
docs: rewrite model card + regenerate metric charts
Browse files- replace broken dual-axis size/speed combo with clean throughput chart
- fix ppl-delta label collision; add MTP speedup/acceptance chart
- add model summary, text-only callout, download, prompt format, citation
README.md
CHANGED
|
@@ -1,7 +1,11 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
| 3 |
base_model:
|
| 4 |
- InternScience/Agents-A1
|
|
|
|
|
|
|
| 5 |
library_name: llama.cpp
|
| 6 |
pipeline_tag: text-generation
|
| 7 |
tags:
|
|
@@ -11,28 +15,49 @@ tags:
|
|
| 11 |
- qwen3.5-moe
|
| 12 |
- mixture-of-experts
|
| 13 |
- agents-a1
|
|
|
|
| 14 |
- nvfp4
|
| 15 |
- mtp
|
| 16 |
- speculative-decoding
|
|
|
|
| 17 |
---
|
| 18 |
|
| 19 |
-
# Agents-A1 GGUF
|
| 20 |
|
| 21 |
-
|
| 22 |
|
| 23 |
-
|
| 24 |
|
| 25 |
-
|
|
|
|
| 26 |
|
| 27 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 28 |
|---|---|---|
|
| 29 |
-
| Best small general-purpose quant | `agents-a1-IQ4_XS.gguf` | Strong quality for size, broad llama.cpp compatibility. |
|
| 30 |
-
| Best single-user MTP throughput | `agents-a1-IQ4_XS-MTP-graft-headQ6.gguf` | IQ4_XS body
|
| 31 |
-
| Highest MTP acceptance
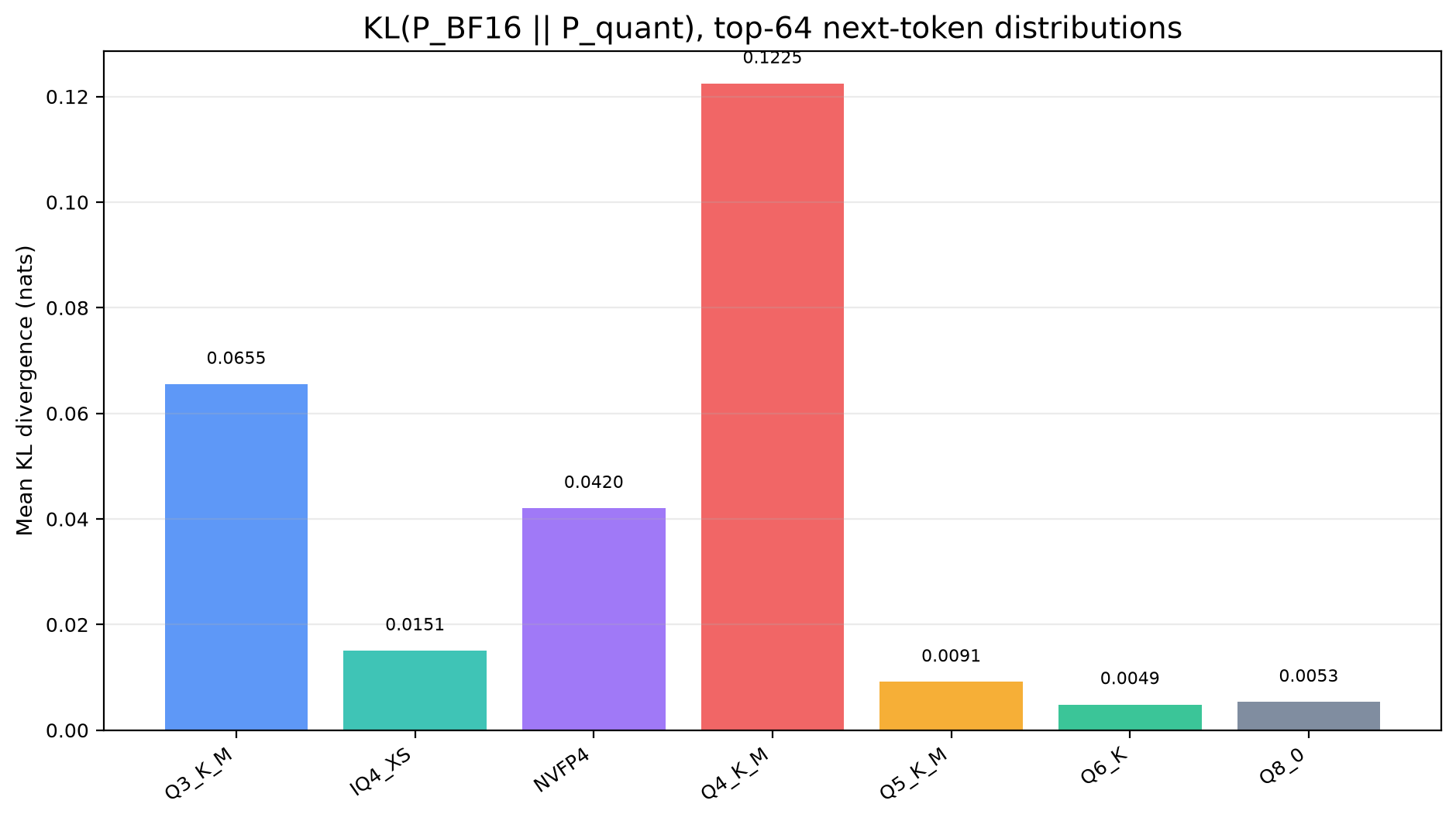
|
| 32 |
-
| Fast Blackwell FP4 path | `agents-a1-NVFP4.gguf` | Tested on RTX PRO 6000 Blackwell.
|
| 33 |
-
| Safer quality step up | `agents-a1-Q5_K_M.gguf` | Lower KLD than IQ4_XS
|
| 34 |
| Closest to BF16 by KLD | `agents-a1-Q6_K.gguf` | Best KLD in this eval set. |
|
| 35 |
-
| High
|
|
|
|
|
|
|
| 36 |
|
| 37 |
## Files
|
| 38 |
|
|
@@ -40,24 +65,106 @@ These files were produced from the BF16 Hugging Face checkpoint with a patched l
|
|
| 40 |
|---|---:|---|
|
| 41 |
| Q3_K_M | 16.76 GB | Smallest included quant. |
|
| 42 |
| IQ4_XS | 18.73 GB | Recommended compact quant. |
|
| 43 |
-
| IQ4_XS-MTP-graft-headQ6 | 19.42 GB | IQ4_XS body
|
| 44 |
-
| NVFP4 | 19.72 GB | Blackwell-oriented FP4 GGUF
|
| 45 |
| Q4_K_M | 21.17 GB | Standard K-quant. |
|
| 46 |
-
| Q4_K_M-MTP-graft-headQ6 | 21.86 GB | Q4_K_M body
|
| 47 |
| Q5_K_M | 24.73 GB | Strong quality/size tradeoff. |
|
| 48 |
| Q6_K | 28.51 GB | Lowest mean KLD in this run. |
|
| 49 |
-
| Q8_0 | 36.90 GB | Highest
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
## Metrics
|
| 52 |
|
| 53 |
Hardware and runtime profile:
|
| 54 |
|
| 55 |
-
- GPU: single NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, full offload
|
| 56 |
-
- llama.cpp flags: `-ngl 99 -sm none -fa on -p 512 -n 128 -b 4096 -ub 512 -r 3`
|
| 57 |
-
- PPL: `llama-perplexity`, context 2048, 64 rendered eval conversations, 3 chunks
|
| 58 |
-
- KLD: approximate `KL(P_BF16 || P_quant)` over top-64 next-token distributions on 32 prompts
|
| 59 |
|
| 60 |
-
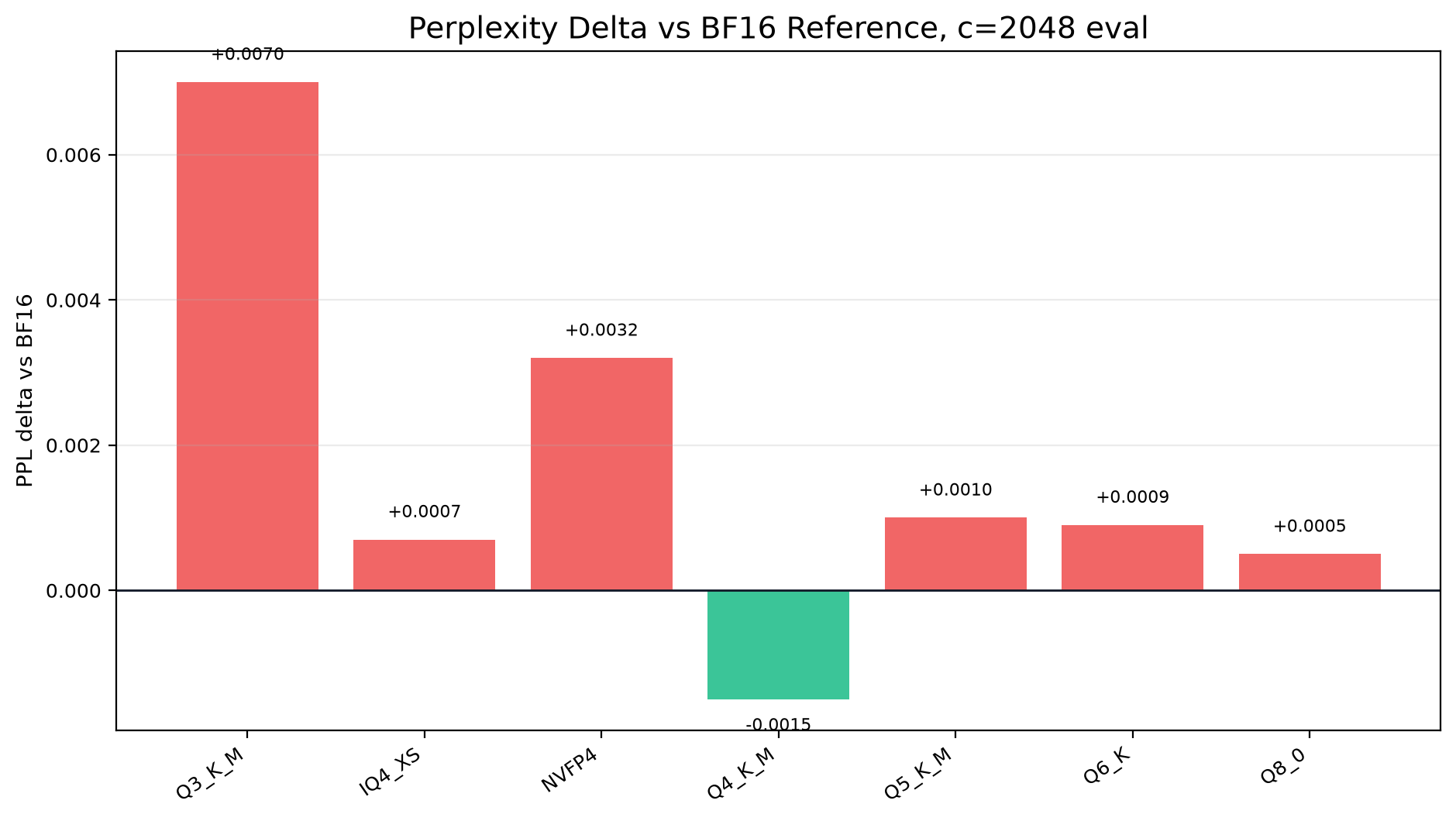
The PPL eval is intentionally small, so treat PPL deltas as directional. KLD and top-1 agreement are more useful
|
| 61 |
|
| 62 |
| Model | Size GB | Prompt tok/s | Gen tok/s | PPL | PPL delta | KLD mean | KLD p95 | Top-1 match |
|
| 63 |
|---|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
@@ -72,24 +179,19 @@ The PPL eval is intentionally small, so treat PPL deltas as directional. KLD and
|
|
| 72 |
|
| 73 |
### Charts
|
| 74 |
|
| 75 |
-

|
| 78 |
|
| 79 |

|
| 80 |
|
| 81 |
-

|
| 82 |
-
|
| 83 |
Raw metric files are in `metrics/`; KLD reports, checksums, and the MTP audit are in `reports/`.
|
| 84 |
|
| 85 |
-
## MTP Q4
|
| 86 |
|
| 87 |
-
The upstream Agents-A1 checkpoint used for the first GGUF release advertises
|
| 88 |
-
MTP in config but does not ship `mtp.*`/`blk.40.*` tensors. The two MTP Q4
|
| 89 |
-
variants here graft in the Agents-A1 MTPLX MTP sidecar from
|
| 90 |
-
`wang-yang/Agents-A1-MTPLX-Q4`, then convert it with llama.cpp's Qwen3.5-MoE
|
| 91 |
-
MTP path. The dense MTP block is preserved at Q6_K while the model body is
|
| 92 |
-
quantized to IQ4_XS or Q4_K_M.
|
| 93 |
|
| 94 |
Structural checks for both MTP GGUFs:
|
| 95 |
|
|
@@ -101,92 +203,46 @@ Structural checks for both MTP GGUFs:
|
|
| 101 |
| `blk.40.*` MTP tensors | 20 |
|
| 102 |
| `blk.40.nextn.*` tensors | 4 |
|
| 103 |
|
| 104 |
-
Single-user serving profile: one RTX PRO 6000 Blackwell Max-Q 96 GB GPU,
|
| 105 |
-
`PARALLEL=1`, `CTX_SIZE=8192`, streaming chat completions, `12` requests,
|
| 106 |
-
`128` max tokens, `temperature=0`, `top_p=1`.
|
| 107 |
|
| 108 |
| Quant | Mode | Aggregate tok/s | Speedup vs target-only | Draft acceptance | Mean accepted length | Acceptance by position |
|
| 109 |
|---|---:|---:|---:|---:|---:|---|
|
| 110 |
-
| IQ4_XS-MTP | target-only | 224.59 | 1.
|
| 111 |
-
| IQ4_XS-MTP | `draft-mtp`, `n_max=2` | 275.03 | 1.
|
| 112 |
-
| IQ4_XS-MTP | `draft-mtp`, `n_max=1` | 259.58 | 1.
|
| 113 |
-
| Q4_K_M-MTP | target-only | 230.48 | 1.
|
| 114 |
-
| Q4_K_M-MTP | `draft-mtp`, `n_max=2` | 273.80 | 1.
|
| 115 |
-
| Q4_K_M-MTP | `draft-mtp`, `n_max=1` | 264.88 | 1.
|
|
|
|
|
|
|
| 116 |
|
| 117 |
-
Recommended low-latency/single-user throughput profile: `SPEC_DRAFT_N_MAX=2`.
|
| 118 |
-
Recommended high-acceptance fallback: `SPEC_DRAFT_N_MAX=1`.
|
| 119 |
|
| 120 |
-
Detailed MTP evidence
|
| 121 |
|
| 122 |
- `reports/agents-a1-mtp-q4-profile-summary.md`
|
| 123 |
- `reports/agents-a1-mtp-q4-profile-summary.json`
|
|
|
|
| 124 |
- `configs/mtp_profiles.yaml`
|
| 125 |
|
| 126 |
-
##
|
| 127 |
|
| 128 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 129 |
|
| 130 |
-
|
| 131 |
-
llama-server \
|
| 132 |
-
-m agents-a1-IQ4_XS.gguf \
|
| 133 |
-
-ngl 99 \
|
| 134 |
-
-c 8192 \
|
| 135 |
-
-b 4096 \
|
| 136 |
-
-ub 512 \
|
| 137 |
-
--flash-attn on
|
| 138 |
-
```
|
| 139 |
|
| 140 |
-
|
| 141 |
|
| 142 |
-
```
|
| 143 |
-
|
| 144 |
-
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
--flash-attn on
|
| 150 |
```
|
| 151 |
-
|
| 152 |
-
The NVFP4 artifact is a standard GGUF using the `NVFP4` tensor type, but runtime support is still newer and less universal than K-quants or IQ4_XS. It was tested on a Blackwell GPU with a llama.cpp build reporting `BLACKWELL_NATIVE_FP4 = 1`.
|
| 153 |
-
|
| 154 |
-
MTP example:
|
| 155 |
-
|
| 156 |
-
```bash
|
| 157 |
-
LLAMA_SPEC_MAX_DRAFTING_SLOTS=1 \
|
| 158 |
-
LLAMA_MTP_FAST_BACKEND_SAMPLE=1 \
|
| 159 |
-
LLAMA_MTP_DRAFT_TOP_K=1 \
|
| 160 |
-
LLAMA_MTP_DRAFT_TOP_P=1 \
|
| 161 |
-
LLAMA_MTP_DRAFT_TEMP=1 \
|
| 162 |
-
llama-server \
|
| 163 |
-
-m agents-a1-IQ4_XS-MTP-graft-headQ6.gguf \
|
| 164 |
-
-ngl 99 \
|
| 165 |
-
-c 8192 \
|
| 166 |
-
-b 4096 \
|
| 167 |
-
-ub 512 \
|
| 168 |
-
--flash-attn on \
|
| 169 |
-
--reasoning off \
|
| 170 |
-
--spec-type draft-mtp \
|
| 171 |
-
--spec-draft-n-max 2 \
|
| 172 |
-
--spec-draft-n-min 0 \
|
| 173 |
-
--spec-draft-backend-sampling
|
| 174 |
-
```
|
| 175 |
-
|
| 176 |
-
For the high-acceptance profile, change `--spec-draft-n-max 2` to
|
| 177 |
-
`--spec-draft-n-max 1`.
|
| 178 |
-
|
| 179 |
-
## MTP Status
|
| 180 |
-
|
| 181 |
-
The original upstream snapshot remains config-only for MTP; see
|
| 182 |
-
`reports/mtp-weights-audit.json`. The new `*-MTP-graft-headQ6.gguf` files are
|
| 183 |
-
true integrated MTP GGUFs built from the Agents-A1 MTPLX MTP sidecar.
|
| 184 |
-
|
| 185 |
-
## Provenance
|
| 186 |
-
|
| 187 |
-
- Base model: `InternScience/Agents-A1`
|
| 188 |
-
- License: Apache-2.0, inherited from the base model
|
| 189 |
-
- Quantization source: BF16 GGUF converted from the Hugging Face checkpoint
|
| 190 |
-
- MTP source: `wang-yang/Agents-A1-MTPLX-Q4` sidecar grafted onto the base Agents-A1 checkpoint
|
| 191 |
-
- Calibration: coding/instruction chat data rendered with the model chat template
|
| 192 |
-
- Quantizer: patched llama.cpp with Qwen3.5-MoE and NVFP4 support
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
base_model:
|
| 6 |
- InternScience/Agents-A1
|
| 7 |
+
base_model_relation: quantized
|
| 8 |
+
quantized_by: LordNeel
|
| 9 |
library_name: llama.cpp
|
| 10 |
pipeline_tag: text-generation
|
| 11 |
tags:
|
|
|
|
| 15 |
- qwen3.5-moe
|
| 16 |
- mixture-of-experts
|
| 17 |
- agents-a1
|
| 18 |
+
- agent
|
| 19 |
- nvfp4
|
| 20 |
- mtp
|
| 21 |
- speculative-decoding
|
| 22 |
+
- imatrix
|
| 23 |
---
|
| 24 |
|
| 25 |
+
# Agents-A1 GGUF
|
| 26 |
|
| 27 |
+
GGUF quantizations of [**InternScience/Agents-A1**](https://huggingface.co/InternScience/Agents-A1) — a 35B Mixture-of-Experts **agentic** model (Qwen3.5-MoE architecture) built for long-horizon search, engineering, scientific research, instruction-following, and tool-calling.
|
| 28 |
|
| 29 |
+
Files were produced from the BF16 Hugging Face checkpoint with a patched `llama.cpp` build that supports the `qwen35moe` architecture. Each quant uses an importance matrix (imatrix) built from coding/instruction-chat calibration data, and every file was benchmarked against the BF16 GGUF reference (PPL, KL-divergence, top-1 agreement).
|
| 30 |
|
| 31 |
+
> [!IMPORTANT]
|
| 32 |
+
> **These are text-only GGUFs.** The base model is multimodal (vision + video), but no `mmproj` projector is shipped here, so image/video input is not available with these files. Use them for text and agentic/tool-calling workloads.
|
| 33 |
|
| 34 |
+
## Model summary
|
| 35 |
+
|
| 36 |
+
| | |
|
| 37 |
+
|---|---|
|
| 38 |
+
| Base model | [InternScience/Agents-A1](https://huggingface.co/InternScience/Agents-A1) ([paper](https://arxiv.org/abs/2606.30616) · [homepage](https://internscience.github.io/Agents-A1/) · [GitHub](https://github.com/InternScience/Agents-A1)) |
|
| 39 |
+
| Architecture | Qwen3.5-MoE, hybrid linear/full attention (full attention every 4th layer) |
|
| 40 |
+
| Parameters | ~35B total, ~3B active per token (A3B-class) |
|
| 41 |
+
| Experts | 256 experts, 8 active + 1 shared per token |
|
| 42 |
+
| Layers | 40 transformer layers + 1 MTP layer |
|
| 43 |
+
| Context length | 262,144 (256K) native |
|
| 44 |
+
| Language | English |
|
| 45 |
+
| License | Apache-2.0 (inherited from base) |
|
| 46 |
+
| Quantized by | [LordNeel](https://huggingface.co/LordNeel) |
|
| 47 |
+
|
| 48 |
+
## Which file should I pick?
|
| 49 |
+
|
| 50 |
+
| Goal | File | Notes |
|
| 51 |
|---|---|---|
|
| 52 |
+
| Best small general-purpose quant | `agents-a1-IQ4_XS.gguf` | Strong quality for size, broad `llama.cpp` compatibility. |
|
| 53 |
+
| Best single-user MTP throughput | `agents-a1-IQ4_XS-MTP-graft-headQ6.gguf` | IQ4_XS body + Q6_K MTP block; **1.22×** over target-only at `n_max=2`. |
|
| 54 |
+
| Highest MTP draft acceptance | `agents-a1-Q4_K_M-MTP-graft-headQ6.gguf` (`SPEC_DRAFT_N_MAX=1`) | **91.46%** acceptance, still 1.15× over target-only. |
|
| 55 |
+
| Fast Blackwell FP4 path | `agents-a1-NVFP4.gguf` | Tested on RTX PRO 6000 Blackwell. Needs runtime support for `GGML_TYPE_NVFP4`. |
|
| 56 |
+
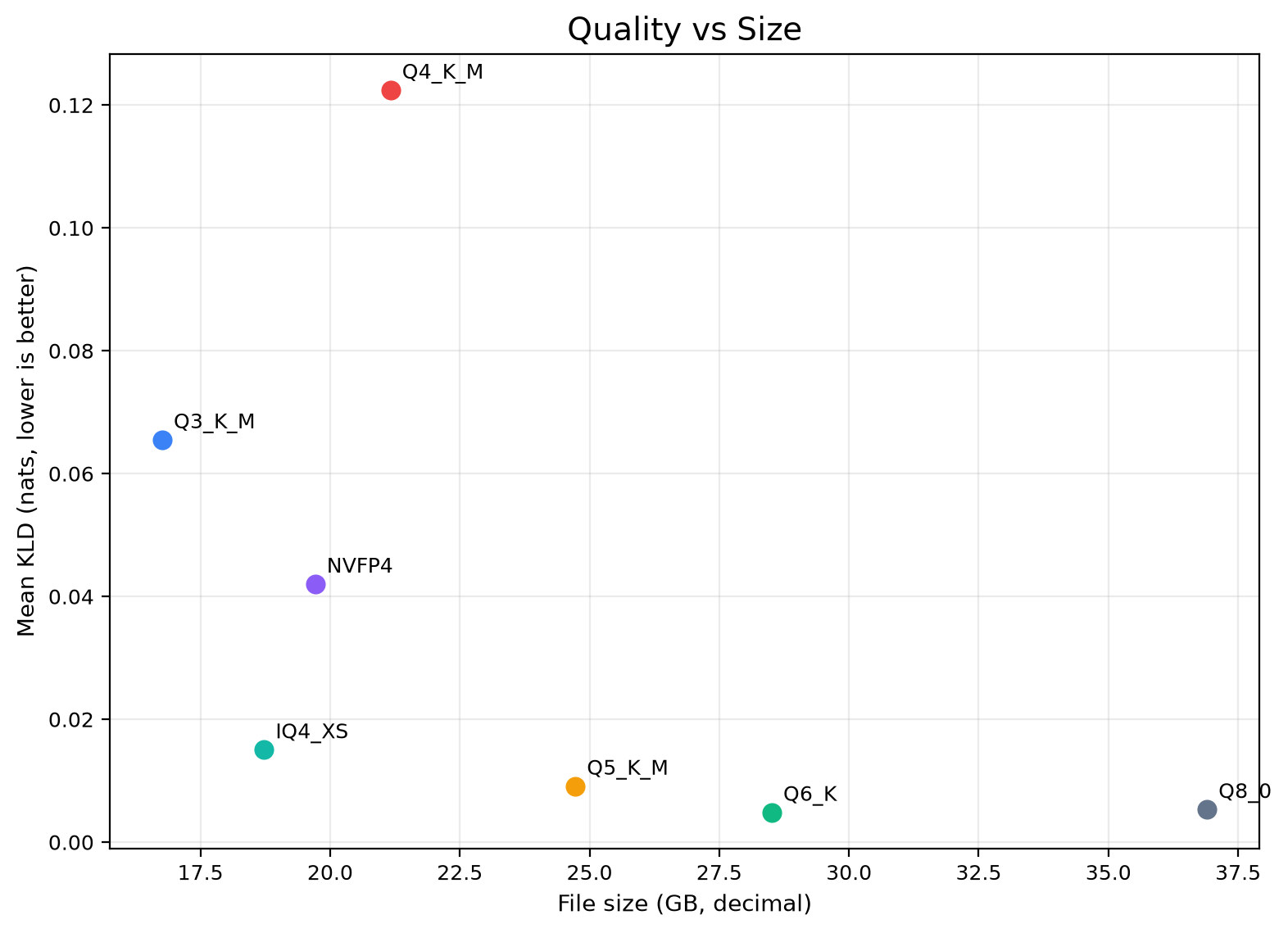
| Safer quality step up | `agents-a1-Q5_K_M.gguf` | Lower KLD than IQ4_XS, larger size. |
|
| 57 |
| Closest to BF16 by KLD | `agents-a1-Q6_K.gguf` | Best KLD in this eval set. |
|
| 58 |
+
| High-precision archival | `agents-a1-Q8_0.gguf` | Largest quant. |
|
| 59 |
+
|
| 60 |
+
**Sizing:** for full GPU offload, give yourself roughly `file size + KV cache` of VRAM. K-quants (`Q4_K_M`, `Q5_K_M`, `Q6_K`) are the most portable. `IQ4_XS` is an I-quant and benefits from the bundled imatrix. `NVFP4` is the fastest prefill path but needs a Blackwell-class GPU and a recent FP4-capable `llama.cpp` build.
|
| 61 |
|
| 62 |
## Files
|
| 63 |
|
|
|
|
| 65 |
|---|---:|---|
|
| 66 |
| Q3_K_M | 16.76 GB | Smallest included quant. |
|
| 67 |
| IQ4_XS | 18.73 GB | Recommended compact quant. |
|
| 68 |
+
| IQ4_XS-MTP-graft-headQ6 | 19.42 GB | IQ4_XS body + integrated Q6_K/F32 MTP block. |
|
| 69 |
+
| NVFP4 | 19.72 GB | Blackwell-oriented FP4 GGUF; output head kept at Q6_K by quality rule. |
|
| 70 |
| Q4_K_M | 21.17 GB | Standard K-quant. |
|
| 71 |
+
| Q4_K_M-MTP-graft-headQ6 | 21.86 GB | Q4_K_M body + integrated Q6_K/F32 MTP block. |
|
| 72 |
| Q5_K_M | 24.73 GB | Strong quality/size tradeoff. |
|
| 73 |
| Q6_K | 28.51 GB | Lowest mean KLD in this run. |
|
| 74 |
+
| Q8_0 | 36.90 GB | Highest-precision quant. |
|
| 75 |
+
|
| 76 |
+
## Download
|
| 77 |
+
|
| 78 |
+
```bash
|
| 79 |
+
pip install -U "huggingface_hub[cli]"
|
| 80 |
+
|
| 81 |
+
# download a single quant into ./agents-a1
|
| 82 |
+
hf download LordNeel/Agents-A1-GGUF agents-a1-IQ4_XS.gguf --local-dir ./agents-a1
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
You generally want a **recent `llama.cpp` build with `qwen35moe` support**; the NVFP4 and MTP files need newer builds still (see the relevant sections below).
|
| 86 |
+
|
| 87 |
+
## Usage
|
| 88 |
+
|
| 89 |
+
Standard inference with the recommended compact quant:
|
| 90 |
+
|
| 91 |
+
```bash
|
| 92 |
+
llama-server \
|
| 93 |
+
-m agents-a1-IQ4_XS.gguf \
|
| 94 |
+
-ngl 99 \
|
| 95 |
+
-c 8192 \
|
| 96 |
+
-b 4096 \
|
| 97 |
+
-ub 512 \
|
| 98 |
+
--flash-attn on
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
`-c 8192` is just a starting point — the model's native context is 256K, so raise `-c` as your VRAM allows.
|
| 102 |
+
|
| 103 |
+
**NVFP4** (Blackwell):
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
llama-server \
|
| 107 |
+
-m agents-a1-NVFP4.gguf \
|
| 108 |
+
-ngl 99 -c 8192 -b 4096 -ub 512 --flash-attn on
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
The NVFP4 artifact is a standard GGUF using the `NVFP4` tensor type, but runtime support is newer and less universal than K-quants or IQ4_XS. It was tested on a Blackwell GPU with a `llama.cpp` build reporting `BLACKWELL_NATIVE_FP4 = 1`.
|
| 112 |
+
|
| 113 |
+
**MTP / speculative decoding** (single-user throughput):
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
LLAMA_SPEC_MAX_DRAFTING_SLOTS=1 \
|
| 117 |
+
LLAMA_MTP_FAST_BACKEND_SAMPLE=1 \
|
| 118 |
+
LLAMA_MTP_DRAFT_TOP_K=1 \
|
| 119 |
+
LLAMA_MTP_DRAFT_TOP_P=1 \
|
| 120 |
+
LLAMA_MTP_DRAFT_TEMP=1 \
|
| 121 |
+
llama-server \
|
| 122 |
+
-m agents-a1-IQ4_XS-MTP-graft-headQ6.gguf \
|
| 123 |
+
-ngl 99 -c 8192 -b 4096 -ub 512 --flash-attn on \
|
| 124 |
+
--reasoning off \
|
| 125 |
+
--spec-type draft-mtp \
|
| 126 |
+
--spec-draft-n-max 2 \
|
| 127 |
+
--spec-draft-n-min 0 \
|
| 128 |
+
--spec-draft-backend-sampling
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
For the high-acceptance profile, change `--spec-draft-n-max 2` to `--spec-draft-n-max 1`.
|
| 132 |
+
|
| 133 |
+
Python with `llama-cpp-python`:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
from llama_cpp import Llama
|
| 137 |
+
|
| 138 |
+
llm = Llama.from_pretrained(
|
| 139 |
+
repo_id="LordNeel/Agents-A1-GGUF",
|
| 140 |
+
filename="agents-a1-IQ4_XS.gguf",
|
| 141 |
+
)
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
### Prompt format
|
| 145 |
+
|
| 146 |
+
Agents-A1 uses a Qwen-style ChatML template (embedded in the GGUF, so `llama-server`/`llama-cli` chat endpoints apply it automatically):
|
| 147 |
+
|
| 148 |
+
```
|
| 149 |
+
<|im_start|>system
|
| 150 |
+
{system_prompt}<|im_end|>
|
| 151 |
+
<|im_start|>user
|
| 152 |
+
{user_message}<|im_end|>
|
| 153 |
+
<|im_start|>assistant
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
The model natively supports function calling / tool use — see the [base model card](https://huggingface.co/InternScience/Agents-A1) for agentic and tool-calling details.
|
| 157 |
|
| 158 |
## Metrics
|
| 159 |
|
| 160 |
Hardware and runtime profile:
|
| 161 |
|
| 162 |
+
- **GPU:** single NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, full offload
|
| 163 |
+
- **`llama.cpp` flags:** `-ngl 99 -sm none -fa on -p 512 -n 128 -b 4096 -ub 512 -r 3`
|
| 164 |
+
- **PPL:** `llama-perplexity`, context 2048, 64 rendered eval conversations, 3 chunks
|
| 165 |
+
- **KLD:** approximate `KL(P_BF16 || P_quant)` over top-64 next-token distributions on 32 prompts
|
| 166 |
|
| 167 |
+
The PPL eval is intentionally small, so treat PPL deltas as directional. KLD and top-1 agreement are the more useful quant-to-BF16 quality signals here.
|
| 168 |
|
| 169 |
| Model | Size GB | Prompt tok/s | Gen tok/s | PPL | PPL delta | KLD mean | KLD p95 | Top-1 match |
|
| 170 |
|---|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
|
| 179 |
|
| 180 |
### Charts
|
| 181 |
|
| 182 |
+

|
| 183 |
+
|
| 184 |
+

|
| 185 |
|
| 186 |

|
| 187 |
|
| 188 |

|
| 189 |
|
|
|
|
|
|
|
| 190 |
Raw metric files are in `metrics/`; KLD reports, checksums, and the MTP audit are in `reports/`.
|
| 191 |
|
| 192 |
+
## MTP (Multi-Token Prediction) Q4 variants
|
| 193 |
|
| 194 |
+
The upstream Agents-A1 checkpoint used for the first GGUF release advertises MTP in config but does not ship `mtp.*` / `blk.40.*` tensors. The two MTP Q4 variants here graft in the Agents-A1 MTPLX MTP sidecar from [`wang-yang/Agents-A1-MTPLX-Q4`](https://huggingface.co/wang-yang/Agents-A1-MTPLX-Q4), then convert it with `llama.cpp`'s Qwen3.5-MoE MTP path. The dense MTP block is preserved at Q6_K while the model body is quantized to IQ4_XS or Q4_K_M.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 195 |
|
| 196 |
Structural checks for both MTP GGUFs:
|
| 197 |
|
|
|
|
| 203 |
| `blk.40.*` MTP tensors | 20 |
|
| 204 |
| `blk.40.nextn.*` tensors | 4 |
|
| 205 |
|
| 206 |
+
Single-user serving profile: one RTX PRO 6000 Blackwell Max-Q 96 GB GPU, `PARALLEL=1`, `CTX_SIZE=8192`, streaming chat completions, 12 requests, 128 max tokens, `temperature=0`, `top_p=1`.
|
|
|
|
|
|
|
| 207 |
|
| 208 |
| Quant | Mode | Aggregate tok/s | Speedup vs target-only | Draft acceptance | Mean accepted length | Acceptance by position |
|
| 209 |
|---|---:|---:|---:|---:|---:|---|
|
| 210 |
+
| IQ4_XS-MTP | target-only | 224.59 | 1.00× | n/a | n/a | n/a |
|
| 211 |
+
| IQ4_XS-MTP | `draft-mtp`, `n_max=2` | 275.03 | 1.22× | 76.51% | 2.52 | `(0.830, 0.692)` |
|
| 212 |
+
| IQ4_XS-MTP | `draft-mtp`, `n_max=1` | 259.58 | 1.16× | 86.47% | 1.86 | `(0.865)` |
|
| 213 |
+
| Q4_K_M-MTP | target-only | 230.48 | 1.00× | n/a | n/a | n/a |
|
| 214 |
+
| Q4_K_M-MTP | `draft-mtp`, `n_max=2` | 273.80 | 1.19× | 77.18% | 2.53 | `(0.847, 0.687)` |
|
| 215 |
+
| Q4_K_M-MTP | `draft-mtp`, `n_max=1` | 264.88 | 1.15× | 91.46% | 1.91 | `(0.915)` |
|
| 216 |
+
|
| 217 |
+

|
| 218 |
|
| 219 |
+
Recommended low-latency / single-user throughput profile: `SPEC_DRAFT_N_MAX=2`. Recommended high-acceptance fallback: `SPEC_DRAFT_N_MAX=1`.
|
|
|
|
| 220 |
|
| 221 |
+
Detailed MTP evidence:
|
| 222 |
|
| 223 |
- `reports/agents-a1-mtp-q4-profile-summary.md`
|
| 224 |
- `reports/agents-a1-mtp-q4-profile-summary.json`
|
| 225 |
+
- `reports/mtp-weights-audit.json` (audit of the config-only upstream snapshot)
|
| 226 |
- `configs/mtp_profiles.yaml`
|
| 227 |
|
| 228 |
+
## Provenance & credits
|
| 229 |
|
| 230 |
+
- **Base model:** [`InternScience/Agents-A1`](https://huggingface.co/InternScience/Agents-A1) — *Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent* ([arXiv:2606.30616](https://arxiv.org/abs/2606.30616))
|
| 231 |
+
- **MTP source:** [`wang-yang/Agents-A1-MTPLX-Q4`](https://huggingface.co/wang-yang/Agents-A1-MTPLX-Q4) sidecar, grafted onto the base checkpoint
|
| 232 |
+
- **Quantization source:** BF16 GGUF converted from the Hugging Face checkpoint
|
| 233 |
+
- **Calibration:** coding/instruction-chat data rendered with the model chat template (imatrix)
|
| 234 |
+
- **Quantizer:** patched `llama.cpp` with Qwen3.5-MoE and NVFP4 support
|
| 235 |
+
- **License:** Apache-2.0, inherited from the base model
|
| 236 |
|
| 237 |
+
## Citation
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 238 |
|
| 239 |
+
If you use these quantizations, please cite the base model:
|
| 240 |
|
| 241 |
+
```bibtex
|
| 242 |
+
@article{agentsa1_2026,
|
| 243 |
+
title = {Agents-A1: Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent},
|
| 244 |
+
author = {InternScience},
|
| 245 |
+
journal = {arXiv preprint arXiv:2606.30616},
|
| 246 |
+
year = {2026}
|
| 247 |
+
}
|
|
|
|
| 248 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
metrics/chart-kld-mean.png
CHANGED
|

|
Git LFS Details
|
metrics/{chart-size-vs-generation.png → chart-mtp-speedup.png}
RENAMED
|
File without changes
|
metrics/chart-ppl-delta.png
CHANGED
|

|
Git LFS Details
|
metrics/chart-quality-vs-size.png
CHANGED
|

|
Git LFS Details
|
metrics/chart-throughput.png
ADDED

|
Git LFS Details
|