language_model.model.layers.5.block_sparse_moe.gate",
|
| 340 |
+
"language_model.model.layers.50.block_sparse_moe.gate",
|
| 341 |
+
"language_model.model.layers.51.block_sparse_moe.gate",
|
| 342 |
+
"language_model.model.layers.52.block_sparse_moe.gate",
|
| 343 |
+
"language_model.model.layers.53.block_sparse_moe.gate",
|
| 344 |
+
"language_model.model.layers.54.block_sparse_moe.gate",
|
| 345 |
+
"language_model.model.layers.55.block_sparse_moe.gate",
|
| 346 |
+
"language_model.model.layers.56.block_sparse_moe.gate",
|
| 347 |
+
"language_model.model.layers.57.block_sparse_moe.gate",
|
| 348 |
+
"language_model.model.layers.58.block_sparse_moe.gate",
|
| 349 |
+
"language_model.model.layers.59.block_sparse_moe.gate",
|
| 350 |
+
"language_model.model.layers.6.block_sparse_moe.gate",
|
| 351 |
+
"language_model.model.layers.7.block_sparse_moe.gate",
|
| 352 |
+
"language_model.model.layers.8.block_sparse_moe.gate",
|
| 353 |
+
"language_model.model.layers.9.block_sparse_moe.gate"
|
| 354 |
+
]
|
| 355 |
+
}
|
| 356 |
+
}
|
configuration_minimax_m3_vl.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""HuggingFace configs for the MiniMax VL family (M2 VL / M3 VL).
|
| 2 |
+
|
| 3 |
+
This file is bundled into every converted HF checkpoint so that loading via
|
| 4 |
+
``AutoConfig.from_pretrained(..., trust_remote_code=True)`` works without any
|
| 5 |
+
runtime dependency on sglang or other internal packages — only stock
|
| 6 |
+
``transformers`` is required.
|
| 7 |
+
|
| 8 |
+
The class definitions intentionally mirror
|
| 9 |
+
``sglang.srt.configs.minimax_vl``; if either side changes, keep them in sync.
|
| 10 |
+
|
| 11 |
+
The file is named ``configuration_minimax_m3_vl.py`` (matching the legacy
|
| 12 |
+
``model_type="minimax_m3_vl"`` and the converter's ``auto_map`` entry) so
|
| 13 |
+
that ckpts produced by this converter remain loadable by older sglang versions
|
| 14 |
+
that only know the ``MiniMaxM3VL*`` names. The canonical class is
|
| 15 |
+
``MiniMaxM3VLConfig``; ``MiniMaxM3VLConfig`` is a thin BC alias whose only
|
| 16 |
+
purpose is to be referenced from ``auto_map``.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import Optional
|
| 20 |
+
|
| 21 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 22 |
+
from transformers.models.auto import CONFIG_MAPPING
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def _coerce_sub_config(
|
| 26 |
+
sub_config: Optional[dict], default_model_type: str
|
| 27 |
+
) -> Optional[PretrainedConfig]:
|
| 28 |
+
"""Convert a config dict to a ``PretrainedConfig`` instance.
|
| 29 |
+
|
| 30 |
+
If ``model_type`` is registered in HF ``CONFIG_MAPPING`` the corresponding
|
| 31 |
+
config class is used; otherwise we fall back to a generic
|
| 32 |
+
``PretrainedConfig`` so all dict keys still become real attributes (M3's
|
| 33 |
+
text backbone uses ``model_type="minimax_m2"`` which is not in
|
| 34 |
+
``CONFIG_MAPPING``).
|
| 35 |
+
"""
|
| 36 |
+
if not isinstance(sub_config, dict):
|
| 37 |
+
return sub_config
|
| 38 |
+
model_type = sub_config.get("model_type", default_model_type)
|
| 39 |
+
cls = CONFIG_MAPPING.get(model_type, PretrainedConfig)
|
| 40 |
+
return cls(**sub_config)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class MiniMaxVLBaseConfig(PretrainedConfig):
|
| 44 |
+
"""Base config shared by every MiniMax VL variant.
|
| 45 |
+
|
| 46 |
+
Handles vision/text sub-config coercion. Concrete subclasses only need to
|
| 47 |
+
declare a unique ``model_type`` string.
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
def __init__(
|
| 51 |
+
self,
|
| 52 |
+
vision_config: Optional[dict] = None,
|
| 53 |
+
text_config: Optional[dict] = None,
|
| 54 |
+
image_token_index: int = 200025,
|
| 55 |
+
video_token_index: int = 200026,
|
| 56 |
+
image_seq_length: int = 576,
|
| 57 |
+
process_image_mode: str = "dynamic_res",
|
| 58 |
+
projector_hidden_act: str = "gelu",
|
| 59 |
+
multimodal_projector_bias: bool = True,
|
| 60 |
+
vision_feature_layer: int = -1,
|
| 61 |
+
vision_feature_select_strategy: str = "full",
|
| 62 |
+
img_token_compression_config: Optional[dict] = None,
|
| 63 |
+
image_grid_pinpoints: Optional[str] = None,
|
| 64 |
+
**kwargs,
|
| 65 |
+
):
|
| 66 |
+
self.vision_config = _coerce_sub_config(vision_config, "clip_vision_model")
|
| 67 |
+
self.text_config = _coerce_sub_config(text_config, "mixtral")
|
| 68 |
+
|
| 69 |
+
self.image_token_index = image_token_index
|
| 70 |
+
self.video_token_index = video_token_index
|
| 71 |
+
self.image_seq_length = image_seq_length
|
| 72 |
+
self.process_image_mode = process_image_mode
|
| 73 |
+
self.projector_hidden_act = projector_hidden_act
|
| 74 |
+
self.multimodal_projector_bias = multimodal_projector_bias
|
| 75 |
+
self.vision_feature_layer = vision_feature_layer
|
| 76 |
+
self.vision_feature_select_strategy = vision_feature_select_strategy
|
| 77 |
+
self.img_token_compression_config = img_token_compression_config or {}
|
| 78 |
+
self.image_grid_pinpoints = image_grid_pinpoints
|
| 79 |
+
|
| 80 |
+
super().__init__(**kwargs)
|
| 81 |
+
|
| 82 |
+
def __post_init__(self, **kwargs):
|
| 83 |
+
super().__post_init__(**kwargs)
|
| 84 |
+
if hasattr(self, "vision_config"):
|
| 85 |
+
self.vision_config = _coerce_sub_config(self.vision_config, "clip_vision_model")
|
| 86 |
+
if hasattr(self, "text_config"):
|
| 87 |
+
self.text_config = _coerce_sub_config(self.text_config, "mixtral")
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class MiniMaxM2VLConfig(MiniMaxVLBaseConfig):
|
| 91 |
+
"""MiniMax M2 VL: vision tower + M2 (Mixtral-style MoE) text backbone."""
|
| 92 |
+
|
| 93 |
+
model_type = "minimax_m2_vl"
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class MiniMaxM3VLConfig(MiniMaxVLBaseConfig):
|
| 97 |
+
"""MiniMax M3 VL: vision tower + M3 (mixed sparse/dense MoE) text backbone."""
|
| 98 |
+
|
| 99 |
+
model_type = "minimax_m3_vl"
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class MiniMaxM2MiniVLConfig(MiniMaxM2VLConfig):
|
| 103 |
+
"""Legacy alias kept so old ``model_type="minimax_m2_mini_vl"`` ckpts load."""
|
| 104 |
+
|
| 105 |
+
model_type = "minimax_m2_mini_vl"
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class MiniMaxM3VLConfig(MiniMaxM3VLConfig):
|
| 109 |
+
"""Legacy alias kept so old ``model_type="minimax_m3_vl"`` ckpts load."""
|
| 110 |
+
|
| 111 |
+
model_type = "minimax_m3_vl"
|
figures/benchmark.jpeg
ADDED

|
Git LFS Details
|
figures/efficiency_gqa_vs_msa.png
ADDED
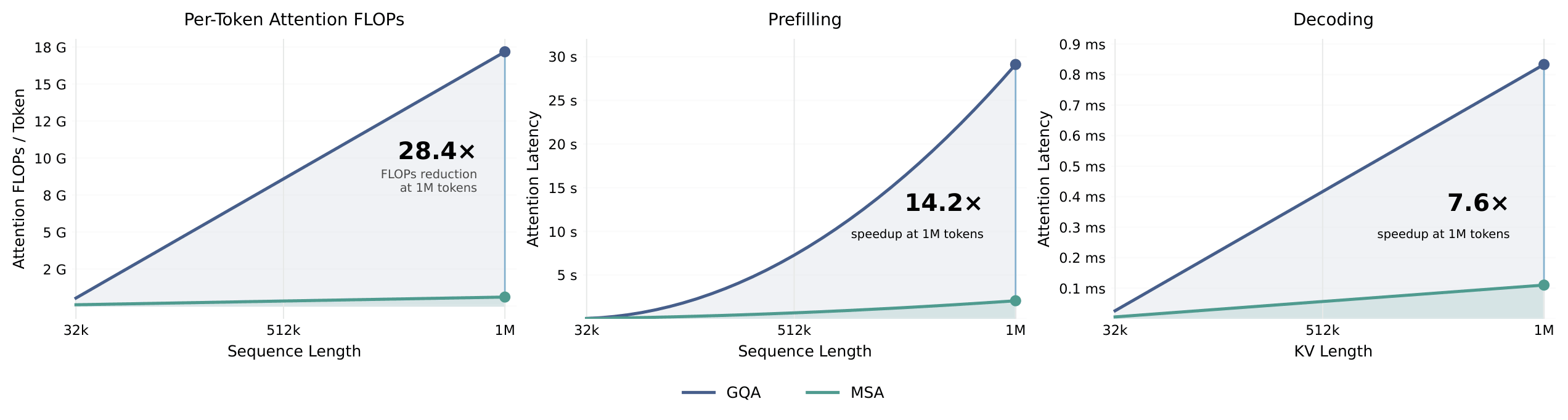
|
figures/logo.svg
ADDED
|
|
generation_config.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 200019,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": 200020,
|
| 5 |
+
"temperature": 1.0,
|
| 6 |
+
"top_p": 0.95,
|
| 7 |
+
"transformers_version": "4.46.1"
|
| 8 |
+
}
|
image_processor.py
ADDED
|
@@ -0,0 +1,223 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023-2024 SGLang Team
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
"""
|
| 4 |
+
MiniMax VL family HuggingFace-compatible Processor, ImageProcessor, VideoProcessor.
|
| 5 |
+
"""
|
| 6 |
+
import math
|
| 7 |
+
from typing import List, Tuple
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torchvision.transforms import InterpolationMode
|
| 11 |
+
from transformers import BatchFeature
|
| 12 |
+
from transformers.image_processing_utils_fast import (
|
| 13 |
+
BaseImageProcessorFast,
|
| 14 |
+
group_images_by_shape,
|
| 15 |
+
reorder_images,
|
| 16 |
+
)
|
| 17 |
+
from transformers.image_utils import PILImageResampling, SizeDict
|
| 18 |
+
from transformers.processing_utils import (
|
| 19 |
+
ImagesKwargs,
|
| 20 |
+
Unpack,
|
| 21 |
+
)
|
| 22 |
+
from transformers.utils import TensorType
|
| 23 |
+
|
| 24 |
+
MAX_RATIO = 200
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def round_by_factor(number: int, factor: int) -> int:
|
| 28 |
+
return round(number / factor) * factor
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def ceil_by_factor(number: int, factor: int) -> int:
|
| 32 |
+
return math.ceil(number / factor) * factor
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def floor_by_factor(number: int, factor: int) -> int:
|
| 36 |
+
return math.floor(number / factor) * factor
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def smart_resize(
|
| 40 |
+
height: int,
|
| 41 |
+
width: int,
|
| 42 |
+
factor: int = 28,
|
| 43 |
+
min_pixels: int = 4 * 28 * 28,
|
| 44 |
+
max_pixels: int = 451584,
|
| 45 |
+
) -> tuple[int, int]:
|
| 46 |
+
if max(height, width) / min(height, width) > MAX_RATIO:
|
| 47 |
+
raise ValueError(
|
| 48 |
+
f"absolute aspect ratio must be smaller than {MAX_RATIO}, "
|
| 49 |
+
f"got {max(height, width) / min(height, width)}"
|
| 50 |
+
)
|
| 51 |
+
h_bar = max(factor, round_by_factor(height, factor))
|
| 52 |
+
w_bar = max(factor, round_by_factor(width, factor))
|
| 53 |
+
if h_bar * w_bar > max_pixels:
|
| 54 |
+
beta = math.sqrt((height * width) / max_pixels)
|
| 55 |
+
h_bar = floor_by_factor(height / beta, factor)
|
| 56 |
+
w_bar = floor_by_factor(width / beta, factor)
|
| 57 |
+
elif h_bar * w_bar < min_pixels:
|
| 58 |
+
beta = math.sqrt(min_pixels / (height * width))
|
| 59 |
+
h_bar = ceil_by_factor(height * beta, factor)
|
| 60 |
+
w_bar = ceil_by_factor(width * beta, factor)
|
| 61 |
+
return h_bar, w_bar
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# ==============================================================================
|
| 65 |
+
# MiniMax M3 VL Image Processor Fast (Fast Mode - Torch based)
|
| 66 |
+
# ==============================================================================
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class MiniMaxM3VLImageProcessorKwargs(ImagesKwargs, total=False):
|
| 70 |
+
patch_size: int
|
| 71 |
+
temporal_patch_size: int
|
| 72 |
+
merge_size: int
|
| 73 |
+
max_pixels: int
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class MiniMaxM3VLImageProcessor(BaseImageProcessorFast):
|
| 77 |
+
do_resize = True
|
| 78 |
+
resample = PILImageResampling.BICUBIC
|
| 79 |
+
size = {"height": 672, "width": 672} # required by base class validation, not used as resize bound
|
| 80 |
+
default_to_square = False
|
| 81 |
+
do_rescale = True
|
| 82 |
+
rescale_factor = 1 / 255
|
| 83 |
+
do_normalize = True
|
| 84 |
+
image_mean = [0.48145466, 0.4578275, 0.40821073]
|
| 85 |
+
image_std = [0.26862954, 0.26130258, 0.27577711]
|
| 86 |
+
do_convert_rgb = True
|
| 87 |
+
patch_size = 14
|
| 88 |
+
temporal_patch_size = 2
|
| 89 |
+
merge_size = 2
|
| 90 |
+
max_pixels = 451584 # 672*672
|
| 91 |
+
valid_kwargs = MiniMaxM3VLImageProcessorKwargs
|
| 92 |
+
model_input_names = ["pixel_values", "image_grid_thw"]
|
| 93 |
+
|
| 94 |
+
def __init__(self, **kwargs: Unpack[MiniMaxM3VLImageProcessorKwargs]):
|
| 95 |
+
super().__init__(**kwargs)
|
| 96 |
+
|
| 97 |
+
def preprocess(
|
| 98 |
+
self, images, **kwargs: Unpack[MiniMaxM3VLImageProcessorKwargs]
|
| 99 |
+
) -> BatchFeature:
|
| 100 |
+
return super().preprocess(images, **kwargs)
|
| 101 |
+
|
| 102 |
+
def _preprocess(
|
| 103 |
+
self,
|
| 104 |
+
images: List[torch.Tensor],
|
| 105 |
+
do_resize: bool,
|
| 106 |
+
size: SizeDict,
|
| 107 |
+
resample: PILImageResampling | InterpolationMode | int | None,
|
| 108 |
+
do_rescale: bool,
|
| 109 |
+
rescale_factor: float,
|
| 110 |
+
do_normalize: bool,
|
| 111 |
+
image_mean: float | List[float] | None,
|
| 112 |
+
image_std: float | List[float] | None,
|
| 113 |
+
patch_size: int,
|
| 114 |
+
temporal_patch_size: int,
|
| 115 |
+
merge_size: int,
|
| 116 |
+
max_pixels: int,
|
| 117 |
+
disable_grouping: bool | None,
|
| 118 |
+
return_tensors: str | TensorType | None,
|
| 119 |
+
**kwargs,
|
| 120 |
+
) -> BatchFeature:
|
| 121 |
+
grouped_images, grouped_images_index = group_images_by_shape(
|
| 122 |
+
images, disable_grouping=disable_grouping
|
| 123 |
+
)
|
| 124 |
+
resized_images_grouped = {}
|
| 125 |
+
factor = patch_size * merge_size
|
| 126 |
+
for shape, stacked_images in grouped_images.items():
|
| 127 |
+
height, width = stacked_images.shape[-2:]
|
| 128 |
+
if do_resize:
|
| 129 |
+
resized_height, resized_width = smart_resize(
|
| 130 |
+
height, width, factor=factor,
|
| 131 |
+
max_pixels=max_pixels,
|
| 132 |
+
)
|
| 133 |
+
stacked_images = self.resize(
|
| 134 |
+
stacked_images,
|
| 135 |
+
size=SizeDict(height=resized_height, width=resized_width),
|
| 136 |
+
resample=resample,
|
| 137 |
+
)
|
| 138 |
+
resized_images_grouped[shape] = stacked_images
|
| 139 |
+
|
| 140 |
+
resized_images = reorder_images(resized_images_grouped, grouped_images_index)
|
| 141 |
+
|
| 142 |
+
grouped_images, grouped_images_index = group_images_by_shape(
|
| 143 |
+
resized_images, disable_grouping=disable_grouping
|
| 144 |
+
)
|
| 145 |
+
processed_images_grouped = {}
|
| 146 |
+
processed_grids = {}
|
| 147 |
+
|
| 148 |
+
for shape, stacked_images in grouped_images.items():
|
| 149 |
+
resized_height, resized_width = stacked_images.shape[-2:]
|
| 150 |
+
|
| 151 |
+
patches = self.rescale_and_normalize(
|
| 152 |
+
stacked_images,
|
| 153 |
+
do_rescale,
|
| 154 |
+
rescale_factor,
|
| 155 |
+
do_normalize,
|
| 156 |
+
image_mean,
|
| 157 |
+
image_std,
|
| 158 |
+
)
|
| 159 |
+
if patches.ndim == 4:
|
| 160 |
+
patches = patches.unsqueeze(1)
|
| 161 |
+
|
| 162 |
+
if patches.shape[1] % temporal_patch_size != 0:
|
| 163 |
+
repeats = patches[:, -1:].repeat(
|
| 164 |
+
1,
|
| 165 |
+
temporal_patch_size - (patches.shape[1] % temporal_patch_size),
|
| 166 |
+
1,
|
| 167 |
+
1,
|
| 168 |
+
1,
|
| 169 |
+
)
|
| 170 |
+
patches = torch.cat([patches, repeats], dim=1)
|
| 171 |
+
|
| 172 |
+
batch_size, grid_t, channel = patches.shape[:3]
|
| 173 |
+
grid_t = grid_t // temporal_patch_size
|
| 174 |
+
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
|
| 175 |
+
|
| 176 |
+
patches = patches.view(
|
| 177 |
+
batch_size,
|
| 178 |
+
grid_t,
|
| 179 |
+
temporal_patch_size,
|
| 180 |
+
channel,
|
| 181 |
+
grid_h // merge_size,
|
| 182 |
+
merge_size,
|
| 183 |
+
patch_size,
|
| 184 |
+
grid_w // merge_size,
|
| 185 |
+
merge_size,
|
| 186 |
+
patch_size,
|
| 187 |
+
)
|
| 188 |
+
patches = patches.permute(0, 1, 4, 7, 5, 8, 3, 2, 6, 9)
|
| 189 |
+
|
| 190 |
+
flatten_patches = patches.reshape(
|
| 191 |
+
batch_size,
|
| 192 |
+
grid_t * grid_h * grid_w,
|
| 193 |
+
channel * temporal_patch_size * patch_size * patch_size,
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
processed_images_grouped[shape] = flatten_patches
|
| 197 |
+
processed_grids[shape] = [[grid_t, grid_h, grid_w]] * batch_size
|
| 198 |
+
|
| 199 |
+
processed_images = reorder_images(
|
| 200 |
+
processed_images_grouped, grouped_images_index
|
| 201 |
+
)
|
| 202 |
+
processed_grids = reorder_images(processed_grids, grouped_images_index)
|
| 203 |
+
|
| 204 |
+
pixel_values = torch.cat(processed_images, dim=0)
|
| 205 |
+
image_grid_thw = torch.tensor(processed_grids, dtype=torch.long)
|
| 206 |
+
|
| 207 |
+
return BatchFeature(
|
| 208 |
+
data={"pixel_values": pixel_values, "image_grid_thw": image_grid_thw},
|
| 209 |
+
tensor_type=return_tensors,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
def get_number_of_image_patches(self, height: int, width: int, images_kwargs=None):
|
| 213 |
+
images_kwargs = images_kwargs or {}
|
| 214 |
+
patch_size = images_kwargs.get("patch_size", self.patch_size)
|
| 215 |
+
merge_size = images_kwargs.get("merge_size", self.merge_size)
|
| 216 |
+
max_pixels = images_kwargs.get("max_pixels", self.max_pixels)
|
| 217 |
+
|
| 218 |
+
resized_height, resized_width = smart_resize(
|
| 219 |
+
height, width, factor=patch_size * merge_size,
|
| 220 |
+
max_pixels=max_pixels,
|
| 221 |
+
)
|
| 222 |
+
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
|
| 223 |
+
return grid_h * grid_w
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:989c678e6df4e9a8587e1ac2b7eea6705d439864e9466952766dc074ffc3a852
|
| 3 |
+
size 8303674712
|
model-00002-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d322e81689aac0c78844b8b02563fa8e5caf390712564309d2394de7a1a5e66c
|
| 3 |
+
size 16098618792
|
model-00003-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f95a025468296d895c7bf140dec15e6b1ed19123bcd2b200783f1411cde032a7
|
| 3 |
+
size 16098618872
|
model-00004-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e314deac313a4982ad550495d39d3e5c69cee5801f147e9bf8e598f186fddb4
|
| 3 |
+
size 16098619208
|
model-00005-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dcf591bdbd30aad81b68d805cacc27da765b56da9d120e22c9db4143e3883bae
|
| 3 |
+
size 16098619672
|
model-00006-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f78bcc3b7a01df84d5937373255078d47ecad71a35139ed83db69266e0d1503
|
| 3 |
+
size 16098619128
|
model-00007-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2565c3f341c0500871075b9aff5120148aeef975a213356467982d20782372c4
|
| 3 |
+
size 16098619848
|
model-00008-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec933f1c62df1e58d01caf0799c3ea95890ff92be49b416196d6f1da22fee73a
|
| 3 |
+
size 16098619768
|
model-00009-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7b9c09bec8c9b5a5b04a275bfe7611e5a5ddaf1840ef5f1afac3bf03b53d0d00
|
| 3 |
+
size 16098619848
|
model-00010-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a11d745ba9b720208903ff702b7e2242270768b2e142ea5d6836461c5ff2fb2e
|
| 3 |
+
size 16098619800
|
model-00011-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a29f8db47eab1c696944a52e19baabf889671ab6d65c0984c000804fd87cc762
|
| 3 |
+
size 16098619800
|
model-00012-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:86ba996a026126a4511f15d97b388b7e165b0a5fb62e298661d90bc44b49bc81
|
| 3 |
+
size 16098619768
|
model-00013-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:59b7686d653c0cfd71422893b9257e0e0adc3086c908a5e4494bb9ef84f4a15b
|
| 3 |
+
size 16098619800
|
model-00014-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:72043c0985a67fdb7c616c45229d89a50565ec709125736a7d2934b659af471c
|
| 3 |
+
size 16098619768
|
model-00015-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7079291acf884db350919f076c79a803fbebd00d5bedf6f1109d5eb24636cab
|
| 3 |
+
size 16098619768
|
model-00016-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9621408065fe642f8a66463fb8b377270b941388974fb8686604b34ac42f732
|
| 3 |
+
size 16098619768
|
model-00017-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:810cbc1f23df7cf70951c1825b0d38278f6d0d1b2baff3d749251da2a9fb7245
|
| 3 |
+
size 16098619768
|
model-00018-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9259e7fb22e50e247d46e2be42bb21c3d217c008d5971a9e5ec69b65463a113a
|
| 3 |
+
size 16098619768
|
model-00019-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb981287715b905ea1549fe486800f00e93cc297419dd1b318452d80b8e966e3
|
| 3 |
+
size 16098619768
|
model-00020-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8b8476f1c8960c48ddb331f245907c1a156b0e028010d1c72554ec7112c7636b
|
| 3 |
+
size 16098619760
|
model-00021-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f3fe2b51ce92a857d228c82622a25a692b373452d59015ad2cf88802513809ea
|
| 3 |
+
size 16098619768
|
model-00022-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13d4bfc0bb381e5eb7a45e301086d5f30d958ece5f4eeb0a8aca8557fb73c827
|
| 3 |
+
size 16098619768
|
model-00023-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:866c0f29b5fc5736e93055fc3fc3b2b3038cc778ed4d468bc60e2a4150b686b6
|
| 3 |
+
size 16098619768
|
model-00024-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:139eb26aafd48036f975817cdf91589b03e40c4a55d95b3f1bc7bcb596a21ad3
|
| 3 |
+
size 16098619768
|
model-00025-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4ae53cd8750d06cd6dd740ad12f5500e13038ba33eeb80c1b5c1986f7cb1b4c6
|
| 3 |
+
size 16098619768
|
model-00026-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22acb94253850e683d9f913f283526efa41c2c12a78d829396fa0e5d6412e453
|
| 3 |
+
size 16098619768
|
model-00027-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5e05dbb0a5983471adca1e6c6a93ada4cb262c16f2ada0527015597868f211f
|
| 3 |
+
size 16098619768
|
model-00028-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e1f73b7b51d07c1ada5ac918cce5efe00113917c01c9244cd97d43618e28a24c
|
| 3 |
+
size 506815888
|
model-00029-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:176732fbd63cf7b3ae4308b58b52e02c04d1be16c5e0d090687ba6d114ee3b1b
|
| 3 |
+
size 12246524552
|
model-00030-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb938a5398f07f22e94eb0493aa6b0553af0ed7988885fd7579469ebd4d86e83
|
| 3 |
+
size 2063975528
|
model-00031-of-00031.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:61bda86ec2d769a254586184f36e4eff64f17730bbe2c72c7da0c0682db28f35
|
| 3 |
+
size 2063975528
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"processor_class": "MiniMaxVLProcessor",
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoImageProcessor": "image_processor.MiniMaxM3VLImageProcessor",
|
| 5 |
+
"AutoProcessor": "processing_minimax.MiniMaxVLProcessor",
|
| 6 |
+
"AutoVideoProcessor": "video_processor.MiniMaxM3VLVideoProcessor"
|
| 7 |
+
},
|
| 8 |
+
"process_image_mode": "dynamic_res",
|
| 9 |
+
"image_mean": [
|
| 10 |
+
0.48145466,
|
| 11 |
+
0.4578275,
|
| 12 |
+
0.40821073
|
| 13 |
+
],
|
| 14 |
+
"image_std": [
|
| 15 |
+
0.26862954,
|
| 16 |
+
0.26130258,
|
| 17 |
+
0.27577711
|
| 18 |
+
],
|
| 19 |
+
"size": [
|
| 20 |
+
672,
|
| 21 |
+
672
|
| 22 |
+
],
|
| 23 |
+
"patch_size": 14,
|
| 24 |
+
"img_token_compression_config": {
|
| 25 |
+
"image_token_compression_threshold": 1.1,
|
| 26 |
+
"image_token_compression_method": "patch_merge",
|
| 27 |
+
"max_image_resolution": 1008,
|
| 28 |
+
"spatial_merge_size": 2,
|
| 29 |
+
"temporal_patch_size": 2
|
| 30 |
+
},
|
| 31 |
+
"add_start_end_special_tokens": true
|
| 32 |
+
}
|
processing_minimax.py
ADDED
|
@@ -0,0 +1,254 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023-2024 SGLang Team
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
"""
|
| 4 |
+
MiniMax VL family HuggingFace-compatible Processor, ImageProcessor, VideoProcessor.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
import re
|
| 9 |
+
from typing import List, Optional, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torchvision
|
| 13 |
+
from torchvision.transforms import InterpolationMode
|
| 14 |
+
from transformers import BatchFeature
|
| 15 |
+
from transformers.image_processing_utils_fast import (
|
| 16 |
+
BaseImageProcessorFast,
|
| 17 |
+
group_images_by_shape,
|
| 18 |
+
reorder_images,
|
| 19 |
+
)
|
| 20 |
+
from transformers.image_utils import PILImageResampling, SizeDict
|
| 21 |
+
from transformers.processing_utils import (
|
| 22 |
+
ImagesKwargs,
|
| 23 |
+
ProcessingKwargs,
|
| 24 |
+
ProcessorMixin,
|
| 25 |
+
Unpack,
|
| 26 |
+
VideosKwargs,
|
| 27 |
+
)
|
| 28 |
+
from transformers.utils import TensorType
|
| 29 |
+
from transformers.video_processing_utils import BaseVideoProcessor
|
| 30 |
+
from transformers.video_utils import group_videos_by_shape, reorder_videos
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class MiniMaxVLProcessorKwargs(ProcessingKwargs, total=False):
|
| 34 |
+
_defaults = {
|
| 35 |
+
"videos_kwargs": {
|
| 36 |
+
"do_resize": False,
|
| 37 |
+
"return_metadata": True,
|
| 38 |
+
},
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class MiniMaxVLProcessor(ProcessorMixin):
|
| 43 |
+
IMAGE_TOKEN = "]<]image[>["
|
| 44 |
+
VIDEO_TOKEN = "]<]video[>["
|
| 45 |
+
VISION_START_TOKEN = "]<]start of image[>["
|
| 46 |
+
VISION_END_TOKEN = "]<]end of image[>["
|
| 47 |
+
|
| 48 |
+
def __init__(
|
| 49 |
+
self, image_processor=None, tokenizer=None, video_processor=None, **kwargs
|
| 50 |
+
):
|
| 51 |
+
self.image_token_id = tokenizer.convert_tokens_to_ids(self.IMAGE_TOKEN)
|
| 52 |
+
self.video_token_id = tokenizer.convert_tokens_to_ids(self.VIDEO_TOKEN)
|
| 53 |
+
super().__init__(image_processor, tokenizer, video_processor)
|
| 54 |
+
# Video expansion also uses image start/end tokens. Separate video
|
| 55 |
+
# start/end tokens exist in the tokenizer, but the original MiniMax
|
| 56 |
+
# serving path did not use them; keep that behavior for compatibility.
|
| 57 |
+
self.vision_start_token_id = tokenizer.convert_tokens_to_ids(
|
| 58 |
+
self.VISION_START_TOKEN
|
| 59 |
+
)
|
| 60 |
+
self.vision_end_token_id = tokenizer.convert_tokens_to_ids(
|
| 61 |
+
self.VISION_END_TOKEN
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
def _prune_video_tokens(
|
| 65 |
+
self,
|
| 66 |
+
input_text: str,
|
| 67 |
+
video_segments: List[int],
|
| 68 |
+
video_token: str,
|
| 69 |
+
) -> str:
|
| 70 |
+
"""
|
| 71 |
+
Prune video tokens by temporal_patch_size (e.g., 2:1).
|
| 72 |
+
|
| 73 |
+
Expects the prompt to carry exactly sum(video_segments) video
|
| 74 |
+
tokens — i.e. one token per *sampled* frame. Then drops token.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
input_text: prompt with N video_tokens per segment
|
| 78 |
+
video_segments: actual sampled frame count per video segment
|
| 79 |
+
video_token: the video token string, e.g. ']<]video[>['
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
Pruned input_text with ~N/temporal_patch_size tokens per segment.
|
| 83 |
+
"""
|
| 84 |
+
# If no videos or temporal_patch_size <= 1, no pruning needed
|
| 85 |
+
if not video_segments or self.video_processor.temporal_patch_size <= 1:
|
| 86 |
+
return input_text
|
| 87 |
+
|
| 88 |
+
# Split while keeping delimiters
|
| 89 |
+
special_tokens = [video_token] # , image_token]
|
| 90 |
+
pattern = "|".join(map(re.escape, special_tokens))
|
| 91 |
+
parts = re.split(f"({pattern})", input_text)
|
| 92 |
+
|
| 93 |
+
def is_timestamp(text: str) -> bool:
|
| 94 |
+
"""Check if text ends with timestamp format like ']<]0.0 seconds[>['"""
|
| 95 |
+
return (
|
| 96 |
+
text.endswith("seconds[>[")
|
| 97 |
+
or text.endswith("seconds[>[ ")
|
| 98 |
+
or text.endswith("seconds [>[")
|
| 99 |
+
or text.endswith("seconds [>[ ")
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
def extract_timestamp(text: str) -> str:
|
| 103 |
+
"""Extract timestamp text from the end, starting from ']<]'"""
|
| 104 |
+
start_index = text.rfind("]<]")
|
| 105 |
+
if start_index == -1:
|
| 106 |
+
raise ValueError(f"Failed to extract timestamp: {text}")
|
| 107 |
+
return text[start_index:]
|
| 108 |
+
|
| 109 |
+
# Build new text with pruned video tokens
|
| 110 |
+
final_parts = []
|
| 111 |
+
current_seg_idx = 0 # Which video segment we're in
|
| 112 |
+
frame_in_seg = 0 # Frame index within current segment
|
| 113 |
+
last_timestamp_len = 0 # Length of timestamp to potentially remove
|
| 114 |
+
|
| 115 |
+
for part in parts:
|
| 116 |
+
if part == video_token:
|
| 117 |
+
if current_seg_idx < len(video_segments):
|
| 118 |
+
if frame_in_seg % self.video_processor.temporal_patch_size == 0:
|
| 119 |
+
# Keep this video token
|
| 120 |
+
final_parts.append(part)
|
| 121 |
+
frame_in_seg += 1
|
| 122 |
+
if frame_in_seg >= video_segments[current_seg_idx]:
|
| 123 |
+
current_seg_idx += 1
|
| 124 |
+
frame_in_seg = 0
|
| 125 |
+
last_timestamp_len = 0
|
| 126 |
+
else:
|
| 127 |
+
# Skip this video token
|
| 128 |
+
frame_in_seg += 1
|
| 129 |
+
if frame_in_seg >= video_segments[current_seg_idx]:
|
| 130 |
+
current_seg_idx += 1
|
| 131 |
+
frame_in_seg = 0
|
| 132 |
+
# Remove the timestamp that was already appended
|
| 133 |
+
if last_timestamp_len > 0:
|
| 134 |
+
# Truncate the last part to remove timestamp
|
| 135 |
+
assert len(final_parts) > 0
|
| 136 |
+
final_parts[-1] = final_parts[-1][:-last_timestamp_len]
|
| 137 |
+
last_timestamp_len = 0
|
| 138 |
+
else:
|
| 139 |
+
# No more video segments, keep as is
|
| 140 |
+
final_parts.append(part)
|
| 141 |
+
last_timestamp_len = 0
|
| 142 |
+
else:
|
| 143 |
+
# Text part
|
| 144 |
+
final_parts.append(part)
|
| 145 |
+
# Check if this text ends with a timestamp
|
| 146 |
+
if is_timestamp(part):
|
| 147 |
+
last_timestamp_len = len(extract_timestamp(part))
|
| 148 |
+
else:
|
| 149 |
+
last_timestamp_len = 0
|
| 150 |
+
|
| 151 |
+
return "".join(final_parts)
|
| 152 |
+
|
| 153 |
+
def __call__(
|
| 154 |
+
self,
|
| 155 |
+
images=None,
|
| 156 |
+
text=None,
|
| 157 |
+
videos=None,
|
| 158 |
+
**kwargs: Unpack[MiniMaxVLProcessorKwargs],
|
| 159 |
+
) -> BatchFeature:
|
| 160 |
+
output_kwargs = self._merge_kwargs(
|
| 161 |
+
MiniMaxVLProcessorKwargs,
|
| 162 |
+
tokenizer_init_kwargs=self.tokenizer.init_kwargs,
|
| 163 |
+
**kwargs,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
if images is not None:
|
| 167 |
+
images_kwargs = output_kwargs["images_kwargs"]
|
| 168 |
+
image_inputs = self.image_processor(images=images, **images_kwargs)
|
| 169 |
+
image_grid_thw = image_inputs["image_grid_thw"]
|
| 170 |
+
|
| 171 |
+
else:
|
| 172 |
+
image_inputs = {}
|
| 173 |
+
image_grid_thw = None
|
| 174 |
+
|
| 175 |
+
if videos is not None:
|
| 176 |
+
videos_kwargs = output_kwargs["videos_kwargs"]
|
| 177 |
+
video_inputs = self.video_processor(videos=videos, **videos_kwargs)
|
| 178 |
+
video_grid_thw = video_inputs["video_grid_thw"]
|
| 179 |
+
if not kwargs.get("return_metadata"):
|
| 180 |
+
video_metadata = video_inputs.pop("video_metadata")
|
| 181 |
+
else:
|
| 182 |
+
video_metadata = video_inputs["video_metadata"]
|
| 183 |
+
else:
|
| 184 |
+
video_inputs = {}
|
| 185 |
+
video_grid_thw = None
|
| 186 |
+
|
| 187 |
+
if not isinstance(text, list):
|
| 188 |
+
text = [text]
|
| 189 |
+
text = text.copy()
|
| 190 |
+
|
| 191 |
+
# Expand image tokens
|
| 192 |
+
if image_grid_thw is not None:
|
| 193 |
+
merge_length = self.image_processor.merge_size**2
|
| 194 |
+
placeholder = "]<]placeholder[>["
|
| 195 |
+
index = 0
|
| 196 |
+
for i in range(len(text)):
|
| 197 |
+
while self.IMAGE_TOKEN in text[i]:
|
| 198 |
+
num_tokens = image_grid_thw[index].prod() // merge_length
|
| 199 |
+
text[i] = text[i].replace(
|
| 200 |
+
self.IMAGE_TOKEN,
|
| 201 |
+
self.VISION_START_TOKEN
|
| 202 |
+
+ placeholder * num_tokens
|
| 203 |
+
+ self.VISION_END_TOKEN,
|
| 204 |
+
1,
|
| 205 |
+
)
|
| 206 |
+
index += 1
|
| 207 |
+
text[i] = text[i].replace(placeholder, self.IMAGE_TOKEN)
|
| 208 |
+
|
| 209 |
+
# Expand video tokens
|
| 210 |
+
if video_grid_thw is not None:
|
| 211 |
+
merge_length = self.image_processor.merge_size**2
|
| 212 |
+
placeholder = "]<]placeholder[>["
|
| 213 |
+
index = 0
|
| 214 |
+
for i in range(len(text)):
|
| 215 |
+
while self.VIDEO_TOKEN in text[i]:
|
| 216 |
+
metadata = video_metadata[index]
|
| 217 |
+
grid_t = video_grid_thw[index][0]
|
| 218 |
+
frame_seqlen = video_grid_thw[index][1:].prod() // merge_length
|
| 219 |
+
|
| 220 |
+
video_placeholder = ""
|
| 221 |
+
for frame_idx in range(grid_t):
|
| 222 |
+
if (
|
| 223 |
+
metadata.fps is not None
|
| 224 |
+
and metadata.frames_indices is not None
|
| 225 |
+
):
|
| 226 |
+
ts = (
|
| 227 |
+
metadata.frames_indices[
|
| 228 |
+
min(
|
| 229 |
+
frame_idx
|
| 230 |
+
* self.video_processor.temporal_patch_size,
|
| 231 |
+
len(metadata.frames_indices) - 1,
|
| 232 |
+
)
|
| 233 |
+
]
|
| 234 |
+
/ metadata.fps
|
| 235 |
+
)
|
| 236 |
+
video_placeholder += f"]<]{ts:.1f} seconds[>["
|
| 237 |
+
video_placeholder += (
|
| 238 |
+
self.VISION_START_TOKEN
|
| 239 |
+
+ placeholder * frame_seqlen
|
| 240 |
+
+ self.VISION_END_TOKEN
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
text[i] = text[i].replace(self.VIDEO_TOKEN, video_placeholder, 1)
|
| 244 |
+
index += 1
|
| 245 |
+
text[i] = text[i].replace(placeholder, self.VIDEO_TOKEN)
|
| 246 |
+
|
| 247 |
+
# Tokenize
|
| 248 |
+
return_tensors = output_kwargs["text_kwargs"].pop("return_tensors", None)
|
| 249 |
+
text_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
|
| 250 |
+
|
| 251 |
+
return BatchFeature(
|
| 252 |
+
data={**text_inputs, **image_inputs, **video_inputs},
|
| 253 |
+
tensor_type=return_tensors,
|
| 254 |
+
)
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "]~b]",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "[e~[",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
}
|
| 16 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,501 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"200000": {
|
| 5 |
+
"content": "]!p~[",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"200001": {
|
| 13 |
+
"content": "<fim_prefix>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"200002": {
|
| 21 |
+
"content": "<fim_middle>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"200003": {
|
| 29 |
+
"content": "<fim_suffix>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"200004": {
|
| 37 |
+
"content": "<fim_pad>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"200005": {
|
| 45 |
+
"content": "<reponame>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"200006": {
|
| 53 |
+
"content": "<filename>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"200007": {
|
| 61 |
+
"content": "<gh_stars>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"200008": {
|
| 69 |
+
"content": "<issue_start>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"200009": {
|
| 77 |
+
"content": "<issue_comment>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"200010": {
|
| 85 |
+
"content": "<issue_closed>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"200011": {
|
| 93 |
+
"content": "<jupyter_start>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"200012": {
|
| 101 |
+
"content": "<jupyter_text>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"200013": {
|
| 109 |
+
"content": "<jupyter_code>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"200014": {
|
| 117 |
+
"content": "<jupyter_output>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"200015": {
|
| 125 |
+
"content": "<empty_output>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"200016": {
|
| 133 |
+
"content": "<commit_before>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"200017": {
|
| 141 |
+
"content": "<commit_msg>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"200018": {
|
| 149 |
+
"content": "<commit_after>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"200019": {
|
| 157 |
+
"content": "]~b]",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"200020": {
|
| 165 |
+
"content": "[e~[",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
},
|
| 172 |
+
"200021": {
|
| 173 |
+
"content": "]!d~[",
|
| 174 |
+
"lstrip": false,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": false,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": true
|
| 179 |
+
},
|
| 180 |
+
"200022": {
|
| 181 |
+
"content": "<function_call>",
|
| 182 |
+
"lstrip": false,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": false,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": true
|
| 187 |
+
},
|
| 188 |
+
"200023": {
|
| 189 |
+
"content": "<code_interpreter>",
|
| 190 |
+
"lstrip": false,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": false,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": true
|
| 195 |
+
},
|
| 196 |
+
"200024": {
|
| 197 |
+
"content": "]<]speech[>[",
|
| 198 |
+
"lstrip": false,
|
| 199 |
+
"normalized": false,
|
| 200 |
+
"rstrip": false,
|
| 201 |
+
"single_word": false,
|
| 202 |
+
"special": true
|
| 203 |
+
},
|
| 204 |
+
"200025": {
|
| 205 |
+
"content": "]<]image[>[",
|
| 206 |
+
"lstrip": false,
|
| 207 |
+
"normalized": false,
|
| 208 |
+
"rstrip": false,
|
| 209 |
+
"single_word": false,
|
| 210 |
+
"special": true
|
| 211 |
+
},
|
| 212 |
+
"200026": {
|
| 213 |
+
"content": "]<]video[>[",
|
| 214 |
+
"lstrip": false,
|
| 215 |
+
"normalized": false,
|
| 216 |
+
"rstrip": false,
|
| 217 |
+
"single_word": false,
|
| 218 |
+
"special": true
|
| 219 |
+
},
|
| 220 |
+
"200027": {
|
| 221 |
+
"content": "]<]start of speech[>[",
|
| 222 |
+
"lstrip": false,
|
| 223 |
+
"normalized": false,
|
| 224 |
+
"rstrip": false,
|
| 225 |
+
"single_word": false,
|
| 226 |
+
"special": true
|
| 227 |
+
},
|
| 228 |
+
"200028": {
|
| 229 |
+
"content": "]<]end of speech[>[",
|
| 230 |
+
"lstrip": false,
|
| 231 |
+
"normalized": false,
|
| 232 |
+
"rstrip": false,
|
| 233 |
+
"single_word": false,
|
| 234 |
+
"special": true
|
| 235 |
+
},
|
| 236 |
+
"200029": {
|
| 237 |
+
"content": "]<]start of image[>[",
|
| 238 |
+
"lstrip": false,
|
| 239 |
+
"normalized": false,
|
| 240 |
+
"rstrip": false,
|
| 241 |
+
"single_word": false,
|
| 242 |
+
"special": true
|
| 243 |
+
},
|
| 244 |
+
"200030": {
|
| 245 |
+
"content": "]<]end of image[>[",
|
| 246 |
+
"lstrip": false,
|
| 247 |
+
"normalized": false,
|
| 248 |
+
"rstrip": false,
|
| 249 |
+
"single_word": false,
|
| 250 |
+
"special": true
|
| 251 |
+
},
|
| 252 |
+
"200031": {
|
| 253 |
+
"content": "]<]start of video[>[",
|
| 254 |
+
"lstrip": false,
|
| 255 |
+
"normalized": false,
|
| 256 |
+
"rstrip": false,
|
| 257 |
+
"single_word": false,
|
| 258 |
+
"special": true
|
| 259 |
+
},
|
| 260 |
+
"200032": {
|
| 261 |
+
"content": "]<]end of video[>[",
|
| 262 |
+
"lstrip": false,
|
| 263 |
+
"normalized": false,
|
| 264 |
+
"rstrip": false,
|
| 265 |
+
"single_word": false,
|
| 266 |
+
"special": true
|
| 267 |
+
},
|
| 268 |
+
"200033": {
|
| 269 |
+
"content": "]<]vision pad[>[",
|
| 270 |
+
"lstrip": false,
|
| 271 |
+
"normalized": false,
|
| 272 |
+
"rstrip": false,
|
| 273 |
+
"single_word": false,
|
| 274 |
+
"special": true
|
| 275 |
+
},
|
| 276 |
+
"200034": {
|
| 277 |
+
"content": "]~!b[",
|
| 278 |
+
"lstrip": false,
|
| 279 |
+
"normalized": false,
|
| 280 |
+
"rstrip": false,
|
| 281 |
+
"single_word": false,
|
| 282 |
+
"special": true
|
| 283 |
+
},
|
| 284 |
+
"200035": {
|
| 285 |
+
"content": "<jupyter_error>",
|
| 286 |
+
"lstrip": false,
|
| 287 |
+
"normalized": false,
|
| 288 |
+
"rstrip": false,
|
| 289 |
+
"single_word": false,
|
| 290 |
+
"special": true
|
| 291 |
+
},
|
| 292 |
+
"200036": {
|
| 293 |
+
"content": "<add_file>",
|
| 294 |
+
"lstrip": false,
|
| 295 |
+
"normalized": false,
|
| 296 |
+
"rstrip": false,
|
| 297 |
+
"single_word": false,
|
| 298 |
+
"special": true
|
| 299 |
+
},
|
| 300 |
+
"200037": {
|
| 301 |
+
"content": "<delete_file>",
|
| 302 |
+
"lstrip": false,
|
| 303 |
+
"normalized": false,
|
| 304 |
+
"rstrip": false,
|
| 305 |
+
"single_word": false,
|
| 306 |
+
"special": true
|
| 307 |
+
},
|
| 308 |
+
"200038": {
|
| 309 |
+
"content": "<rename_file>",
|
| 310 |
+
"lstrip": false,
|
| 311 |
+
"normalized": false,
|
| 312 |
+
"rstrip": false,
|
| 313 |
+
"single_word": false,
|
| 314 |
+
"special": true
|
| 315 |
+
},
|
| 316 |
+
"200039": {
|
| 317 |
+
"content": "<edit_file>",
|
| 318 |
+
"lstrip": false,
|
| 319 |
+
"normalized": false,
|
| 320 |
+
"rstrip": false,
|
| 321 |
+
"single_word": false,
|
| 322 |
+
"special": true
|
| 323 |
+
},
|
| 324 |
+
"200040": {
|
| 325 |
+
"content": "<commit_message>",
|
| 326 |
+
"lstrip": false,
|
| 327 |
+
"normalized": false,
|
| 328 |
+
"rstrip": false,
|
| 329 |
+
"single_word": false,
|
| 330 |
+
"special": true
|
| 331 |
+
},
|
| 332 |
+
"200041": {
|
| 333 |
+
"content": "<empty_source_file>",
|
| 334 |
+
"lstrip": false,
|
| 335 |
+
"normalized": false,
|
| 336 |
+
"rstrip": false,
|
| 337 |
+
"single_word": false,
|
| 338 |
+
"special": true
|
| 339 |
+
},
|
| 340 |
+
"200042": {
|
| 341 |
+
"content": "<repo_struct>",
|
| 342 |
+
"lstrip": false,
|
| 343 |
+
"normalized": false,
|
| 344 |
+
"rstrip": false,
|
| 345 |
+
"single_word": false,
|
| 346 |
+
"special": true
|
| 347 |
+
},
|
| 348 |
+
"200043": {
|
| 349 |
+
"content": "<code_context>",
|
| 350 |
+
"lstrip": false,
|
| 351 |
+
"normalized": false,
|
| 352 |
+
"rstrip": false,
|
| 353 |
+
"single_word": false,
|
| 354 |
+
"special": true
|
| 355 |
+
},
|
| 356 |
+
"200044": {
|
| 357 |
+
"content": "<file_content>",
|
| 358 |
+
"lstrip": false,
|
| 359 |
+
"normalized": false,
|
| 360 |
+
"rstrip": false,
|
| 361 |
+
"single_word": false,
|
| 362 |
+
"special": true
|
| 363 |
+
},
|
| 364 |
+
"200045": {
|
| 365 |
+
"content": "<source_files>",
|
| 366 |
+
"lstrip": false,
|
| 367 |
+
"normalized": false,
|
| 368 |
+
"rstrip": false,
|
| 369 |
+
"single_word": false,
|
| 370 |
+
"special": true
|
| 371 |
+
},
|
| 372 |
+
"200046": {
|
| 373 |
+
"content": "<pr_start>",
|
| 374 |
+
"lstrip": false,
|
| 375 |
+
"normalized": false,
|
| 376 |
+
"rstrip": false,
|
| 377 |
+
"single_word": false,
|
| 378 |
+
"special": true
|
| 379 |
+
},
|
| 380 |
+
"200047": {
|
| 381 |
+
"content": "<review_comment>",
|
| 382 |
+
"lstrip": false,
|
| 383 |
+
"normalized": false,
|
| 384 |
+
"rstrip": false,
|
| 385 |
+
"single_word": false,
|
| 386 |
+
"special": true
|
| 387 |
+
},
|
| 388 |
+
"200048": {
|
| 389 |
+
"content": "<filepath>",
|
| 390 |
+
"lstrip": false,
|
| 391 |
+
"normalized": false,
|
| 392 |
+
"rstrip": false,
|
| 393 |
+
"single_word": false,
|
| 394 |
+
"special": true
|
| 395 |
+
},
|
| 396 |
+
"200049": {
|
| 397 |
+
"content": "<file_sep>",
|
| 398 |
+
"lstrip": false,
|
| 399 |
+
"normalized": false,
|
| 400 |
+
"rstrip": false,
|
| 401 |
+
"single_word": false,
|
| 402 |
+
"special": true
|
| 403 |
+
},
|
| 404 |
+
"200050": {
|
| 405 |
+
"content": "<think>",
|
| 406 |
+
"lstrip": false,
|
| 407 |
+
"normalized": false,
|
| 408 |
+
"rstrip": false,
|
| 409 |
+
"single_word": false,
|
| 410 |
+
"special": false
|
| 411 |
+
},
|
| 412 |
+
"200051": {
|
| 413 |
+
"content": "</think>",
|
| 414 |
+
"lstrip": false,
|
| 415 |
+
"normalized": false,
|
| 416 |
+
"rstrip": false,
|
| 417 |
+
"single_word": false,
|
| 418 |
+
"special": false
|
| 419 |
+
},
|
| 420 |
+
"200052": {
|
| 421 |
+
"content": "<tool_call>",
|
| 422 |
+
"lstrip": false,
|
| 423 |
+
"normalized": false,
|
| 424 |
+
"rstrip": false,
|
| 425 |
+
"single_word": false,
|
| 426 |
+
"special": false
|
| 427 |
+
},
|
| 428 |
+
"200053": {
|
| 429 |
+
"content": "</tool_call>",
|
| 430 |
+
"lstrip": false,
|
| 431 |
+
"normalized": false,
|
| 432 |
+
"rstrip": false,
|
| 433 |
+
"single_word": false,
|
| 434 |
+
"special": false
|
| 435 |
+
},
|
| 436 |
+
"200054": {
|
| 437 |
+
"content": "]<]frame[>[",
|
| 438 |
+
"lstrip": false,
|
| 439 |
+
"normalized": false,
|
| 440 |
+
"rstrip": false,
|
| 441 |
+
"single_word": false,
|
| 442 |
+
"special": true
|
| 443 |
+
},
|
| 444 |
+
"200055": {
|
| 445 |
+
"content": "]<]start of frame[>[",
|
| 446 |
+
"lstrip": false,
|
| 447 |
+
"normalized": false,
|
| 448 |
+
"rstrip": false,
|
| 449 |
+
"single_word": false,
|
| 450 |
+
"special": true
|
| 451 |
+
},
|
| 452 |
+
"200056": {
|
| 453 |
+
"content": "]<]end of frame[>[",
|
| 454 |
+
"lstrip": false,
|
| 455 |
+
"normalized": false,
|
| 456 |
+
"rstrip": false,
|
| 457 |
+
"single_word": false,
|
| 458 |
+
"special": true
|
| 459 |
+
},
|
| 460 |
+
"200057": {
|
| 461 |
+
"content": "<|content_altered_placeholder|>",
|
| 462 |
+
"lstrip": false,
|
| 463 |
+
"normalized": false,
|
| 464 |
+
"rstrip": false,
|
| 465 |
+
"single_word": false,
|
| 466 |
+
"special": true
|
| 467 |
+
},
|
| 468 |
+
"200058": {
|
| 469 |
+
"content": "]<]minimax[>[",
|
| 470 |
+
"lstrip": false,
|
| 471 |
+
"normalized": false,
|
| 472 |
+
"rstrip": false,
|
| 473 |
+
"single_word": false,
|
| 474 |
+
"special": false
|
| 475 |
+
},
|
| 476 |
+
"200059": {
|
| 477 |
+
"content": "<mm:think>",
|
| 478 |
+
"lstrip": false,
|
| 479 |
+
"normalized": false,
|
| 480 |
+
"rstrip": false,
|
| 481 |
+
"single_word": false,
|
| 482 |
+
"special": false
|
| 483 |
+
},
|
| 484 |
+
"200060": {
|
| 485 |
+
"content": "</mm:think>",
|
| 486 |
+
"lstrip": false,
|
| 487 |
+
"normalized": false,
|
| 488 |
+
"rstrip": false,
|
| 489 |
+
"single_word": false,
|
| 490 |
+
"special": false
|
| 491 |
+
}
|
| 492 |
+
},
|
| 493 |
+
"bos_token": "]~b]",
|
| 494 |
+
"clean_up_tokenization_spaces": false,
|
| 495 |
+
"eos_token": "[e~[",
|
| 496 |
+
"pad_token": "]!p~[",
|
| 497 |
+
"model_max_length": 40960000,
|
| 498 |
+
"tokenizer_class": "PreTrainedTokenizerFast",
|
| 499 |
+
"unk_token": "[e~["
|
| 500 |
+
}
|
| 501 |
+
|
video_processor.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023-2024 SGLang Team
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
"""
|
| 4 |
+
MiniMax VL family HuggingFace-compatible VideoProcessor.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
from typing import List, Optional, Tuple, Union
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torchvision
|
| 12 |
+
from torchvision.transforms import InterpolationMode
|
| 13 |
+
from transformers import BatchFeature
|
| 14 |
+
from transformers.image_utils import PILImageResampling, SizeDict
|
| 15 |
+
from transformers.processing_utils import (
|
| 16 |
+
Unpack,
|
| 17 |
+
VideosKwargs,
|
| 18 |
+
)
|
| 19 |
+
from transformers.utils import TensorType
|
| 20 |
+
from transformers.video_processing_utils import BaseVideoProcessor
|
| 21 |
+
from transformers.video_utils import group_videos_by_shape, reorder_videos
|
| 22 |
+
|
| 23 |
+
MAX_RATIO = 200
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def round_by_factor(number: int, factor: int) -> int:
|
| 27 |
+
return round(number / factor) * factor
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def ceil_by_factor(number: int, factor: int) -> int:
|
| 31 |
+
return math.ceil(number / factor) * factor
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def floor_by_factor(number: int, factor: int) -> int:
|
| 35 |
+
return math.floor(number / factor) * factor
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def smart_resize(
|
| 39 |
+
height: int,
|
| 40 |
+
width: int,
|
| 41 |
+
factor: int = 28,
|
| 42 |
+
min_pixels: int = 4 * 28 * 28,
|
| 43 |
+
max_pixels: int = 451584,
|
| 44 |
+
) -> tuple[int, int]:
|
| 45 |
+
if max(height, width) / min(height, width) > MAX_RATIO:
|
| 46 |
+
raise ValueError(
|
| 47 |
+
f"absolute aspect ratio must be smaller than {MAX_RATIO}, "
|
| 48 |
+
f"got {max(height, width) / min(height, width)}"
|
| 49 |
+
)
|
| 50 |
+
h_bar = max(factor, round_by_factor(height, factor))
|
| 51 |
+
w_bar = max(factor, round_by_factor(width, factor))
|
| 52 |
+
if h_bar * w_bar > max_pixels:
|
| 53 |
+
beta = math.sqrt((height * width) / max_pixels)
|
| 54 |
+
h_bar = floor_by_factor(height / beta, factor)
|
| 55 |
+
w_bar = floor_by_factor(width / beta, factor)
|
| 56 |
+
elif h_bar * w_bar < min_pixels:
|
| 57 |
+
beta = math.sqrt(min_pixels / (height * width))
|
| 58 |
+
h_bar = ceil_by_factor(height * beta, factor)
|
| 59 |
+
w_bar = ceil_by_factor(width * beta, factor)
|
| 60 |
+
return h_bar, w_bar
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class MiniMaxM3VLVideoProcessorKwargs(VideosKwargs, total=False):
|
| 64 |
+
patch_size: int
|
| 65 |
+
temporal_patch_size: int
|
| 66 |
+
merge_size: int
|
| 67 |
+
min_pixels: int
|
| 68 |
+
max_pixels: int
|
| 69 |
+
total_pixels: int
|
| 70 |
+
min_frames: int
|
| 71 |
+
max_frames: int
|
| 72 |
+
fps: float | int
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class MiniMaxM3VLVideoProcessor(BaseVideoProcessor):
|
| 76 |
+
do_resize = True
|
| 77 |
+
resample = PILImageResampling.BICUBIC
|
| 78 |
+
size = {"height": 672, "width": 672}
|
| 79 |
+
default_to_square = False
|
| 80 |
+
do_rescale = True
|
| 81 |
+
rescale_factor = 1 / 255
|
| 82 |
+
do_normalize = True
|
| 83 |
+
image_mean = [0.48145466, 0.4578275, 0.40821073]
|
| 84 |
+
image_std = [0.26862954, 0.26130258, 0.27577711]
|
| 85 |
+
do_convert_rgb = True
|
| 86 |
+
do_sample_frames = False
|
| 87 |
+
patch_size = 14
|
| 88 |
+
temporal_patch_size = 2
|
| 89 |
+
merge_size = 2
|
| 90 |
+
min_pixels = 4 * 28 * 28
|
| 91 |
+
max_pixels = 768 * 28 * 28 # 602,112
|
| 92 |
+
total_pixels = int(64000 * 28 * 28 * 0.9) # ~45M, ~64k tokens budget
|
| 93 |
+
fps = 1.0
|
| 94 |
+
min_frames = 4
|
| 95 |
+
max_frames = 768
|
| 96 |
+
valid_kwargs = MiniMaxM3VLVideoProcessorKwargs
|
| 97 |
+
model_input_names = ["pixel_values_videos", "video_grid_thw"]
|
| 98 |
+
|
| 99 |
+
def __init__(self, **kwargs: Unpack[MiniMaxM3VLVideoProcessorKwargs]):
|
| 100 |
+
super().__init__(**kwargs)
|
| 101 |
+
|
| 102 |
+
def _preprocess(
|
| 103 |
+
self,
|
| 104 |
+
videos: List[torch.Tensor],
|
| 105 |
+
do_convert_rgb: bool,
|
| 106 |
+
do_resize: bool,
|
| 107 |
+
size: SizeDict,
|
| 108 |
+
resample: PILImageResampling | InterpolationMode | int | None,
|
| 109 |
+
do_rescale: bool,
|
| 110 |
+
rescale_factor: float,
|
| 111 |
+
do_normalize: bool,
|
| 112 |
+
image_mean: float | List[float] | None,
|
| 113 |
+
image_std: float | List[float] | None,
|
| 114 |
+
patch_size: int,
|
| 115 |
+
temporal_patch_size: int,
|
| 116 |
+
merge_size: int,
|
| 117 |
+
min_pixels: int,
|
| 118 |
+
max_pixels: int,
|
| 119 |
+
return_tensors: str | TensorType | None = None,
|
| 120 |
+
**kwargs,
|
| 121 |
+
) -> BatchFeature:
|
| 122 |
+
grouped_videos, grouped_videos_index = group_videos_by_shape(videos)
|
| 123 |
+
resized_videos_grouped = {}
|
| 124 |
+
factor = patch_size * merge_size
|
| 125 |
+
for shape, stacked_videos in grouped_videos.items():
|
| 126 |
+
batch_size, num_frames, channels, height, width = stacked_videos.shape
|
| 127 |
+
resized_height, resized_width = height, width
|
| 128 |
+
if do_resize:
|
| 129 |
+
resized_height, resized_width = smart_resize(
|
| 130 |
+
height, width, factor=factor,
|
| 131 |
+
min_pixels=min_pixels, max_pixels=max_pixels,
|
| 132 |
+
)
|
| 133 |
+
stacked_videos = stacked_videos.view(
|
| 134 |
+
batch_size * num_frames, channels, height, width
|
| 135 |
+
)
|
| 136 |
+
stacked_videos = self.resize(
|
| 137 |
+
stacked_videos,
|
| 138 |
+
size=SizeDict(height=resized_height, width=resized_width),
|
| 139 |
+
resample=resample,
|
| 140 |
+
)
|
| 141 |
+
stacked_videos = stacked_videos.view(
|
| 142 |
+
batch_size,
|
| 143 |
+
num_frames,
|
| 144 |
+
channels,
|
| 145 |
+
resized_height,
|
| 146 |
+
resized_width,
|
| 147 |
+
)
|
| 148 |
+
resized_videos_grouped[shape] = stacked_videos
|
| 149 |
+
resized_videos = reorder_videos(resized_videos_grouped, grouped_videos_index)
|
| 150 |
+
|
| 151 |
+
grouped_videos, grouped_videos_index = group_videos_by_shape(resized_videos)
|
| 152 |
+
processed_videos_grouped = {}
|
| 153 |
+
processed_grids = {}
|
| 154 |
+
for shape, stacked_videos in grouped_videos.items():
|
| 155 |
+
resized_height, resized_width = stacked_videos.shape[-2:]
|
| 156 |
+
patches = self.rescale_and_normalize(
|
| 157 |
+
stacked_videos,
|
| 158 |
+
do_rescale,
|
| 159 |
+
rescale_factor,
|
| 160 |
+
do_normalize,
|
| 161 |
+
image_mean,
|
| 162 |
+
image_std,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
if pad := -patches.shape[1] % temporal_patch_size:
|
| 166 |
+
repeats = patches[:, -1:].expand(-1, pad, -1, -1, -1)
|
| 167 |
+
patches = torch.cat([patches, repeats], dim=1)
|
| 168 |
+
|
| 169 |
+
batch_size, grid_t, channels = patches.shape[:3]
|
| 170 |
+
grid_t = grid_t // temporal_patch_size
|
| 171 |
+
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
|
| 172 |
+
|
| 173 |
+
patches = patches.view(
|
| 174 |
+
batch_size,
|
| 175 |
+
grid_t,
|
| 176 |
+
temporal_patch_size,
|
| 177 |
+
channels,
|
| 178 |
+
grid_h // merge_size,
|
| 179 |
+
merge_size,
|
| 180 |
+
patch_size,
|
| 181 |
+
grid_w // merge_size,
|
| 182 |
+
merge_size,
|
| 183 |
+
patch_size,
|
| 184 |
+
)
|
| 185 |
+
patches = patches.permute(0, 1, 4, 7, 5, 8, 3, 2, 6, 9)
|
| 186 |
+
flatten_patches = patches.reshape(
|
| 187 |
+
batch_size,
|
| 188 |
+
grid_t * grid_h * grid_w,
|
| 189 |
+
channels * temporal_patch_size * patch_size * patch_size,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
processed_videos_grouped[shape] = flatten_patches
|
| 193 |
+
processed_grids[shape] = [[grid_t, grid_h, grid_w]] * batch_size
|
| 194 |
+
|
| 195 |
+
processed_videos = reorder_videos(
|
| 196 |
+
processed_videos_grouped, grouped_videos_index
|
| 197 |
+
)
|
| 198 |
+
processed_grids = reorder_videos(processed_grids, grouped_videos_index)
|
| 199 |
+
pixel_values_videos = torch.cat(processed_videos, dim=0)
|
| 200 |
+
video_grid_thw = torch.tensor(processed_grids, dtype=torch.long)
|
| 201 |
+
|
| 202 |
+
return BatchFeature(
|
| 203 |
+
data={
|
| 204 |
+
"pixel_values_videos": pixel_values_videos,
|
| 205 |
+
"video_grid_thw": video_grid_thw,
|
| 206 |
+
},
|
| 207 |
+
tensor_type=return_tensors,
|
| 208 |
+
)
|